2025年,大语言模型(LLM)社区呈现出两条清晰的发展主线:
- Test-Time Scaling:不依赖于单纯增大模型参数量,而是通过让模型“多思考几次”、“多尝试几遍”来提升性能。
- Agent化:赋予模型使用工具的能力,使其能在特定环境中通过迭代推理“滚雪球”式地完成任务。
然而,一个普遍的疑问也随之浮现——“使用更多智能体就一定能获得更好的结果吗?” 此前,业界缺乏一个定量的答案。
近期,Google发布的两篇重要论文,首次将Agent Scaling问题拆解为可预测、可度量的科学问题,为上述疑问提供了系统的解答。
  |
论文 |
核心命题 |
关键词 |
|
Budget-Aware Tool-Use Enables Effective Agent Scaling |
在“工具调用预算”的约束下,如何让智能体花得更少、做得更对? |
预算感知、工具效率 |
|
Towards a Science of Scaling Agent Systems |
对于给定任务,能否预先计算出最优的智能体数量与协调结构? |
协调拓扑、任务可分解性 |
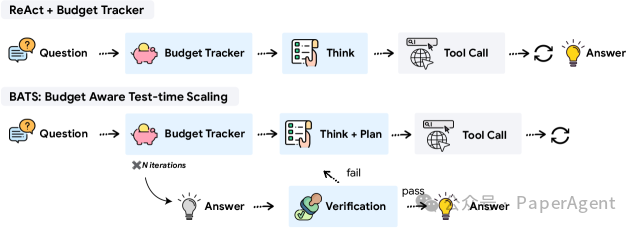
示意图 1:Budget Tracker 作为轻量级插件,可同时服务于标准 ReAct(上)与高级框架 BATS(下)
核心痛点
- 简单“增加预算”不等于提升性能:缺乏预算感知的智能体,其性能会很快触及天花板。
- 工具调用成本不限于Token:搜索、网页浏览、API调用等都涉及真实的经济成本,需要一个统一的度量标准。
解法一:即插即用的 Budget Tracker

- 机制:在每一轮推理中,将“剩余预算/已用预算”直接写入提示词(Prompt),无需额外训练。
- 策略:根据预算高低,自动在“广泛探索”和“精准利用”两种策略间切换。
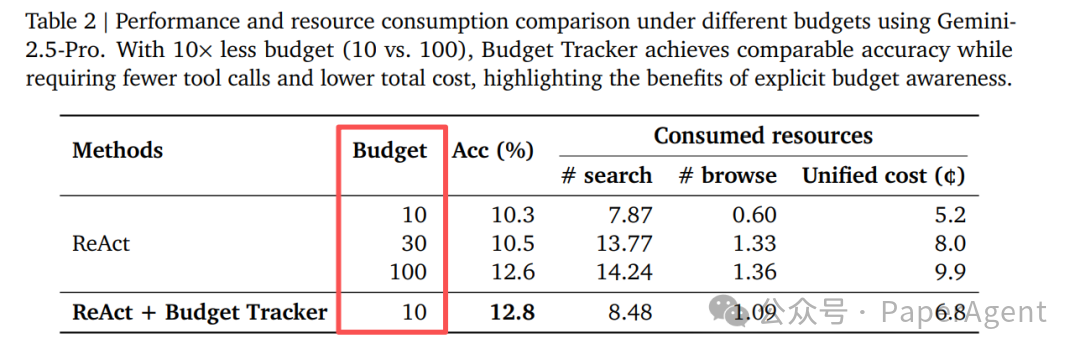
实验效果(基于 BrowseComp 基准,使用 Gemini-2.5-Pro 模型):
- 当预算从10增加到100时,使用Budget Tracker的智能体性能持续提升;而无Tracker的基线模型在预算达到100时性能就已饱和。
- 在达到相同任务精度的情况下,总体成本降低了31%(其中搜索成本降低40%,浏览成本降低21%)。
解法二:BATS 框架(Budget-Aware Test-time Scaling)
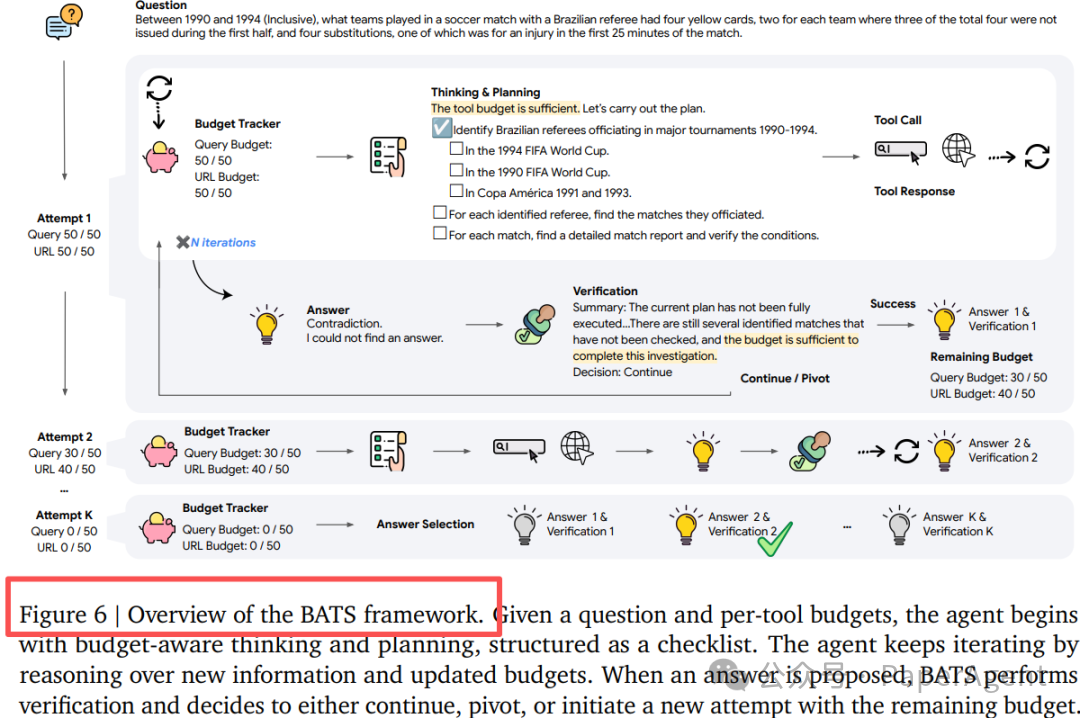 |
模块 |
预算感知做法 |
| 规划 |
将“剩余工具调用次数”写入任务检查清单,动态决定是“深入挖掘当前线索”还是“切换探索路径”。 |
| 自检 |
提出初步答案后,利用剩余预算进行反向验证;若验证不通过,则总结失败原因,压缩进记忆后开启新的求解路径。 |
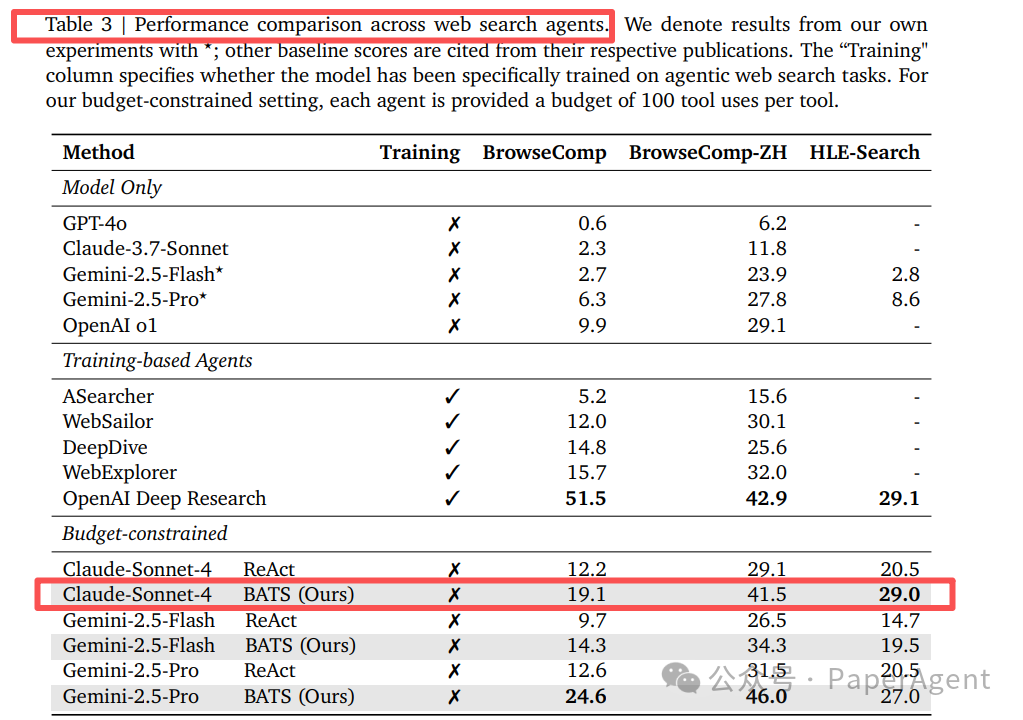
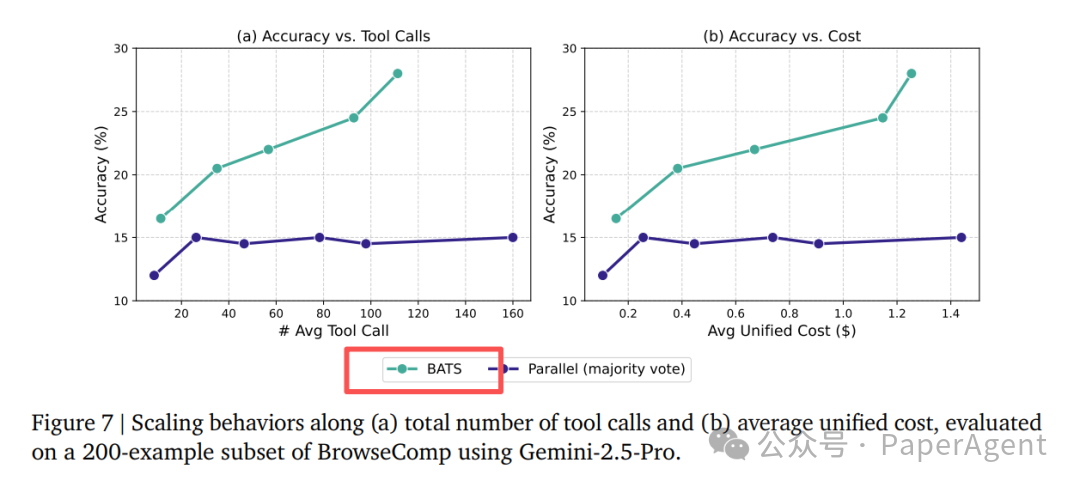
结果:在三个信息检索基准测试上,BATS框架的性能一致优于简单的并行或串行扩展方法,并且实际花费的成本更低。
图 7:左图展示了工具调用次数与性能的关系曲线,右图展示了统一成本度量下的性能曲线
Scaling 的科学:寻找多智能体协作的“盈亏平衡点”
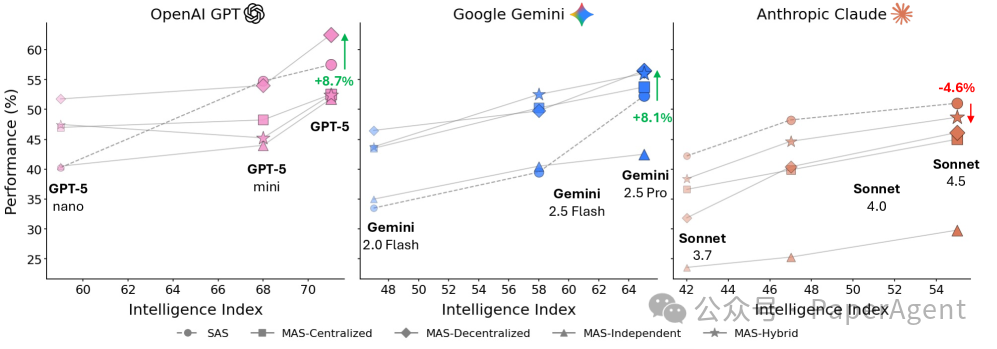
图 1:跨模型家族的 Intelligence Index 与平均性能关系
实验设计:180种配置的全面横评
 |
维度 |
取值 |
| 任务 |
4个真实的智能体基准测试(涵盖金融分析、网页交互、Minecraft游戏规划、办公自动化流程) |
| 模型 |
3大模型家族 × 3种尺寸 = 9款不同能力的LLM |
| 架构 |
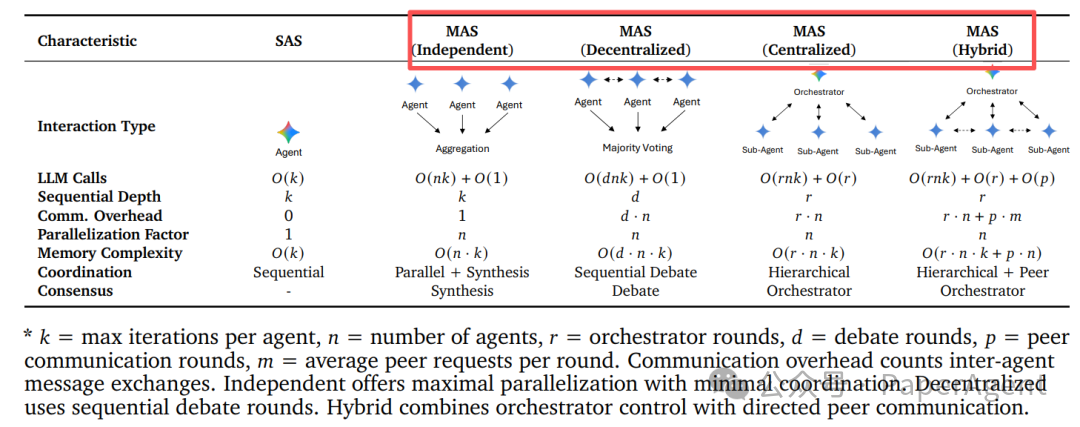
SAS(单智能体) + 4类MAS(多智能体系统:独立式 / 集中式 / 去中心式 / 混合式) |
| 总配置 |
共计180组,所有实验均匹配相同的Token预算,以排除实现差异的干扰。 |
三条核心发现(“铁律”)
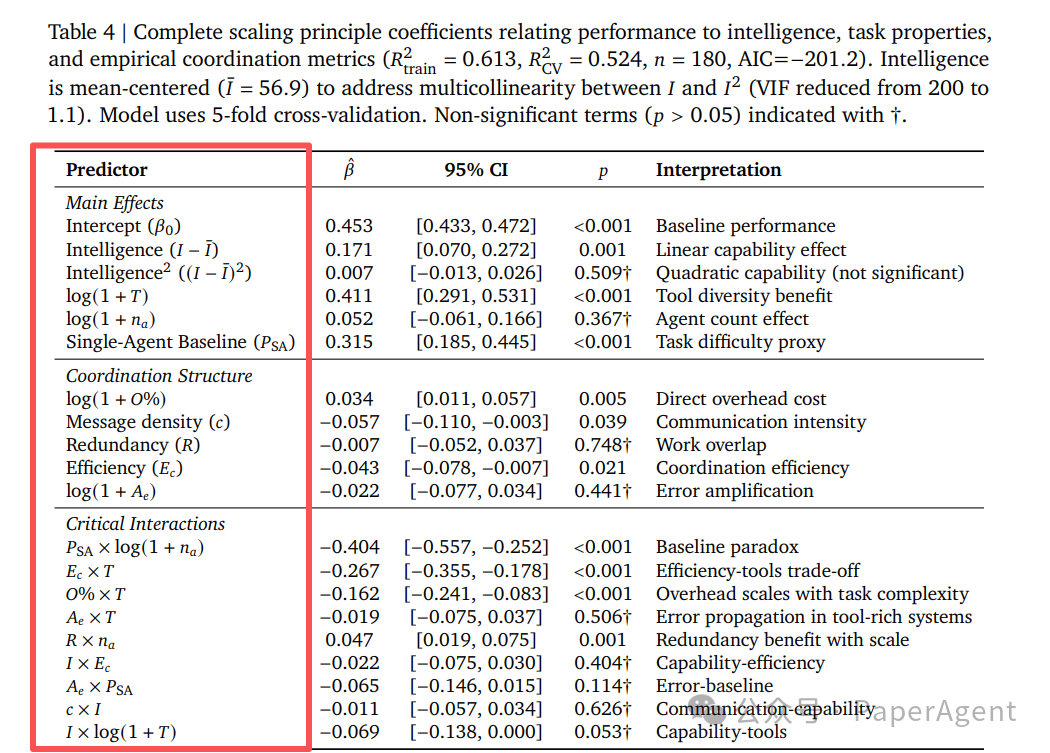
表4 将性能与智能水平、任务属性以及实测协调指标相关联的完整scaling原理系数表
| 铁律 |
数据支撑 |
业务启示 |
| 工具-协调权衡 |
系数 β = -0.267 (p<0.001) |
当可用工具超过8个时,多智能体系统的协调开销会指数级增长,需谨慎采用。 |
| 能力饱和点 |
单智能体基线性能 > 45% 后,增加智能体数量收益为负 |
优先提升单兵作战能力,再考虑团队协作。 |
| 错误放大效应 |
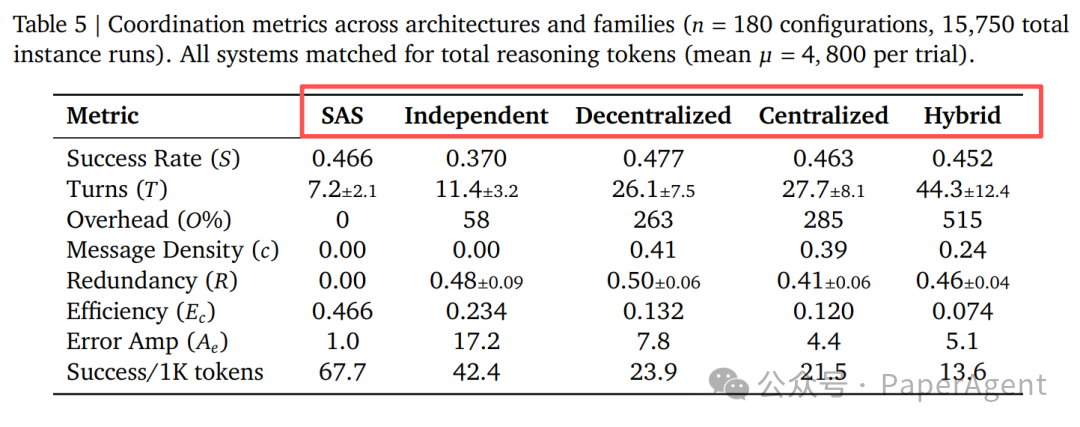
独立式架构将错误放大17.2倍;集中式架构可将其压缩至4.4倍。 |
缺乏有效校验的“裸并行”等于自爆。 |
表 5:不同架构的协调指标对比
构建定量预测模型
研究团队基于20个可观测特征(如工具数量、单智能体基线性能、协调效率、冗余度、错误放大系数等)拟合了一个混合效应模型:
- 交叉验证的 R² = 0.524,平均绝对误差 MAE = 0.089。
- 在未参与训练的测试配置中,87% 的案例被成功预测出最优架构。
在线计算器思路:输入任务的客观复杂度(T)、单智能体基线性能(PSA)、模型智能指数(Intelligence Index),即可输出期望性能最高的推荐架构。
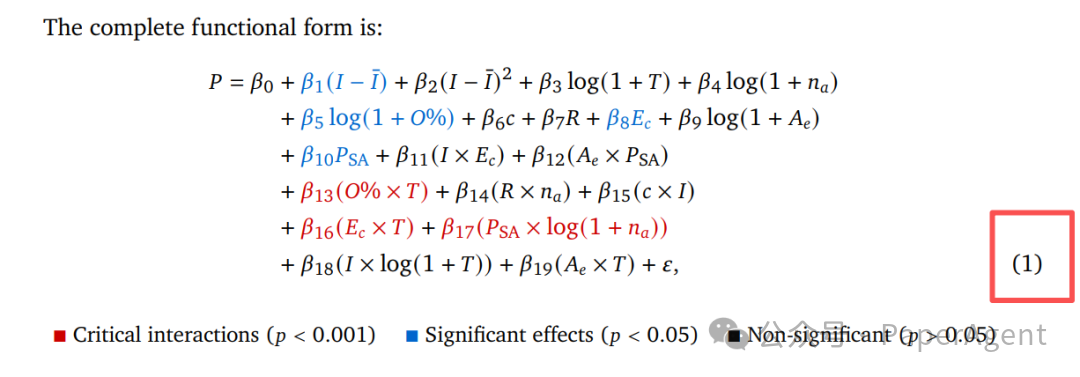
整套计算器的完整表达式
总结:Agent Scaling 进入“可预测”时代
这两篇论文系统性地将“控制成本”和“增加智能体”这两个核心扩展维度,转化为了可度量、可预测的科学问题。这意味着:
- 不再需要凭经验猜测是否应该部署多智能体系统。
- 不再盲目地为智能体分配无限的资源预算。
- 不再将“增加智能体数量”视为解决一切问题的万能钥匙。
对于2025年的AI Agents技术开发者而言,终于有可靠的数学公式和量化模型作为决策依据——这无疑是推动领域走向成熟的关键一步。
论文链接:
|  发表于 2025-12-23 23:59:41
|
查看: 378|
回复: 0
发表于 2025-12-23 23:59:41
|
查看: 378|
回复: 0
