随着企业对数据分析实时性、交互式体验以及统一查询能力的要求日益提升,传统基于Hadoop生态的数据湖架构面临诸多挑战。2025年10月正式发布的 StarRocks 4.0,引入了原生存算分离架构,并深度集成对象存储,标志其从一个高性能MPP分析引擎,演进为现代化的湖仓一体平台。本文将系统介绍如何基于StarRocks 4.0重构数据湖架构。
一、典型场景:从“T+1报表”到“分钟级实时看板”
场景背景
某电商平台日均产生50TB用户行为日志,原有架构如下:
- 日志写入 Kafka → Flink 实时清洗 → 写入 HDFS(Parquet格式)。
- 每日凌晨通过 Hive 执行 T+1 聚合,生成报表。
- BI 工具连接 Presto 查询,平均响应时间 >15 秒。
核心痛点:
- 数据延迟高,无法支持运营实时决策与风控拦截。
- 查询性能不稳定,大促期间多套系统资源争抢严重。
- 运维复杂,需维护 HDFS、Hive、Presto 等多套系统,运维挑战巨大。
StarRocks 4.0 解决方案
利用其 存算分离、对象存储直读 与 异步物化视图 能力,构建新架构:
- 原始日志经流处理引擎清洗后,直接写入S3,摒弃了中间的HDFS层。
- StarRocks 纯计算节点(CN)按需弹性伸缩,直接读取S3上的Parquet/ORC文件。
- 通过创建异步物化视图自动聚合数据,为BI看板提供秒级查询支撑。
实施效果:端到端数据延迟从24小时缩短至5分钟,BI查询P95响应时间<2秒,整体运维成本下降约60%。
二、实践步骤:四步构建 StarRocks 4.0 数据湖架构
第一步:部署 StarRocks 4.0 存算分离集群
StarRocks 4.0 的架构核心组件包括:
- FE:负责元数据管理与查询规划,无状态且支持高可用。
- CN:纯计算节点,无本地存储,所有数据均从对象存储(如 AWS S3、阿里云 OSS)读取。
- 共享对象存储:作为统一的数据底座。
部署时,只需启动独立的 starrocks-compute-node 进程并将其注册到FE,即可加入计算资源池。FE会自动将查询调度至CN执行,无需再为外部表查询部署传统的BE节点。
第二步:创建 External Catalog 直连数据湖
StarRocks 4.0 支持通过 External Catalog 直接查询数据湖中的表,无缝对接 Hive、Iceberg、Hudi 及 Delta Lake 等多种格式,这为构建统一的数据分析平台提供了便利,你可以在云栈社区的大数据专题找到更多关于数据湖技术的深度讨论。

第三步:构建异步物化视图加速查询
可以在 External Table 上创建异步物化视图,并设置增量刷新策略。物化视图的数据会自动持久化到 StarRocks 内部表中(底层仍存储于对象存储),查询时优化器会自动路由至最优的物化视图,对业务透明。

第四步:弹性扩缩容与成本控制
- 弹性伸缩:可根据查询负载,随时启停CN节点,甚至在业务低峰期缩容至0节点。
- 冷热分层:高频查询的热数据可缓存在CN本地SSD,冷数据则直读对象存储。
- 成本解耦:计算资源(CN)与存储资源(S3)完全分离,实现真正的“按使用量付费”。
三、避坑指南:StarRocks 4.0 存算分离实战雷区
坑 1:对象存储网络延迟导致查询慢
- 现象:首次查询Parquet文件耗时过长(>30秒)。
- 原因:S3元数据请求开销大,以及大量小文件引发的随机I/O。
- 对策:
- 在数据写入阶段(如通过Flink)合并小文件,设置合理的滚动策略。
- 启用StarRocks 4.0新增的元数据缓存功能,缓存Parquet文件的Footer信息。

坑 2:物化视图刷新失败未告警
- 现象:物化视图数据陈旧,但未收到失败通知。
- 对策:
- 定期监控系统表
information_schema.task_runs,检查刷新任务状态。
- 在创建物化视图时,配置合理的失败重试策略。

坑 3:CN 节点资源不足引发 OOM
- 原因:复杂查询需全表扫描S3上的大量数据,导致内存溢出。
- 对策:
- 为CN节点合理设置
mem_limit 和查询超时时间 query_timeout。
- 启用 Spill to Disk 功能(自2.5版本引入,4.0优化),将中间结果落盘,避免OOM。

四、性能优化:榨干 StarRocks 4.0 的每一滴性能
1. 文件格式优化
- 优先选用 Parquet 格式,并采用 ZSTD 压缩算法,相比Snappy更能节省网络带宽。
- 确保数据写入时保留列统计信息(如min/max值),以利于StarRocks进行高效的列裁剪和谓词下推。
2. 智能缓存策略
- 元数据缓存:默认部分开启,可显著减少对对象存储的元数据请求次数。
- 数据块缓存:对于热点数据,可启用Beta版的块缓存功能,将其缓存在CN本地NVMe磁盘。
3. 查询路由优化
- 利用 Query Plan Cache 避免相同SQL的重复解析开销。
- 将高频查询使用的小维度表,通过
CREATE TABLE AS SELECT 导入为Internal Table,获得更优的查询性能。
4. 资源隔离
- 使用 Resource Group 功能(3.0引入,4.0增强)为不同业务线分配独立的CPU、内存配额,实现资源隔离与保障。
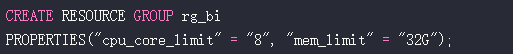
五、未来展望:StarRocks 如何定义下一代湖仓?
StarRocks 4.0 只是一个起点。根据官方路线图,未来将重点推进:
- 统一Catalog层:支持跨Iceberg、Hudi、Delta Lake的ACID事务联合查询。
- Serverless模式:提供完全托管的计算服务,实现秒级启动与按查询付费。
- AI增强优化器:基于历史负载智能推荐物化视图与索引。
- 向量化S3读取引擎:进一步降低I/O延迟,逼近本地存储性能。
最终目标是让数据分析师和开发者能够“只关心SQL逻辑,而无需担忧底层架构的复杂性”,这一理念与现代化云原生应用追求的效率与简洁性不谋而合。
结语
存算分离不仅是技术趋势,更是应对数据量激增与成本压力的必然选择。StarRocks 4.0 以其极简的架构、极致的性能与极致的弹性,为企业提供了一条向现代化湖仓一体架构平滑演进的清晰路径。如果你正在为现有数据湖方案的延迟、复杂度和成本问题寻找破局点,StarRocks 4.0 值得深入探索。 |  发表于 2025-12-24 00:41:11
|
查看: 309|
回复: 0
发表于 2025-12-24 00:41:11
|
查看: 309|
回复: 0
