本文基于对Linux内核补丁的解读,详细介绍了字节队列限制(Byte Queue Limits, BQL) 这一网络特性。
与上一版本的更改
- 基于 3.2 版本进行变基操作。
- 添加了
CONFIG_BQL 和 CONFIG_DQL 配置项。
- 在
struct dql 结构体中添加了一些缓存对齐操作,将只读元素和可写元素分开,并将在传输时写入的元素与在传输完成时写入的元素分开(由 Eric 建议)。
- 将添加
xps_queue_release 操作拆分成一个单独的补丁。
- 进行了一些小的性能优化,在一些条件判断中使用
likely 和 unlikely 宏。
- 清理了一些用于 bql 的“显示”函数(由 Ben 指出)。
- 修改
netdev_tx_completed_queue 函数,先检查 xoff 状态,再检查可用性,然后再次检查 xoff 状态。这样做是为了防止与 netdev_sent_queue 函数产生潜在的竞态条件(如 Ben 所指出)。
- 进行了更多测试,试图评估在传输路径中使用 BQL 的开销。我发现启用 BQL 时,在 CPU 利用率与最大 pps(每秒包数)方面,观察到约 1–3% 的性能下降。任何能进一步降低此开销的建议都将不胜感激!
- 在下面的测试结果中添加了高优先级与低优先级流量的测试。
什么是BQL?
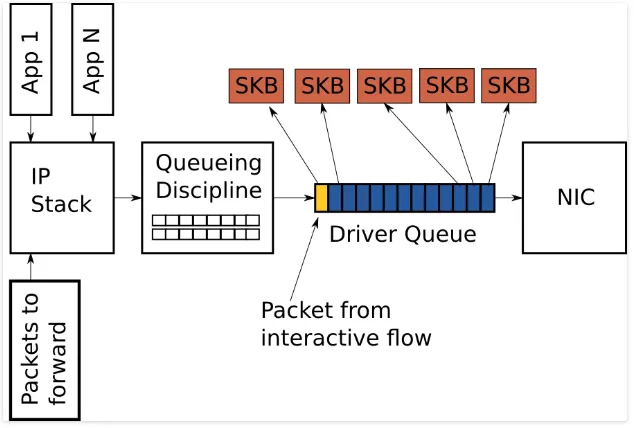
此补丁系列为网卡(NIC)的发送(TX)队列实现了字节队列限制(bql: byte queue limits)。
所谓字节队列限制,是一种通过字节数(而非传统包数或描述符数)来限制 网卡(NIC)硬件发送队列大小的机制。其设计目标是:在不牺牲吞吐量的前提下,减少因硬件中过度排队(即“缓冲膨胀”,bufferbloat)导致的延迟(特别是队首阻塞,HOL blocking)。
硬件队列限制通常以硬件描述符(descriptor)数量来表示,而每个描述符所承载的数据大小是可变的。例如,在 e1000 网卡上,单个描述符大小可能从 64 字节(普通帧)到 4 KB(启用 TSO 时)不等。这种巨大波动使得难以选定一个固定的队列长度,既能避免发送饥饿(starvation),又能实现最低延迟。
BQL 的目标是:将队列限制动态设定为防止连续两次发送之间发生饥饿所需的最小字节数。而两次发送之间的延迟在系统中是变化的——它取决于中断频率、NAPI 轮询延迟、排队规则(qdisc)的调度策略、锁竞争等多种因素。因此我们提出,字节队列限制应是动态自适应的,能根据系统实际网络栈延迟自动调整;而且 BQL 无需预设链路速率作为输入参数,它应能自动适配任意(甚至动态变化的)链路速度。
实现概览
实现此功能的补丁如下:
- 动态队列限制(dql)库:它提供了通用的排队算法。
- 对 netdev 的更改:使用
dlq 来支持字节队列限制。
- 驱动程序的适配:在驱动程序中添加对字节队列限制的支持。
性能基准测试
下面的基准测试结果展示了 BQL 的效果。
1. 高优先级与低优先级流量
在这个测试中,启动了 100 个 netperf TCP_STREAM 测试以使链路饱和。同时,运行一个设置了高优先级的 netperf TCP_RR 测试实例。排队规则使用 pfifo_fast,网卡为 e1000,其 TX 环大小设置为 1024。下面列出了高优先级 RR 测试的每秒事务数(tps)。
- 未启用 BQL,启用 TSO:队列中有 3000 - 3200K 字节,tps 为 36。
- 启用 BQL,启用 TSO:队列中有 156 - 194K 字节,tps 为 535。
- 未启用 BQL,禁用 TSO:队列中有 453 - 454K 字节,tps 为 234。
- 启用 BQL,禁用 TSO:队列中有 66K 字节,tps 为 914。
2. 不同的 RR 大小
这些测试运行了 200 个 netperf RR 测试流。结果展示了队列长度的减少,同时也说明了使用 BQL 带来的开销(在小 RR 大小的情况下)。
-
RR 大小为 140000:
- 启用 BQL:队列中有 80 - 215K 字节,tps 为 856,CPU 使用率为 3.26%。
- 未启用 BQL:队列中有 2700 - 2930K 字节,tps 为 854,CPU 使用率为 3.71%。
-
RR 大小为 14000:
- 启用 BQL:队列中有 25 - 55K 字节,tps 为 8500。
- 未启用 BQL:队列中有 1500 - 1622K 字节,tps 为 8523,CPU 使用率为 4.53%。
-
RR 大小为 1400:
- 启用 BQL:队列中有 20 - 38K 字节,tps 为 86582,CPU 使用率为 7.38%。
- 未启用 BQL:队列中有 29 - 117K 字节,tps 为 85738,CPU 使用率为 7.67%。
-
RR 大小为 140:
- 启用 BQL:队列中有 1 - 10K 字节,tps 为 320540,CPU 使用率为 34.6%。
- 未启用 BQL:队列中有 1 - 13K 字节,tps 为 323158,CPU 使用率为 37.16%。
-
RR 大小为 1:
- 启用 BQL:队列中有 0 - 3K 字节,tps 为 338811,CPU 使用率为 41.41%。
- 未启用 BQL:队列中有 0 - 3K 字节,tps 为 339947,CPU 使用率为 42.36%。
结论
从测试数据可见,网卡中的排队积压最高可降低 90% 以上;相应地,在存在大量低优先级吞吐型流量的场景下,高优先级数据包的延迟亦可降低 90% 以上。
由于 BQL 的计数功能存在于每个数据包的传输路径中,并且重新计算字节限制的函数在每次传输完成时运行,使用 BQL 会带来一些开销。测试表明,在网卡驱动层面,启用BQL导致的CPU利用率和最大每秒包数(pps)开销大约在 1% 到 3% 之间。
|  发表于 2025-12-24 02:29:51
|
查看: 270|
回复: 0
发表于 2025-12-24 02:29:51
|
查看: 270|
回复: 0
