在大语言模型(LLM)的评估实践中,评测者顺序影响判断结果是一个已被系统性验证的现象,这通常被称为位置偏差或顺序偏差。
背景
在基于pairwise或listwise的“以LLM作为评判者”的评测中,常见的提示词模板是:给定问题Q,回答A……,回答B……,请判断哪个更好。
大量实证研究发现:
- 排在前面的回答更容易被判定为更好。
- 即使两个回答质量接近,甚至后者更优,模型仍倾向于选择前者。
这不是偶然的噪声,而是一种稳定、可复现的系统性偏差。
为什么大模型会产生位置偏差?
1. 自回归模型的条件生成机制
以GPT为代表的大语言模型是自回归模型,其判断过程实质上是基于前文(包括问题、选项A和选项B)来生成后续文本(即判断结果),而非对A和B进行真正“对称”的比较。
当A在前、B在后时:
- A的内容更早进入模型上下文。
- A的内容会成为理解B的“条件上下文”。
- 模型在阅读B时,可能已经形成了对A的隐含偏好。
这在概率建模上是非交换的,即交换A和B的顺序可能会改变最终的条件概率分布。
2. 训练数据诱导的先验偏好
在模型的指令微调与人类反馈强化学习训练过程中:
- 模型大量接触“示例在前,评价或解释在后”的数据模式。
- 排在前面的答案往往被模型潜意识地当作“参考解”或“主答案”。
- 后续出现的文本则更容易被理解为补充或修正。
研究论文明确指出:模型并未被训练为一个“顺序无关”的比较器。
3. 注意力机制与上下文长度的非对称性
即使在Transformer架构内部:
- 长上下文中靠后的部分,其信息更容易被注意力机制压缩或摘要化。
- 后出现的回答往往被模型用来与前文进行对齐、对比,而非获得独立的、充分的评估。
这在处理长回答或多轮对话的评测场景中尤为明显。
实证研究与缓解方法
相关研究,如Zheng等人发表的《Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena》论文,通过严谨的实验量化了这种偏差。他们的做法是对同一对回答进行两次评测,仅交换其出现的顺序,然后统计模型判断的一致性。
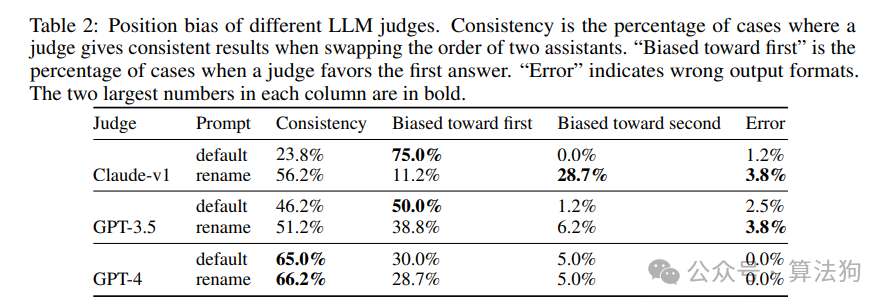
上表揭示了几个关键发现:
- 一致性低:多数模型在交换顺序后,判断结果会发生改变。例如,早期版本的Claude在默认提示词下,一致性仅为23.8%。
- 明确的方向性:当判断不一致时,模型明显偏向于选择“排在第一个的回答”,而非随机偏向。GPT-4的表现最好,但依然存在约30%的样本偏向首位。
基于这些发现,主流的人工智能评估基准(如MT-Bench、Chatbot Arena、AlpacaEval 2.0)都采用了相应的策略来缓解这一问题:
核心策略:交换位置与统计聚合
假设模型对位置存在一个系统性的偏置。通过交换A和B的顺序进行两次评测,并对两次结果进行平均或投票,可以在统计期望上抵消掉由位置带来的偏差项。
这是一种统计意义上的去偏方法。工程上的常见实践包括:
pairwise比较时,固定进行顺序交换。- 进行多次随机打乱顺序的评测。
- 结合自一致性投票。
- 与人类评测结果进行校准。
总结
以GPT为代表的大语言模型在作为评判者时,存在稳定且可复现的位置偏差,其根源在于自回归的生成机制、训练数据带来的先验以及注意力分布的非对称性。通过交换回答顺序并进行多次判断聚合,可以在统计层面有效缓解这一偏差。因此,这在当前的大模型能力评估中已成为一项标准实践,而不仅仅是一个工程技巧。 |  发表于 2025-12-24 16:27:03
|
查看: 276|
回复: 0
发表于 2025-12-24 16:27:03
|
查看: 276|
回复: 0
