在上一篇文章中,我们对Apache Doris的Partial Update功能进行了初步探索,并总结了一套与官方建议略有不同,但更贴合实际落地场景的建表方案。
《Doris 的 partial update,好使不啦?》
然而,之前的测试规模较小,属于功能验证性质,不足以支撑生产环境下的性能评估。为了真正检验Doris Partial Update在高负载场景下的稳定性,我们需要进行更大强度的压力测试。
本次测试将参考先前验证Paimon的方案,采用Flink 1.19作为数据处理引擎,Doris 2.1.11作为数据存储,模拟真实业务中高并发、无序的数据更新场景。
一、 测试方案设计
1.1 核心思路
为了充分验证Partial Update的“聚合”能力,我们模拟一个常见的数据流处理场景:将原始的宽表数据,通过预设的策略拆分为多条仅包含部分字段的“窄”数据记录。
这些“窄”数据记录将以无序的方式写入Kafka消息队列。随后,Flink作业将消费Kafka中的数据,并以最朴素的“普通写入”方式,将其灌入预先创建的Doris Partial Update表中。
最终,我们将验证Doris表是否能根据指定的Key字段,正确地将这些分散的更新“缝合”回完整的宽表记录。
1.2 数据集与拆分策略
本次测试沿用之前验证Paimon时使用的数据集,包含5个核心字段:domain, registrar, registrant_org, registrar_country, registrant_province。其中,domain字段被指定为关联所有数据的唯一键。
在写入Kafka前,原始数据将被拆分为以下四种组合:
- (
domain, registrar)
- (
domain, registrant_org)
- (
domain, registrar_country)
- (
domain, registrant_province)
拆分后的数据规模达数百万条,它们在Kafka中的形态如下图所示:
1.3 目标Doris表设计
为了清晰记录每次数据更新,并最终根据domain字段聚合出完整数据,我们设计如下Doris聚合表(Aggregate Key)。update_cnt字段用于统计每条记录经历的数据合并次数。
CREATE TABLE doris_partial_update03 (
domain varchar(500),
registrar string REPLACE_IF_NOT_NULL,
registrant_org string REPLACE_IF_NOT_NULL,
registrar_country string REPLACE_IF_NOT_NULL,
registrant_province string REPLACE_IF_NOT_NULL,
update_cnt INT SUM DEFAULT 1
)
AGGREGATE KEY(domain)
DISTRIBUTED BY HASH(domain) BUCKETS 3
二、 Flink作业实现
在实现Flink实时数据处理作业时,一个令人惊喜的发现是:相比之前通过命令行手动写入时需要设置的特殊Session参数(如enable_unique_key_partial_update),通过Flink Connector写入时,这些限制完全无需考虑。
更关键的是,Flink作业从Kafka中读取的、字段不完整的“窄”数据,无需与Doris目标表的字段一一对齐或进行复杂转换,可以直接写入。这极大地简化了Flink作业的数据流架构设计。
整个Flink Sink的配置核心是确保序列化格式与数据源匹配,下图中红框标出的format配置项前后需保持一致。
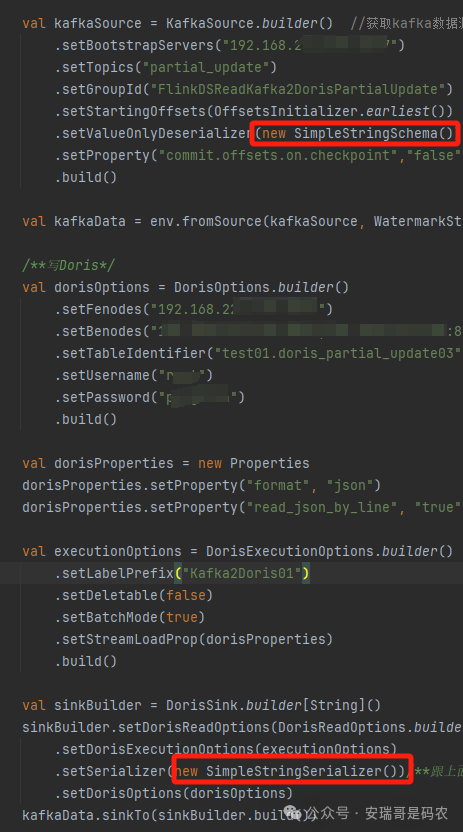
至此,编码工作基本完成。相比实现相同功能的Paimon方案,本次使用Doris的方案在编码复杂度上显著降低,过程更为简洁。
三、 测试结果验证
- 写入性能:由于数据在短时间内被一次性全量灌入,难以精确统计每秒吞吐量(QPS)。但直观感受上,写入过程流畅,未出现明显瓶颈或堆积,性能表现符合预期。
- 数据正确性:查询最终表数据,验证通过。Doris成功根据
domain字段将所有分散的更新聚合成完整的行数据,且update_cnt字段正确统计了合并次数(理论上每条记录应被更新4次),如下图所示:

四、 总结
本次压力测试表明,通过Flink将海量、无序的增量数据写入Doris Partial Update表,其门槛比预想的更低。Flink Connector的智能处理省去了繁琐的数据对齐和转换操作,使得整个大数据处理工作流的实现异常简洁。
从功能和体验上看,Doris Partial Update在此场景下的表现,相比其他同类方案,在易用性和开发效率上具有一定优势,为处理实时更新与合并场景提供了一个高效、可靠的选择。
 发表于 2025-12-24 21:08:00
|
查看: 199|
回复: 0
发表于 2025-12-24 21:08:00
|
查看: 199|
回复: 0
