Hadoop 核心组件与架构面试题
1. 集群的主要性能瓶颈
磁盘 I/O 通常是 Hadoop 集群最主要的性能瓶颈。
2. Hadoop 运行模式
- 单机模式:仅用于本地调试。
- 伪分布式模式:所有守护进程运行在单台机器上,模拟集群环境。
- 完全分布式模式:真正的生产环境部署模式,在多台机器上运行。
3. Hadoop 生态圈组件简介
Hadoop 生态系统不仅包含核心框架,还有许多辅助框架,共同构建了强大的大数据处理能力。其中,大数据 生态的常用组件包括:
- Zookeeper:分布式应用程序协调服务,用于实现配置维护、命名服务和分布式同步。
- Flume:高可用的分布式日志采集、聚合和传输系统。
- HBase:构建在 HDFS 之上的分布式、面向列的 NoSQL 数据库。
- Hive:基于 Hadoop 的数据仓库工具,可将结构化数据映射为表,并提供 SQL 查询(HQL)功能,其查询语句会被转换为 MapReduce 任务执行。
- Sqoop:用于在 Hadoop(HDFS/Hive/HBase)与关系型数据库之间进行高效数据传输的工具。
4. Hadoop 与 Hadoop 生态系统的区别
- Hadoop:狭义上指 Hadoop 框架本身,主要包括 HDFS(分布式文件系统)和 MapReduce(分布式计算框架)。
- Hadoop 生态系统:广义概念,不仅包含 Hadoop 核心框架,还包含 Zookeeper、Flume、HBase、Hive、Sqoop 等保证其高效稳定运行和功能扩展的众多辅助框架。
5. Hadoop 集群中的核心进程及其作用
- NameNode (NN):
- 作用:HDFS 的主服务器,负责管理文件系统的命名空间(元数据),包括文件树结构、文件与数据块的映射关系。元数据持久化在
fsimage(镜像文件)和 edits(编辑日志)中。
- SecondaryNameNode (SNN):
- 作用:并非 NameNode 的热备。其主要职责是定期合并
fsimage 和 edits 日志,以防 edits 文件过大,缩短 NameNode 重启时间。通常需要独立部署。
- DataNode (DN):
- 作用:负责存储实际的数据块(Block),并执行客户端的读写请求。
- ResourceManager (RM):
- 作用:YARN 的主节点,负责整个集群所有资源的统一管理和调度,接收各 NodeManager 的资源汇报,并将资源分配给各应用程序(如 MapReduce)。
- NodeManager (NM):
- 作用:YARN 的从节点,负责单个节点上的资源管理和任务(如 MapTask、ReduceTask)的具体执行。
- DFSZKFailoverController (ZKFC):
- 作用:在 HDFS 高可用(HA)方案中,负责监控 NameNode 的健康状态,并将状态信息写入 Zookeeper。它有权通过 Zookeeper 选举机制决定哪个 NameNode 应处于 Active 状态。
- JournalNode (JN):
- 作用:在 HDFS HA 方案中,用于共享存储 Active NameNode 的编辑日志(edits),供 Standby NameNode 同步使用。
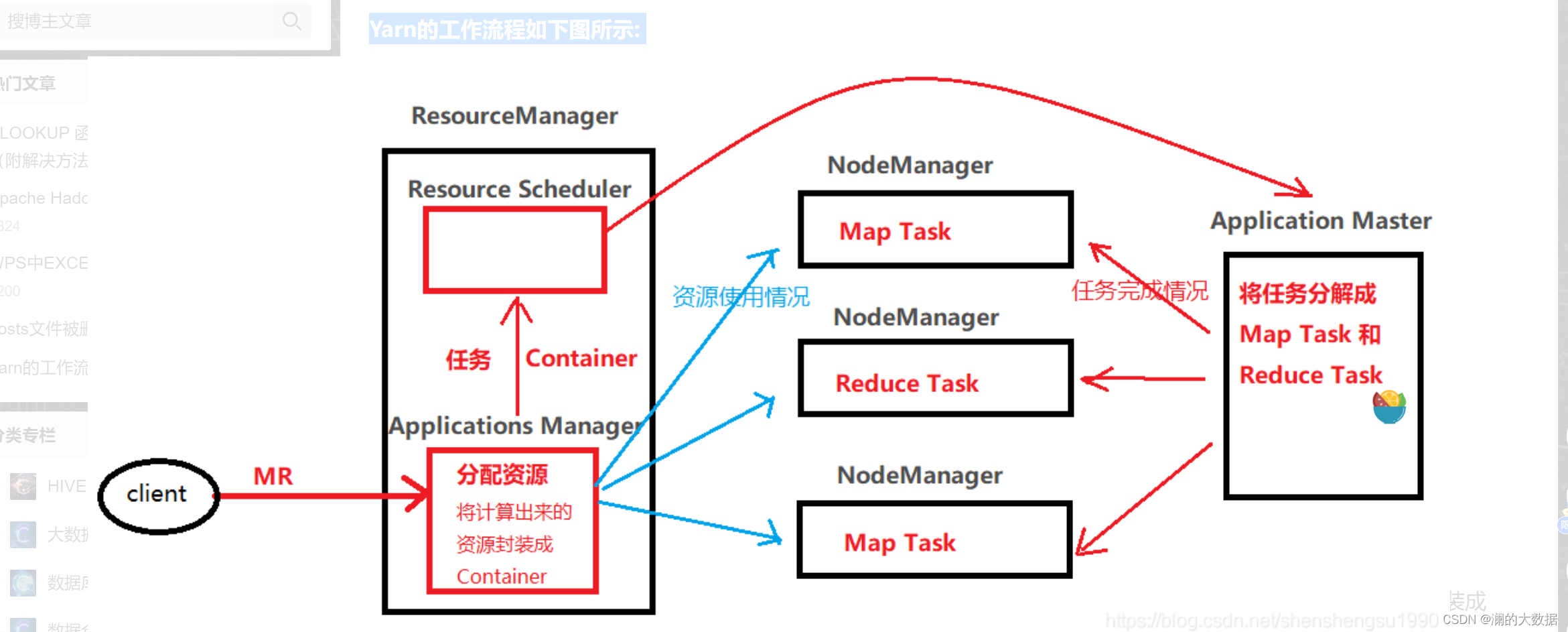
6. YARN 工作流程
YARN 的工作流程主要涉及 ResourceManager 和 NodeManager 的协作,具体如下图所示。
7. HDFS 的高可用 (HA) 机制详解
Hadoop HA 旨在消除关键组件的单点故障,主要包括 HDFS HA 和 YARN HA。
HDFS HA 通过部署两个 NameNode(一个 Active,一个 Standby)来实现。其核心要点在于:
- 元数据同步:两个 NN 内存中各有一份元数据;共享的 edits 日志存放在 JournalNode 集群中,保证只有一个 NN(Active)可以写入,但两个 NN 都能读取以同步状态。
- 状态故障转移:通过 ZKFC 模块监控 NN 健康状态,并利用 Zookeeper 进行主备选举和状态切换。
HDFS 的 HA 运行机制如下图所示。

8. YARN 的高可用 (HA) 机制
YARN 的 ResourceManager HA 同样采用主备架构。在任何时刻,只有一个 RM 处于 Active 状态,对外提供服务;一个或多个 RM 处于 Standby 状态。当 Active RM 发生故障时,可通过管理员手动触发或由内置的故障转移控制器自动触发,将某个 Standby RM 切换为 Active 状态。
HDFS 面试题总结
1. HDFS 中 Block 的默认副本数
默认保存 3 份。
2. HDFS 默认的 BlockSize
Hadoop 1.x 默认为 64MB,Hadoop 2.x 及 3.x 默认为 128MB。
3. 负责 HDFS 数据存储的组件
DataNode 负责数据块的实际存储。
4. SecondaryNameNode 的作用
辅助 NameNode,定期合并 fsimage 和 edits 日志文件,以减少 NameNode 在重启时加载元数据的时间。
5. HDFS 块大小设置的影响
HDFS 文件在物理上被切分为 Block 存储。块大小设置至关重要,需在寻址时间与数据传输时间之间取得平衡:
- 块过大:磁盘传输时间占比过高,单个 MapTask 处理时间变长,降低并行度。
- 块过小:
- 大量小文件会占用 NameNode 大量内存存储元数据。
- 寻址时间显著增加,程序效率降低。
通常,块大小(如默认的 128MB)的设定是为了让寻址时间仅占数据传输时间的很小一部分(如1%),从而最大化磁盘吞吐量。
6. Hadoop 从哪个版本开始块大小为 128MB
Hadoop 1.x 为 64MB,从 Hadoop 2.x 开始默认为 128MB。
7. HDFS 的存储机制(读写过程)
HDFS 写数据过程
- 客户端向 NameNode 发起上传请求,NN 检查目标路径合法性。
- NN 返回允许上传。
- 客户端请求为第一个 Block 分配存储的 DataNode 列表。
- NN 返回一个有序的 DN 列表(如 dn1, dn2, dn3)。
- 客户端与 DN 之间建立 Pipeline(管道),数据从客户端流向 dn1,再由 dn1 传向 dn2,dn2 传向 dn3。
- 数据以 Packet 为单位传输,每个 DN 接收后存入本地磁盘,并向下一个 DN 转发。
- 一个 Block 传输完成后,客户端继续请求 NN 分配第二个 Block 的存储位置,重复上述过程。
HDFS 读数据过程
- 客户端向 NameNode 请求下载文件,获取文件块所在的 DataNode 地址列表。
- 客户端根据网络拓扑就近选择一个 DataNode 建立连接,请求读取数据。
- DataNode 将数据以 Packet 为单位发送给客户端。
- 客户端接收数据,先在本地缓存,然后写入最终目标文件。
8. Secondary NameNode 的工作机制
- NameNode 启动与运行:启动时加载或创建 fsimage 和 edits 文件。运行时,将元数据更改操作记录到 edits 文件,并在内存中更新元数据。
- Secondary NameNode 执行 Checkpoint:
- SNN 询问 NN 是否需要执行检查点(checkpoint)。
- 如果需要,SNN 请求执行 checkpoint。
- NN 滚动当前的 edits 日志,生成新的 edits 文件。
- SNN 将 NN 上的 fsimage 和滚动前的 edits 文件拷贝到本地。
- SNN 在内存中合并这两个文件,生成新的 fsimage.ckpt。
- SNN 将新的 fsimage.ckpt 发回给 NN。
- NN 将其重命名为 fsimage,完成元数据更新。
9. NameNode 与 SecondaryNameNode 的区别与联系
- 区别:
- NameNode:管理和维护整个 HDFS 的元数据。
- SecondaryNameNode:辅助 NN,定期合并元数据镜像和编辑日志,不直接处理客户端请求。
- 联系:
- SNN 上保存了与 NN 一致的 fsimage 和 edits 副本。
- 当 NN 故障且无其他高可用备份时,可利用 SNN 合并后的元数据进行一定程度的恢复(可能会丢失部分最新 edits)。
10. HDFS 的组成架构
主要由四部分组成:
- Client(客户端):负责文件切分、与 NN 交互获取元数据、与 DN 交互读写数据、管理 HDFS。
- NameNode(NN):管理者。管理命名空间、数据块映射信息、副本策略,处理客户端请求。
- DataNode(DN):执行者。存储实际数据块,执行数据块的读写操作。
- Secondary NameNode(SNN):辅助者。协助 NN 进行元数据镜像的合并。
11. HDFS HA 中 ZKFC 的工作机制
ZKFailoverController 是 HA 方案中的关键组件:
- 健康监测:周期性向监控的 NameNode 发送健康探测命令。
- 会话管理与 Master 选举:
- 通过 Zookeeper 维持一个打开的会话。
- 在 ZK 上创建临时顺序节点(EPHEMERAL_SEQUENTIAL Znode)来代表 Active 锁。
- 哪个 NN 的 ZKFC 抢到锁,其对应的 NN 就进入 Active 状态。
- 故障转移:当 Active NN 故障时,其在 ZK 上的锁节点消失,Standby NN 的 ZKFC 会尝试抢占锁,成功后触发 NN 状态切换为 Active。
MapReduce 面试题总结
1. Hadoop 序列化与自定义序列化
- 序列化/反序列化:将对象转为字节流以便存储或传输,反之则为反序列化。Hadoop 使用自研的
Writable 接口,相比 Java Serializable 更轻量高效。
- 自定义 Bean 实现序列化步骤:
- 实现
Writable 接口。
- 提供空参构造函数(反射需要)。
- 重写
write(序列化)和 readFields(反序列化)方法,且顺序必须一致。
- 若需要作为 Key 传输,还需实现
Comparable 接口以支持 Shuffle 过程中的排序。
- 切片大小计算:
splitSize = max{minSize, min{maxSize, blockSize}}。默认情况下 minSize=1,maxSize=Long.MAX_VALUE,因此 splitSize = blockSize。
- 切片过程:按文件逐个处理。对每个文件,按照
splitSize 进行逻辑切片。每次切片时,判断剩余部分是否大于 splitSize 的 1.1 倍,若不大于,则不再切片,剩余部分划入最后一个切片。
- 结果:切片信息(元数据)写入切片规划文件,MapReduce 框架根据该文件决定启动的 MapTask 数量。
InputSplit 是 MapReduce 对输入数据的逻辑划分,它记录了分片的元数据(如起始偏移量、长度、所在主机列表等),本身并不存储数据。一个 InputSplit 对应一个 MapTask 的输入。
4. 如何决定一个 Job 的 Map 和 Reduce 数量?
- Map 数量:由输入数据的切片(InputSplit)个数决定。
- Reduce 数量:可通过
job.setNumReduceTasks(int n) 显式设置。若不设置,默认为 1。
5. MapTask 的个数由什么决定?
由客户端提交 Job 时,根据输入数据计算出的 InputSplit 个数 决定。
6. MapTask 和 ReduceTask 工作机制(MapReduce 工作原理)
MapTask 阶段
- Read 阶段:通过
RecordReader 从 InputSplit 中解析出一个个键值对(K/V)。
- Map 阶段:调用用户编写的
map() 函数处理 K/V,输出新的中间 K/V。
- Collect 阶段:输出 K/V 时,先经过
Partitioner 计算分区号,然后写入一个环形内存缓冲区。
- Spill 阶段:缓冲区达到阈值(默认80%)后,后台线程会将数据排序后溢写(Spill)到本地磁盘,生成临时文件。可在此阶段执行可选的
combine 操作。
- Merge 阶段:所有数据处理完毕后,对所有临时文件进行一次合并,生成一个分区且区内有序的数据文件。
ReduceTask 阶段
- Copy 阶段:从各个 MapTask 的输出文件中,远程拷贝属于自己分区的数据。
- Merge 阶段:边拷贝边合并,防止内存或磁盘文件过多。
- Sort 阶段:对合并后的数据进行一次全局归并排序(因为 Map 端输出已局部有序)。
- Reduce 阶段:将排序后的数据分组,调用用户编写的
reduce() 函数处理,并将结果写入 HDFS。
7. MapReduce 中的排序及发生阶段
- 排序类型:
- 部分排序:每个 MapTask 和 ReduceTask 的输出文件内部有序。
- 全排序:全局输出结果有序。通常需要自定义分区,并结合抽样等手段实现。
- 辅助排序(二次排序):在 Reduce 阶段对 Key 相同的数据,再按另一个条件对 Value 进行排序。需自定义
WritableComparable 和 GroupingComparator。
- 排序发生阶段:
- Map 端:发生在 Spill 阶段,对缓冲区数据进行快速排序。
- Reduce 端:发生在 Merge 阶段,对来自不同 Map 的数据进行归并排序。
8. Shuffle 阶段工作流程与优化
- 流程:指 Map 输出到 Reduce 输入之间的过程。核心包括:Map 端的 Partition、Sort、Spill、Merge,以及 Reduce 端的 Copy、Merge、Sort。
- 优化:
- 增加 Combiner 减少网络 I/O。
- 对 Map 输出进行压缩(如 Snappy、LZO)。
- 合理调整缓冲区大小 (
io.sort.mb),减少 Spill 次数。
- 调整 Merge 因子 (
io.sort.factor),优化合并效率。
9. Combiner 的作用、使用场景与限制
- 作用:在 Map 端对输出进行局部聚合,减少 Map 到 Reduce 的网络传输量。
- 使用场景:适用于满足结合律和交换律的操作,如求和、计数。
- 限制:不能影响最终业务逻辑(如求平均值就不适用),其输入/输出 K/V 类型需与 Reducer 一致。
- 与 Reduce 区别:Combiner 运行在 Map 端节点,是 Reducer 的“局部”版本;Reducer 运行在 Reduce 端节点,进行全局汇总。
10. 默认的分区 (Partition) 机制
如果未自定义 Partitioner,则使用 HashPartitioner。其计算方式为:key.hashCode() % numReduceTasks,得到的余数即为分区号。
11. 如何解决 MapReduce 数据倾斜(负载不均)?
通过自定义 Partitioner 实现。可以根据数据的特征,将热点 Key 分散到不同的 Reduce 任务中,从而平衡负载。
12. 如何用 MapReduce 实现 TopN?
- 在 Map 阶段,为每条数据输出,Key 为排序依据的字段,Value 为数据本身。
- 自定义
Partitioner,确保所有数据进入同一个 Reduce(实现全局排序)。
- 自定义
WritableComparable 实现倒序排序。
- 在 Reducer 的
reduce() 方法中,只输出前 N 条记录。
13. Hadoop 的分布式缓存 (DistributedCache)
用于在集群中分发应用所需的只读文件(如小表、字典、配置文件)。
- 机制:Job 提交前,将文件上传至 HDFS。任务启动时,NodeManager 将文件缓存到各个任务节点的本地磁盘,并创建符号链接供任务读取。
- 应用:常用于 Map Join(广播小表),可避免 Shuffle,大幅提升 Join 效率。
14. 如何使用 MapReduce 实现两个表的 Join?
- Reduce Side Join:
- 通用方法。Map 阶段为来自不同表的记录打上标签(Tag),输出时以 Join Key 作为新的 Key,Tag+记录作为 Value。
- Shuffle 后,相同 Key 的记录(来自两个表)进入同一个 Reducer,在 Reducer 中实现关联逻辑。
- 缺点:Shuffle 数据量大,效率较低。
- Map Side Join:
- 适用场景:一个大表和一个小表。
- 原理:利用 DistributedCache 将小表分发到所有 MapTask 节点内存中(如 HashMap)。Map 阶段只扫描大表,直接与内存中的小表进行关联。
- 优点:无 Shuffle,效率高。
15. 什么样的场景不适合使用 MapReduce?
- 数据量非常小。
- 存在大量琐碎的小文件。
- 需要低延迟的实时查询或事务处理。
- 当索引(如 HBase)是更合适的存取机制时。
- 单机即可处理的场景。
16. ETL 的含义
Extraction(抽取)、Transformation(转换)、Loading(加载)。指将数据从源端经过清洗、转换后加载到目标数据仓库的过程。
YARN 面试题总结
1. Hadoop 1.x 与 Hadoop 2.x 架构的主要区别
- 引入 YARN:将资源管理和作业调度/监控功能从 MapReduce 中分离出来,形成了独立的通用资源管理层。
- 支持高可用 (HA):为 HDFS NameNode 和 YARN ResourceManager 引入了高可用机制,通常依赖 Zookeeper 实现。
2. YARN 的产生与优势
- 解决问题:Hadoop 1.x 中 JobTracker 身兼资源管理和作业调度两职,存在单点故障和扩展性瓶颈。YARN 实现了 “资源管理”与“计算框架”的解耦。
- 优势:
- 通用性:YARN 成为统一的集群资源管理系统,不仅可以运行 MapReduce,还可以运行 Spark、Flink、Storm 等多种计算框架。
- 可扩展性:ResourceManager 专注于资源管理,调度更高效,集群规模支持更大。
- 高可用:支持 RM 的 HA。
3. HDFS 支持的压缩格式
常用压缩算法包括:bzip2, gzip, lzo, snappy。其中 lzo 和 snappy 需要安装 Native 库。企业环境中,Snappy 因其较快的压缩/解压速度和合理的压缩率而广泛应用。压缩可以在 Map 输入、Map 输出、Reduce 输出等阶段进行。
4. Hadoop/YARN 调度器
- FIFO Scheduler(默认):先进先出队列调度。
- Capacity Scheduler(容量调度器,Apache 默认):将集群资源划分为多个队列,每个队列分配一定容量,队列内部采用 FIFO 或多用户公平策略。支持资源弹性借用。
- Fair Scheduler(公平调度器,CDH 默认):所有作业/用户公平共享集群资源。当单个作业运行时,它可以使用全部资源;当有其他作业提交时,释放的资源会被公平地分配给新作业。
5. MapReduce on YARN 的容错性
- MRAppMaster 容错:若失败,由 YARN ResourceManager 负责重启(次数可配置)。超过最大重试次数则作业失败。
- MapTask/ReduceTask 容错:若执行失败,MRAppMaster 会重新向 RM 申请资源启动该任务(次数可配置)。多次失败后,整个作业失败。
6. 推测执行 (Speculative Execution) 原理
- 目的:解决因机器老化、负载不均等导致的个别 Task(“拖后腿”任务)执行过慢,从而影响整个作业完成时间的问题。
- 原理:当某个 Task 的运行速度远低于同类型 Task 的平均速度时,系统会在另一个节点上启动一个相同的备份任务。原始任务与备份任务谁先执行完,就采用谁的结果,并杀死另一个。
- 算法核心:计算任务“预计完成时间”,为最慢的任务启动备份。
- 禁用场景:任务负载严重倾斜、任务涉及幂等性写操作(如写数据库)时需关闭。
Hadoop 性能优化问题
1. MapReduce 程序运行缓慢的常见原因
- 硬件/资源瓶颈:CPU、内存、磁盘 I/O、网络带宽。
- I/O 与任务相关:
- 数据倾斜
- Map/Reduce 任务数量设置不合理
- 小文件过多
- 不可分片的超大文件
- 频繁的 Spill 和 Merge 操作
- Reduce 阶段等待时间过长
2. MapReduce 优化方法
- 输入阶段:
- 合并小文件(使用
CombineFileInputFormat)。
- Map 阶段:
- 增大
io.sort.mb 以减少 Spill 次数。
- 增大
io.sort.factor 以减少 Merge 次数。
- 合理使用 Combiner。
- Reduce 阶段:
- 合理设置 Map 和 Reduce 数量(避免过多或过少)。
- 调整
slowstart.completedmaps 使 Map 完成一定比例后 Reduce 就开始启动,减少等待。
- 设置
mapred.job.reduce.input.buffer.percent > 0,使 Reduce 直接从内存读取部分数据,减少磁盘 I/O。
- I/O 传输:
- 对 Map 输出和最终输出采用合适的压缩(如 Snappy)。
- 对中间数据使用 SequenceFile 等二进制格式。
- 解决数据倾斜:
- 范围分区:根据数据分布特征预设分区边界。
- 自定义分区:将导致倾斜的 Key 分散到多个分区。
- 使用 Combiner:在 Map 端进行局部聚合,减轻 Reduce 端压力。
- 对倾斜 Key 进行加盐(随机前缀)处理,在最终结果中再去盐。
3. HDFS 小文件优化方法
- 弊端:每个小文件都会在 NameNode 内存中占据约 150 字节的元数据,消耗大量内存,影响扩展性和性能。
- 解决方案:
- 从源头合并:在数据采集阶段进行文件合并。
- 使用 Hadoop Archive (HAR):将大量小文件打包成一个
.har 文件,减少 NameNode 内存占用,但访问效率略有下降。
- 使用 SequenceFile:将小文件以
Key(文件名)-Value(文件内容) 的形式写入 SequenceFile。
- 使用 CombineFileInputFormat:作为 MapReduce 的输入格式,在逻辑上将多个小文件合并到一个 Split 中,从而减少 MapTask 数量。
Hive 面试题整理(一)
1. 如何解决 Hive 表关联查询时的数据倾斜?
- 倾斜原因:Join Key 分布不均、空值过多、数据类型不匹配等。
- 解决方案:
- 参数调优:
- 开启 Map 端聚合:
set hive.map.aggr = true;
- 开启倾斜键的负载均衡:
set hive.groupby.skewindata=true;(会生成两个 MR Job 分散倾斜 Key)。
- SQL 调优:
- Map Join:若一张表很小,可强制使用 Map Join:
set hive.auto.convert.join=true;
- 空值处理:给空 Key 添加随机前缀,分散到不同的 Reduce 处理。
- 大表 Join 大表:检查并过滤导致倾斜的异常 Key,或将其拆分处理。
2. Hive SQL 转换为 MapReduce 的过程
- SQL Parser:将 SQL 字符串解析为抽象语法树(AST)。
- Semantic Analyzer:遍历 AST,转化为查询块(Query Block)。
- Logical Plan Generator:将 Query Block 转换为逻辑操作符树(Operator Tree)。
- Logical Optimizer:对 Operator Tree 进行逻辑优化(如谓词下推、列裁剪)。
- Physical Plan Generator:将逻辑计划转换为物理计划(一系列 MapReduce 任务)。
- Physical Optimizer:对物理计划进行优化(如分区裁剪、Map Join 选择)。
- Execution:提交最终的 MapReduce 任务到集群执行。
3. Hive 元数据的存储
Hive 的元数据(表结构、分区信息等)存储在关系型数据库(如 MySQL、Derby)中,而非 HDFS。这便于元数据的频繁读取和修改。
4. 使用 MapReduce 实现 Hive 两表关联
- 若为 Map Join,则在 Map 端完成,无 Reduce 阶段。
- 若为 Common Join,其 MapReduce 实现与前述“Reduce Side Join”原理一致:Map 阶段打标签,Shuffle 按 Key 分发,Reduce 端进行关联操作。
5. Hive 的特点及其与 RDBMS 的异同
- 特点:基于 Hadoop 的数据仓库,将结构映射为表,支持类 SQL(HQL)查询,底层转换为 MapReduce/Tez/Spark 作业。适合离线批处理,不支持 OLTP 实时查询和事务(新版本支持有限事务)。
- 与 RDBMS 对比:
- 数据规模:Hive 处理 PB 级数据,RDBMS 通常在 TB 级以下。
- 执行引擎:Hive 通过 MR/Tez/Spark 分布式执行,RDBMS 有专属优化引擎。
- 延迟:Hive 延迟高(分钟级+),RDBMS 延迟低(秒/毫秒级)。
- 事务/更新:Hive 早期不支持,现支持有限事务(ORC 格式);RDBMS 全面支持 ACID。
- 存储:Hive 数据在 HDFS,不支持索引(有 ORC 等格式优化);RDBMS 有复杂索引和存储引擎。
6. Sort By, Order By, Cluster By, Distribute By 的区别
ORDER BY:全局排序,结果输出到一个文件(一个 Reducer)。数据量大时性能瓶颈严重。SORT BY:区内排序,在数据进入 Reducer 前排序,保证每个 Reducer 输出有序。DISTRIBUTE BY:控制分区,按照指定字段将数据分发到不同的 Reducer。CLUSTER BY:当 DISTRIBUTE BY 和 SORT BY 的字段相同时,可以用 CLUSTER BY 替代。它同时具有分区和区内排序的功能。
7. Hive 内置函数示例
split('a,b,c', ',') -> 数组 ["a","b","c"]coalesce(NULL, 'a', 'b') -> 'a' (返回第一个非 NULL 值)collect_list(column) -> 将分组内某列的值聚合成一个数组(不去重)
8. Hive 元数据的存储方式
- 内嵌模式 (Embedded):使用内嵌的 Derby 数据库,仅用于测试,不支持多会话。
- 本地模式 (Local):元数据库(如 MySQL)与 Hive 服务在同一台机器。
- 远程模式 (Remote):元数据库独立部署,Hive 服务通过 JDBC 远程访问。这是生产环境常用模式,支持多 HiveServer2 实例共享元数据。
9. Hive 内部表与外部表的区别
| 特性 |
内部表 (Managed Table) |
外部表 (External Table) |
| 创建 |
数据移动到 Hive 仓库目录 |
仅记录数据位置,不移动数据 |
| 删除 |
删除元数据和HDFS数据 |
仅删除元数据,HDFS数据保留 |
| 用途 |
临时/中间数据 |
原始数据、需要共享的数据 |
10. Hive 文件存储格式对比
- TextFile:默认格式,行存储,无压缩,解析开销大。
- SequenceFile:行存储,二进制格式,支持压缩和分割。
- RCFile:行列混合存储。先按行分块,块内按列存储。压缩和查询性能较好。
- ORCFile:RCFile 的优化版。存储效率、压缩率和查询性能最佳,是生产环境首选列式存储格式之一。
- Parquet:另一种高效的列式存储格式,特别适用于嵌套数据结构。
11. 所有 Hive 查询都会触发 MapReduce 吗?
不是。对于简单的、只涉及数据读取和少量过滤的操作,如 SELECT * FROM table LIMIT 10;,Hive 会启用 Fetch Task 模式,直接从 HDFS 读取数据返回,而不启动 MapReduce 作业。
12. Hive 函数 UDF、UDAF、UDTF 的区别
- UDF (User-Defined Function):一进一出。如
upper()。
- UDAF (User-Defined Aggregation Function):多进一出。聚合函数,如
sum()、count()。
- UDTF (User-Defined Table-Generating Function):一进多出。如
explode(),将数组或 Map 拆分成多行。
13. 对 Hive 桶表的理解
- 原理:根据表中某列的 Hash 值将数据分成固定数量的桶(文件)。分桶字段 =
hashfunc(bucketing_column) % num_buckets。
- 目的:
- 高效抽样:
TABLESAMPLE(BUCKET x OUT OF y)。
- 提升某些查询(如 Map Join)效率,因为相同 Join Key 的数据落在同一个桶中。
- 注意:桶表是专业性设计,用于优化特定场景,并非日常存储数据的默认选择。
Hive 面试题整理(二)与优化
1. Fetch 抓取
通过设置 hive.fetch.task.conversion=more(默认),对于 SELECT *、LIMIT、字段筛选等简单查询,Hive 可以不执行 MapReduce,直接从数据源读取数据,提高效率。
2. 本地模式
对于小数据集,启动分布式任务的开销可能超过任务本身。设置 hive.exec.mode.local.auto=true 后,Hive 会尝试在单个机器上本地运行所有任务,显著缩短执行时间。
3. 表的优化
- 小表 Join 大表:使用 Map Join。新版 Hive 可自动优化。
- 大表 Join 大表:
- 空 Key 过滤:在 Join 前过滤掉 NULL 或无效的 Join Key。
- 空 Key 转换:给空 Key 添加随机前缀,分散到不同 Reducer,避免倾斜。
- Group By 优化:
- 开启 Map 端聚合:
hive.map.aggr=true
- 开启倾斜数据负载均衡:
hive.groupby.skewindata=true(生成两个 MR Job)。
- Count(Distinct) 去重:数据量大时,用
GROUP BY 后再 COUNT 的方式替代 COUNT(DISTINCT col),避免全局去重导致单个 Reducer 压力过大。
- 避免笛卡尔积:Join 时必须写 ON 条件。
- 行列过滤:
- 列:使用
SELECT 指定列,而非 SELECT *。
- 行:分区表先使用分区过滤;关联查询时,副表过滤条件尽量写在子查询中或 ON 条件里,避免先全表关联再过滤(谓词下推)。
4. 数据倾斜与任务调优
- 合理设置 Map 数量:
- 小文件过多(远小于128M)会导致 Map 数过多,启动开销大。可通过合并小文件解决。
- 单个文件很大,但字段少、行数多导致单个 Map 处理逻辑复杂时,可考虑通过调小
mapreduce.input.fileinputformat.split.maxsize 来增加 Map 数。
- 合理设置 Reduce 数量:
- 依据:
N = min(hive.exec.reducers.max, 总输入数据量 / hive.exec.reducers.bytes.per.reducer)。
- 也可直接设置:
set mapreduce.job.reduces = N;
- 并非越多越好:Reducers 过多会导致小文件问题,且启动开销大。
- 并行执行:设置
hive.exec.parallel=true,允许 Hive 作业中多个可并行的阶段(如多个子查询)同时运行,缩短作业时间。
Zookeeper 面试题总结
1. Zookeeper 的选举机制
以 5 台服务器(myid=1~5)为例:
- 服务器1启动,发起选举,只有自己一票,状态保持 LOOKING。
- 服务器2启动,与服务器1交换选票。两者都无历史数据,比较 myid,服务器2胜出。但票数未过半(2 < 3),状态保持 LOOKING。
- 服务器3启动,参与选举。同样比较 myid,服务器3胜出。此时它获得三票(1,2,3),票数过半,当选为 Leader。服务器1、2 成为 Follower。
- 服务器4、5 陆续启动,发现已有 Leader,直接成为 Follower。
关键点:选举基于 myid 和 zxid,初始时 zxid 相同,myid 大者胜出;必须获得超过半数的服务器投票才能成为 Leader。
2. 如何处理 CONNECTIONLOSS 和 SESSIONEXPIRED?
- CONNECTIONLOSS(连接断开):通常是网络闪断。客户端会自动尝试重连到集群中的其他服务器。重连成功后,会话 (
Session) 仍然有效,但需要检查之前的操作(如 create, setData)是否成功(可能因状态不确定而失败)。
- SESSIONEXPIRED(会话过期):发生在连接断开时间超过
sessionTimeout 时。会话永久失效,所有临时节点 (Ephemeral Znode) 将被删除。客户端需要重新建立 Zookeeper 对象,并重建会话状态。
3. 一个客户端修改数据后,其他客户端能否立即读到最新数据?
不能保证。Zookeeper 保证最终一致性,但不同客户端看到的数据更新可能存在短暂延迟。如果需要强一致性,客户端应在读操作前调用 sync() 方法,确保读到最新数据。
4. Watch 监听是永久的吗?
不是。Watch 是一个一次性触发器。一旦被触发(即监听的 Znode 发生变化),该 Watch 就会被移除。如果需要持续监听,必须在处理 Watch 事件的回调函数中重新注册 Watch。
5. 使用 Watch 的注意事项
- 一次性触发,需重复注册。
- 发生 CONNECTIONLOSS 但未 SESSIONEXPIRED 时,重连后之前注册的 Watches 依然有效。
- 同一个客户端对同一个 Znode 注册相同的 Watch,只会收到一次通知。
- Watch 对象仅保存在客户端。
6. 能否收到节点每次变化的通知?
不能保证。如果节点更新频率极高,在客户端收到通知并重新注册 Watch 的间隙中,可能发生了多次更新,这些中间状态的变化无法被捕获。
7. 能否为临时节点创建子节点?
不能。临时节点 (EPHEMERAL) 不允许拥有子节点。
8. 能否拒绝单个 IP 的访问?
Zookeeper 本身不支持基于 IP 的访问控制列表 (ACL)。可通过操作系统的防火墙(如 iptables)或在网络层面实现。
9. 临时节点何时被删除?
不是在连接断开时立即删除。当客户端与服务器连接断开后,其会话进入倒计时。只有在会话超时(SESSIONEXPIRED) 后,服务器才会删除该会话创建的所有临时节点。因此,sessionTimeout 的设置需谨慎。
10. Zookeeper 是否支持动态扩容?
原生支持有限。常见扩容方式为逐个重启:将新服务器加入配置文件,然后依次重启集群中的每台服务器(先重启 Leader 以外的)。此过程对客户端影响较小。
11. Zookeeper 集群服务器间如何通信?
Leader 与每个 Follower/Observer 都建立独立的 TCP 连接,并为每个连接创建一个 LearnerHandler 线程,专门负责与该节点的数据同步、心跳、提案投票等网络通信。
12. Zookeeper 会自动清理日志吗?
不会。Zookeeper 的事务日志 (transaction log) 和快照文件 (snapshot) 需要运维人员定期清理(如使用自带的 PurgeTxnLog 工具或配置自动清理策略),以防止磁盘写满。
13. 对 Zookeeper 的理解
Zookeeper 是一个分布式协调服务,用于解决分布式系统中的一致性问题。它提供:
- 类似文件系统的分层命名空间(Znode)。
- 节点的监听通知机制(Watch)。
- 基于 Paxos 算法变种 ZAB 协议的强一致性。
- 核心功能:统一配置管理、集群管理(Master 选举、服务上下线感知)、分布式锁、队列等。
注意:Znode 设计用于存储少量元数据或状态信息(上限约 1MB),而非大块数据。
14. Znode 节点类型
- 持久节点 (PERSISTENT):客户端断开后仍存在。
- 持久顺序节点 (PERSISTENT_SEQUENTIAL):在持久节点基础上,名称由 ZK 自动追加顺序编号。
- 临时节点 (EPHEMERAL):客户端会话失效后自动删除。
- 临时顺序节点 (EPHEMERAL_SEQUENTIAL):在临时节点基础上,名称由 ZK 自动追加顺序编号。常用于实现分布式锁。
15. Zookeeper 的通知机制
客户端在读取 Znode 数据时可以设置一个 Watch。当该 Znode 的数据发生变化或子节点列表发生变化时,Zookeeper 会向设置 Watch 的客户端发送一个一次性的事件通知。客户端收到通知后,再根据业务逻辑进行处理。
16. Zookeeper 的监听原理
- 客户端创建
ZooKeeper 对象时,会启动两个线程:Listener(事件处理)和 Connect(网络I/O)。
- 客户端通过
Connect 线程向服务器注册 Watch。
- 当被监听的 Znode 发生变化,服务器通过
Connect 线程将事件通知发送给客户端。
- 客户端的
Listener 线程接收事件,并调用预先注册的 Watcher.process() 方法进行处理。
17. 关键端口作用
- 2181:客户端连接端口。
- 2888:Leader 和 Follower 之间进行数据同步和通信的端口。
- 3888:用于 Leader 选举投票通信的端口。
18. 部署方式与集群角色
- 部署方式:单机模式、集群模式。
- 集群角色:Leader(负责写请求和协调)、Follower(处理读请求,参与选举和提案投票)、Observer(处理读请求,不参与投票,用于扩展读性能)。
- 最小机器数:3台(2N+1)。为了保证选举能产生多数票,集群规模通常为奇数。
19. 集群容错能力
- 3台机器的集群,挂掉1台(剩余2台 > 半数1.5)可以继续工作。
- 挂掉2台(剩余1台 ≤ 半数1.5)则无法形成多数派,集群将停止服务。
20. ZAB 协议与 Paxos 算法的异同
- 相同点:都是分布式一致性协议,通过 Leader 提案、Follower 投票、过半确认的机制保证数据一致。
- 不同点:
- Paxos:更理论化、通用的一致性算法。
- ZAB (Zookeeper Atomic Broadcast):为 Zookeeper 量身定制,保证了严格的操作顺序性,并优化了崩溃恢复过程,更适合作为协调服务的核心协议。
21. Zookeeper 对事务性的支持
Zookeeper 通过 multi 操作支持原子性事务。客户端可以将多个创建、删除、修改、检查版本的操作 (Op) 放入一个 multi 请求中。Zookeeper 服务端会按顺序原子性地执行这些操作,即全部成功或全部失败。这可以用于实现复杂的原子操作,如“CAS(检查并设置)”。
 发表于 2025-12-29 20:39:48
|
查看: 284|
回复: 0
发表于 2025-12-29 20:39:48
|
查看: 284|
回复: 0
