算力:TOPS展示计算机能力的指标,是衡量 NPU 性能的核心。TOPS 通过以万亿单位测量一秒内执行的运算(加法,乘法等)次数来量化 NPU 处理能力。
MACs: MAC(乘积累加运算 (Multiply ACcumulate operations) )是 NPU 中执行的基本运算。
频率:决定 NPU 及其 MAC 单元(以及 CPU 或 GPU)运算的始终速度(或每秒周期数),直接影响整体性能,更高的频率允许在单位时间内执行更多运算,从而提高处理速度。
精度:计算的颗粒度,通过精度越高模型准确性就越高,需要的计算强度也越高。
TOPS=2×MACs×频率/1万亿
OPS: Operations per second ,每秒运算数。
FLOPS: (Floating Point Operations per Second) 指每秒浮点运算次数。
关联关系
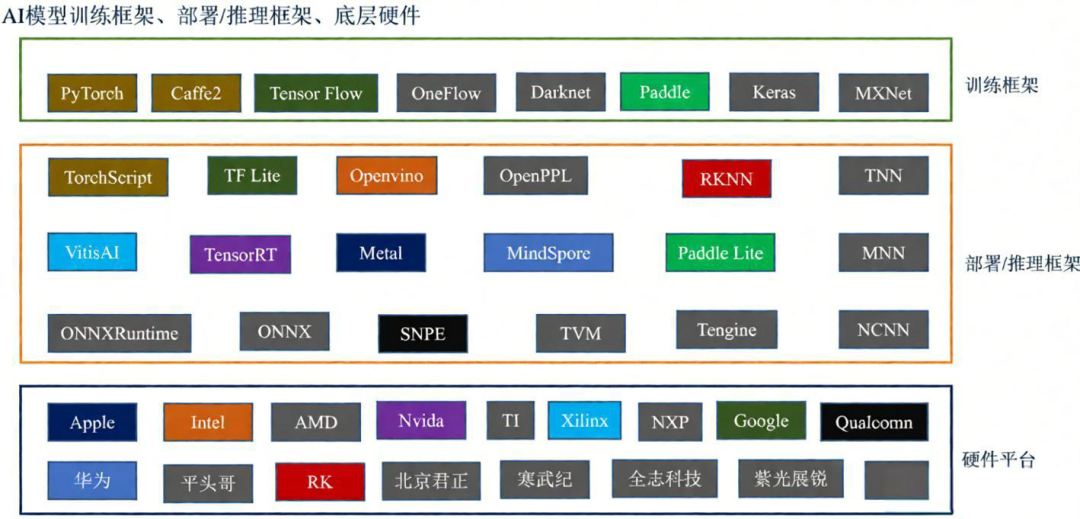
图1:AI模型训练框架、部署/推理框架与底层硬件的分类关系图。
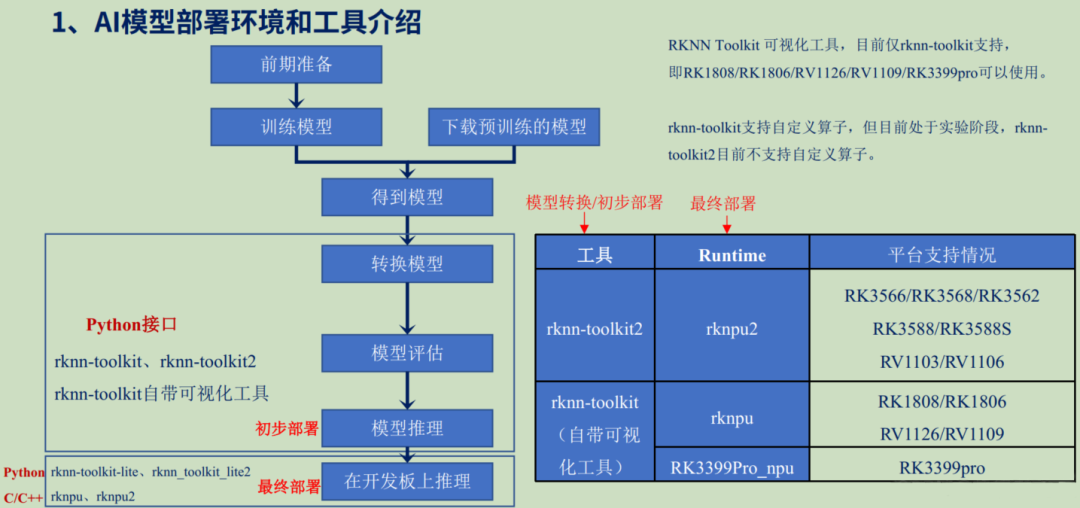
图2:AI模型从前期准备、训练、转换到最终在开发板上部署的完整流程图。
在Rockchip(RK)的硬件平台上,可以使用rknn-toolkit2进行模型转换,得到RKNN框架模型,最后在开发板上使用rknn-tookit-lite和rknpu进行推理实现。
参考 Github: https://github.com/airockchip/rknn-toolkit2?tab=readme-ov-file
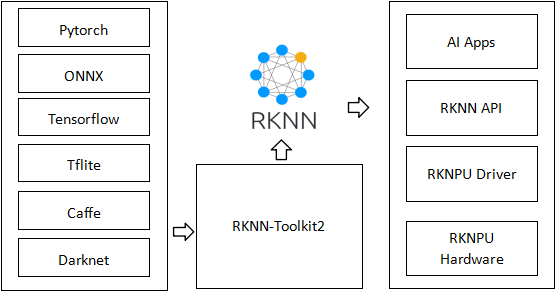
图3:RKNN框架图,展示了从不同深度学习框架到RKNN模型,再到AI应用的完整转换流程。
In order to use RKNPU, user need to first run the RKNN-Toolkit2 tool on the computer, convert the trained model into an RKNN format model, and then inference on the development board using the RKNN C API or Python API.
- RKNN-Toolkits 是一个软件开发工具包,供用户在 PC 和 Rockchip NPU 平台上执行模型转换,推理和性能评估。
- RKNN-Toolkit-Lite2 为 Rockchip NPU 平台提供 Python 程序接口来帮助用户加快人工智能应用的实施。
- RKNN Runtime 提供 C/C++ 程序接口。
- RKNPU kernel driver 负责于 NPU 硬件交互,开源,在 rockchip kernel code 可以找到。
为用户提供了在计算机上进行模型转换,推理和性能评估的开发套件。
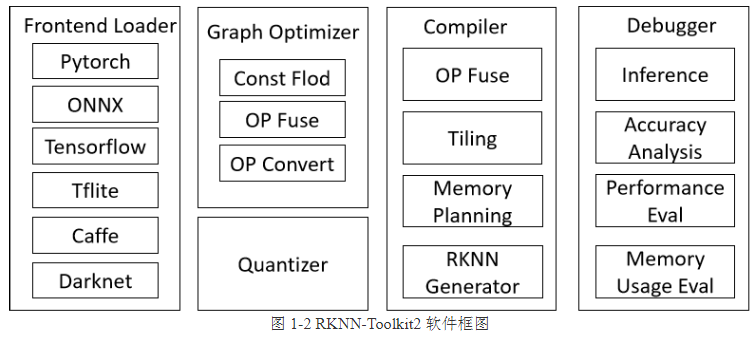
图4:RKNN-Toolkit2软件框架图,包含前端加载器、图优化器、编译器和调试器等核心模块。
主要功能:
- 模型转换:将原始的深度学习模型转化为 RKNN 格式,以便在 RKNPU 平台上进行高效的推理。
- 量化功能:支持将浮点模型量化为定点模型,并支持混合量化。
- 模型推理:将 RKNN 模型分发到指定的 NPU 设备上进行推理并获取推理结果,或在计算机上仿真 NPU 运行 RKNN 模型并获取推理结果。
- 性能和内存评估:将 RKNN 模型分发到指定 NPU 设备上运行,以评估模型在实际设备上运行时的性能和内存占用情况。
- 量化精度分析:该功能将给出模型量化后每一层推理结果与浮点模型推理结果的余弦距离和欧氏距离,以便于分析量化误差是如何计算,为提高量化模型的精度提供思路。
- 模型加密:使用指定的加密算法将 RKNN 模型整体加密。
使用 Toolkit-lite2 可以运行在 PC 上,通过模拟器运行模型,然后进行推理,或者模型转化等操作,也可以运行在连接的板卡 NPU 上,将 RKNN 模型传到 NPU 上运行。
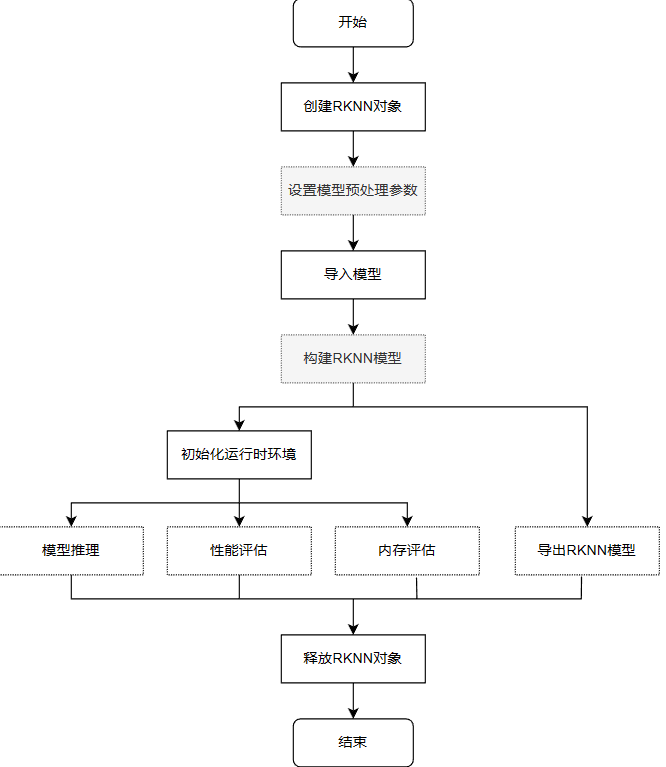
图5:从创建RKNN对象到释放资源的完整模型构建与推理流程图。
RKNN Runtime
负责加载RKNN模型,并调用NPU驱动实现在NPU上推理 RKNN 模型。
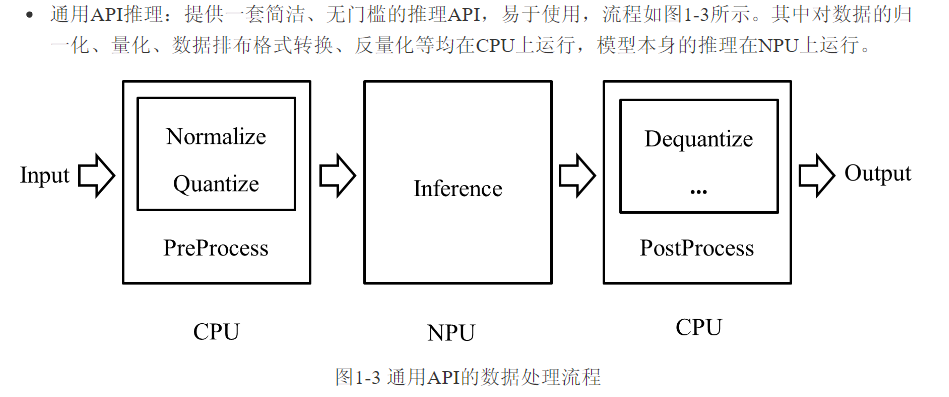
图6:通用API推理流程,展示了数据从输入、预处理、NPU推理到后处理的完整路径。
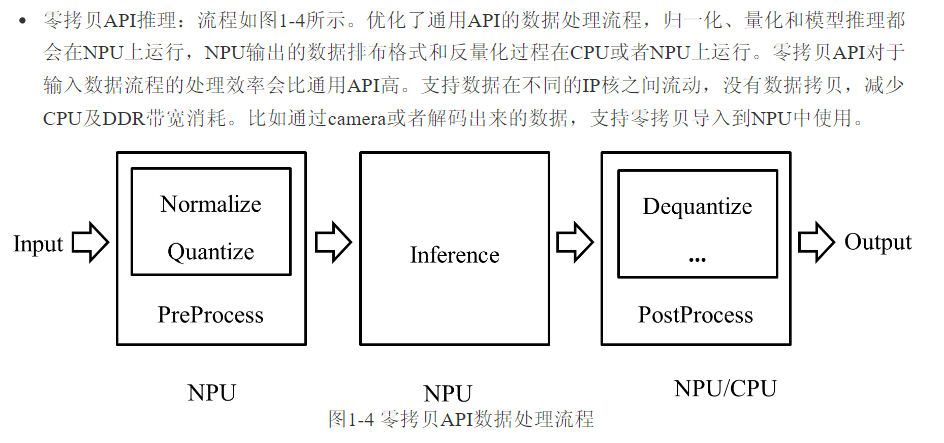
图7:零拷贝API推理流程,优化了数据处理路径,减少了CPU与内存间的数据拷贝。
当用户输入数据只有虚拟地址时,只能使用通过API接口;当用户输入数据有物理地址或fd时,两组接口都可以使用。
开发环境配置 (服务器端)
参考 RK 文档: Rockchip_RKNPU_User_Guide_RKNN_SDK_V2.3.0_CN
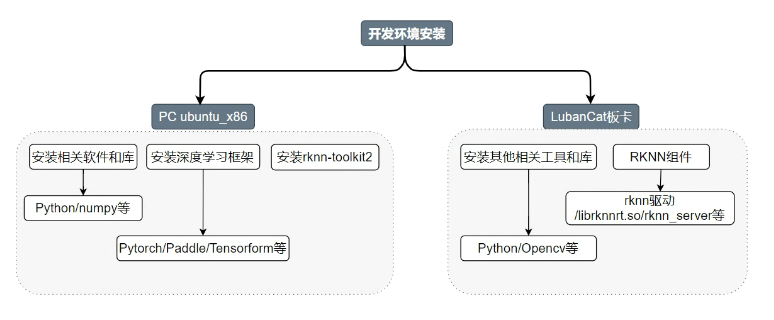
图8:开发环境安装流程图,区分了PC端(Ubuntu x86)与LubanCat板卡端的不同配置。
需要在服务器上安装相关工具,将对应的模型转换为 RKNN 模型,再导入到主板上使用。
- 深度学习框架:
PyTorch, TensorFlow, PaddlePaddle
- 使用虚拟环境:
Miniconda
# 配置pip源 全局设置清华镜像站 建议配置,否则后面很多pip3安装会报错
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
Writing to /home/qiany/.config/pip/pip.conf
下载 RKNN 相关仓库
mkdir Projects
cd Projects
# 下载 RKNN-Toolkit2
git clone https://github.com/airockchip/rknn-toolkit2.git --depth 1
# 下载RKNN Model Zoo仓库
git clone https://github.com/airockchip/rknn_model_zoo.git --depth 1
# 参数--depth 1 只克隆最后一次commit
安装 Miniforge Conda: Python 环境和包管理工具,提供了轻量级,高效的Conda发行版,适合希望避免 Anaconda 大型包集合或者对系统资源有限制的用户。通过使用Miniforge,可以享受到Conda的便利,同时无需担心额外的负担。
wget -c https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh
chmod 777 Miniforge3-Linux-x86_64.sh
bash Miniforge3-Linux-x86_64.sh
创建 python 环境
source ~/miniforge3/bin/activate # 替换为实际安装路径
conda create -n toolkit2 python=3.8
conda activate toolkit2
# 成功后 命令行提示符会变成 (toolkit2) 用户名@设备名:~$
激活 toolkit2 环境之后,通过 pip 源或者本地 wheel 包安装 RKNN-Toolkit2
# 很可能安装失败
pip install rknn-toolkit2 -i https://pypi.org/simple
# 使用清华镜像源
pip install rknn-toolkit2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 如果已经安装可以通过如下进行更新
pip install rknn-toolkit2 -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade
# 通过本地的wheel包进行安装
cd rknn-toolkit2/rknn-toolkit2
# 根据自己电脑的CPU架构以及Python版本进行安装
pip install -r packages/x86/requirement_cpXX.txt
# 安装RKNN-Toolkit2
# 请根据不同的python版本及处理器架构,选择不同的wheel安装包文件
验证是否成功
# 进入python交互模式
python
# 导入RKNN类
from rknn.api import RKNN
安装深度学习框架
# 安装tensorflow
pip3 install tensorflow
# 根据需要进行安装
pip3 install pytorch
RKNPU2 环境
RKNN Server:一个运行在开发板上的后台代理服务,该服务的主要功能是调用板端 Runtime 对应的接口处理计算机通过 USB 传输过来的数据,并将处理结果返回给计算机。
RKNPU2 Runtime 库 (librknnrt.so) :主要职责是负责在系统中加载 RKNN 模型,并通过调用专用的神经处理单元(NPU)执行 RKNN 模型的推理操作。
# 进入板端
adb shell
# 启动rknn_server
restart_rknn.sh
RKNN Model Zoo
RKNN Model Zoo 提供了示例代码,旨在帮助用户快速在Rockchip的开发板上运行各种模型。
基于 RKNPU SDK 工具链开发,提供了目前主流算法的部署历程,例如包含导出 RKNN 模型,使用 Python API,C API 推理RKNN模型的流程。
# 下载模型
git clone https://github.com/airockchip/rknn_model_zoo.git
# 获取yolov10 onnx模型文件
cd rknn-toolkit2-master/rknn_model_zoo/examples/yolov5/model
chmod a+x download_model.sh
./download_model.sh
# 执行模型转换程序
conda activate toolkit2
cd rknn-toolkit2-master/rknn_model_zoo/examples/yolov10/python
python3 convert.py ../model/yolov10n.onnx rk3568
# output model will be saved as ../model/yolov10.rknn
设置环境
Please set GCC_COMPILER for rk356x
# 文档地址查看 RK文档
export GCC_COMPILER=/qiany/AIProjects/gcc-linaro-6.3.1-2017.05-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu
cmake 没有找到
sudo apt update
# 安装cmake
sudo apt install cmake
执行编译指令
进入编译执行
./build-linux.sh -t rk356x -a aarch64 -d yolov5
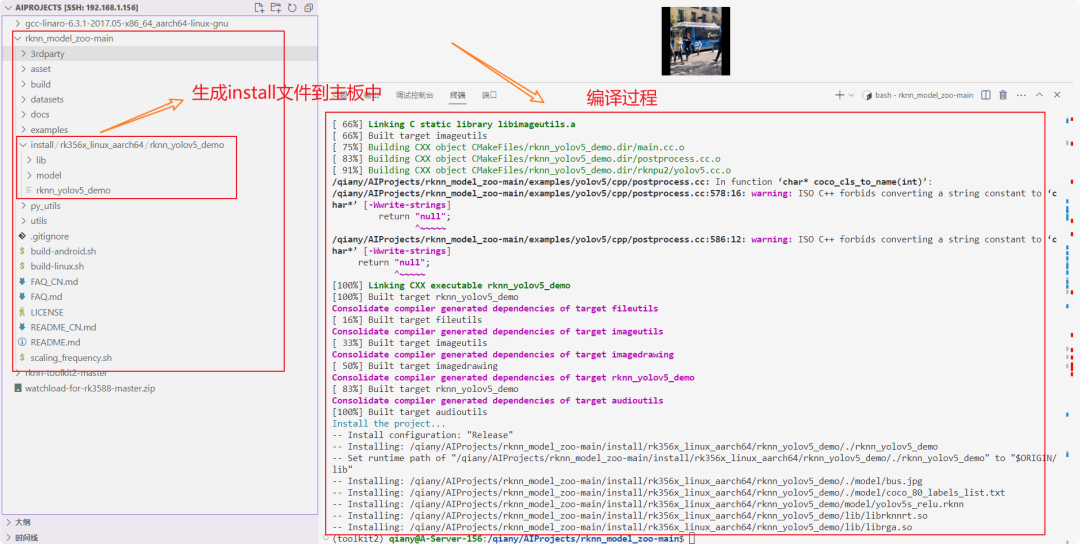
图9:编译过程终端输出及生成到主板的install文件目录结构。
真机测试
将生成的 install 文件传入主板当中
adb push W:\AIProjects\rknn_model_zoo-main\install /home/ubuntu/
进行运行测试
root@ubuntu:/home/ubuntu/install/rk356x_linux_aarch64/rknn_yolov5_demo# ./rknn_yolov5_demo model/yolov5s_relu.rknn model/bus.jpg

图10:在开发板终端中运行YOLOv5 demo,并查看生成的文件列表。
RKNN-LLM
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件,通过该工具提供的 Python 接口可以便捷地完成:
- 模型转换:将
Hugging Face和GGUF格式的大语言模型转化为RKLLM模型,转换后的 RKLLM 模型能够在Rockchip NPU平台上加载使用。由于支持 Hugging Face,这样支持的大模型就十分多。
- 量化功能:支持将
浮点数模型量化为定点模型。
RKLLM Runtime主要负责加载 RKLLM-Toolkit 转换得到的RKLLM模型,并在板端通过调用 NPU 驱动在Rockchip NPU上加速 RKLLM 模型的推理。用户可以自行定义 RKLLM 模型的推理参数设置,定义不同的文本生成方式,并通过预先定义的回调函数不断获得模型的推理结果。
适用于:RK3576, RK3588, RK3562, RV1126B (如果非此平台,请使用上方的 rknn-toolkit2 模型方法)
开源地址: https://github.com/airockchip/rknn-llm
下载解压后的目录:
(base) qiany@A-Server-156:/qiany/AIProjects/rknn-llm$ ls
benchmark.md CHANGELOG.md doc examples LICENSE README.md res rkllm-runtime rkllm-toolkit rknpu-driver scripts
开发流程
- 模型转换
- 获取原始模型:开源的 Hugging Face 格式大语言模型,或自行训练,或者 GGUF 模型。
- 模型加载:通过
rkllm.load_huggingface()函数加载huggingface格式模型,通过rkllm.load_gguf()函数加载GGUF模型。
- 模型量化配置:通过
rkllm.build()函数构建RKLLM模型。在构建过程中可选择是否进行量化模型来提高模型部署在硬件上的性能,以及选择不同的优化等级和量化类型。这个过程中涉及到的模型训练与优化策略是关键。
- 模型导出:通过
rkllm.export_rkllm()函数将 RKLLM 模型导出为一个.rkllm格式文件,用于后续部署。
- 板端部署
- 模型初始化:加载 RKLLM 模型到
Rockchip NPU平台,进行相应的模型参数设置来定义所需的文本生成方式,并提前定义用于接受实时推理结果的回调函数,进行推理准备。
- 模型推理
- 模型释放
环境搭建 (服务器端)
创建 conda 环境
# 创建
conda create -n RKLLM-Toolkit python=3.10
# 激活
conda activate RKLLM-Toolkit
# 修改镜像
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
查看所有conda环境
conda env list
# 如果有删除需求,可以删除
conda env remove --name RKLLM-Toolkit
安装RKLLM-Toolkit,在对应的package目录,安装对应的版本
pip3 install rkllm_toolkit-....whl
验证测试
python
from rkllm.api import RKLLM
如果没有报错即调用成功。
部署流程
模型转换

图11:从Hugging Face预训练模型到生成RKLLM模型,再到设备部署的完整工作流。
将deepseek模型转换为 rkllm模型:
- Generate quantization calibration data using generate_data_quant.py
- Convert the model to RKLLM format using export_rkllm.py
- Configure chat templates and custom model parameters as needed
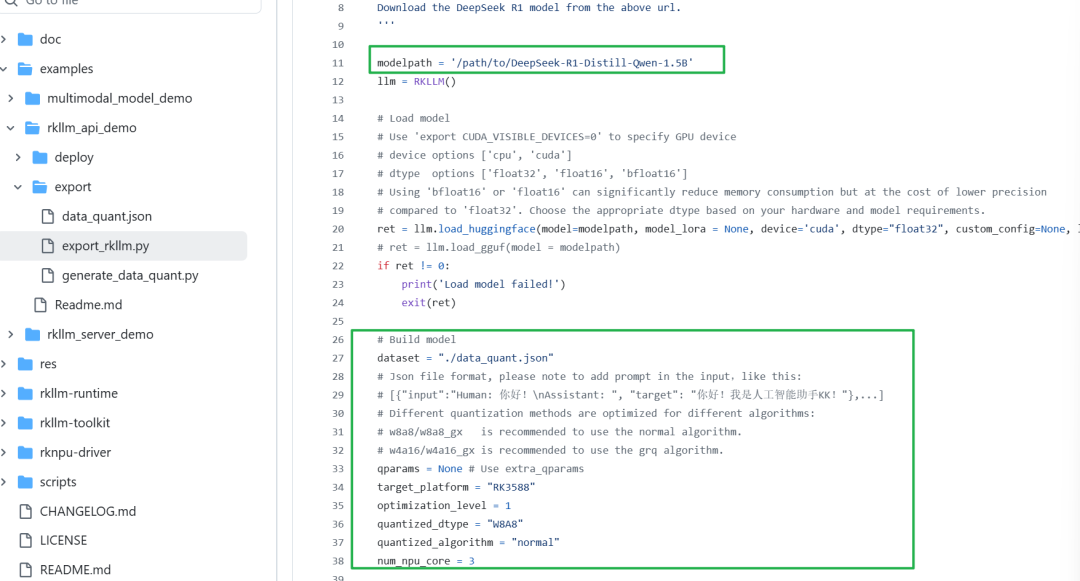
图12:Python代码片段,展示了如何加载Hugging Face模型并配置量化参数。
cd export
# 修改为下载的deepseek模型地址
python generate_data_quant.py -m /path/to/DeepSeek-R1-Distill-Qwen-1.5B
# 要修改python配置,配置主板机型,如rk3562或3576
# 修改源码中的modelpath参数
python export_rkllm.py # 将会生成rkllm模型,下方部署需要调用,通过参数
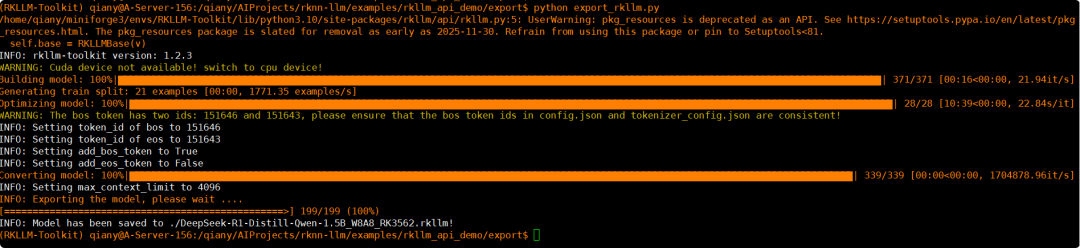
图13:终端显示的模型量化、转换与保存过程的日志信息。
Demo 编译
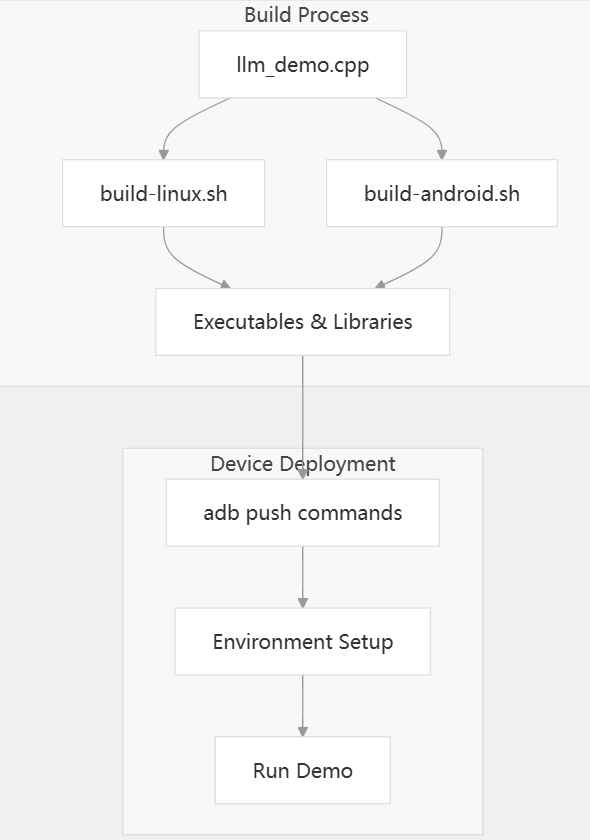
图14:从源代码到可执行文件,再到设备部署运行演示的完整构建过程。
在deploy文件夹,RK 提供了板载推理的示例代码。
图15:部署(deploy)目录下的demo源码文件(C++)及不同平台的编译脚本。
Android 版本 ANDROID_NDK_PATH配置 :https://blog.csdn.net/momo0853/article/details/73898066 (如果后面运行缺少库,将对应的库复制到 lib 文件中即可)
ANDROID_NDK_PATH=/qiany/AIProjects/android-ndk-r21e
Linux 版本:GCC_COMPILER_PATH配置 下载地址:https://github.com/UWVG/aarch64-none-linux-gnu
aarch64-linux-gnu-gcc 是一个交叉编译工具链,可以在其他架构的系统中,编译安装 64 位 arm 架构的程序。常用在嵌入式代码的移植中。aarch64-linux-gnu-gcc 是由 Linaro 公司基于 GCC 推出的的 ARM 交叉编译工具。 可以交叉编译 ARMv8 64 位目标中的裸机程序,u-boot, Linux Kernel, filesystem 和 App 应用程序。
export GCC_COMPILER_PATH=/qiany/AIProjects/aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu
生成的文件在install文件夹当中,将 install 文件内容部署到开发板中即可执行。
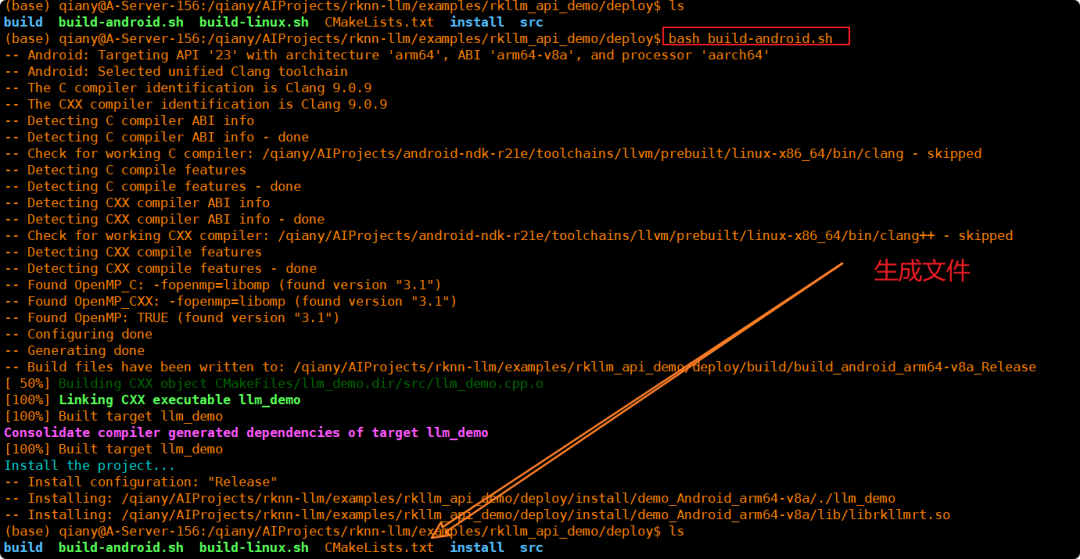
图16:编译脚本执行过程终端输出,最终在install目录生成可执行文件与库。
部署到主板 (RK3576)
先在主板上查看 RKNPU 的版本。
cat /sys/kernel/debug/rknpu/version
# RKNPU driver: v0.9.8
将生成的 install 下的目录和 rkllm 模型都拷贝到 Android 主板上。
cd deploy
# for linux
./build-linux.sh
# for android
./build-android.sh
# 权限
adb root
# push install dir to device
adb push install/demo_Linux_aarch64 /data
# push model file to device
adb push DeepSeek-R1-Distill-Qwen-1.5B.rkllm /data/demo_Linux_aarch64
# push the appropriate fixed-frequency script to the device
adb push ../../../scripts/fix_freq_rk3588.sh /data/demo_Linux_aarch64
adb push "W:\AIProjects\rknn-llm\scripts\fix_freq_rk3576.sh" /data/demo_Android_arm64-v8a
# 在开发板中运行
adb shell
cd /data/demo_Linux_aarch64
# export lib path 加载动态库,如果缺少,参考下方在ndk库中添加
export LD_LIBRARY_PATH=./lib
# Execute the fixed-frequency script
sh fix_freq_rk3576.sh
# Set the logging level for performance analysis
export RKLLM_LOG_LEVEL=1
# 授予执行文件权限
chmod 777 llm_demo
# 模型文件与执行文件在相同目录,如果不在则第二个参数使用编译好的对应主板的模型路径
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3576.rkllm 2048 4096
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3562.rkllm 2048 4096
# 针对缺少的文件,在NDK复制到对应的lib目录内 (目前我这边缺少libomp.so库),将其复制到install的lib目录
# 此处的ANDROID_NDK_PATH 与上方编译demo时使用相同的 ndk
android-ndk-r21e\toolchains\llvm\prebuilt\linux-x86_64\lib64\clang\9.0.9\lib\linux\aarch64
# Running result
rkllm init start
rkllm init success
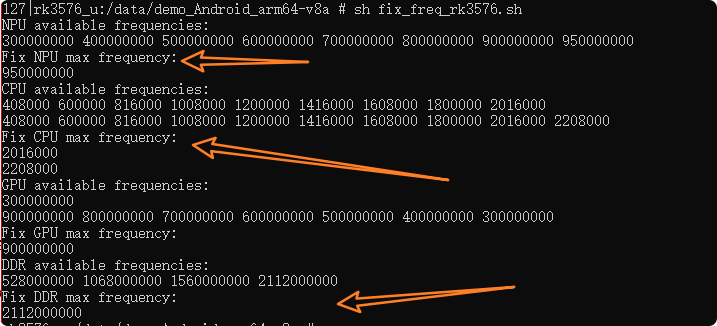
图17:运行固定频率脚本后,终端显示的NPU、CPU、GPU、DDR可用及最大频率信息。
部署deepseek demo到 3576 主板当中。
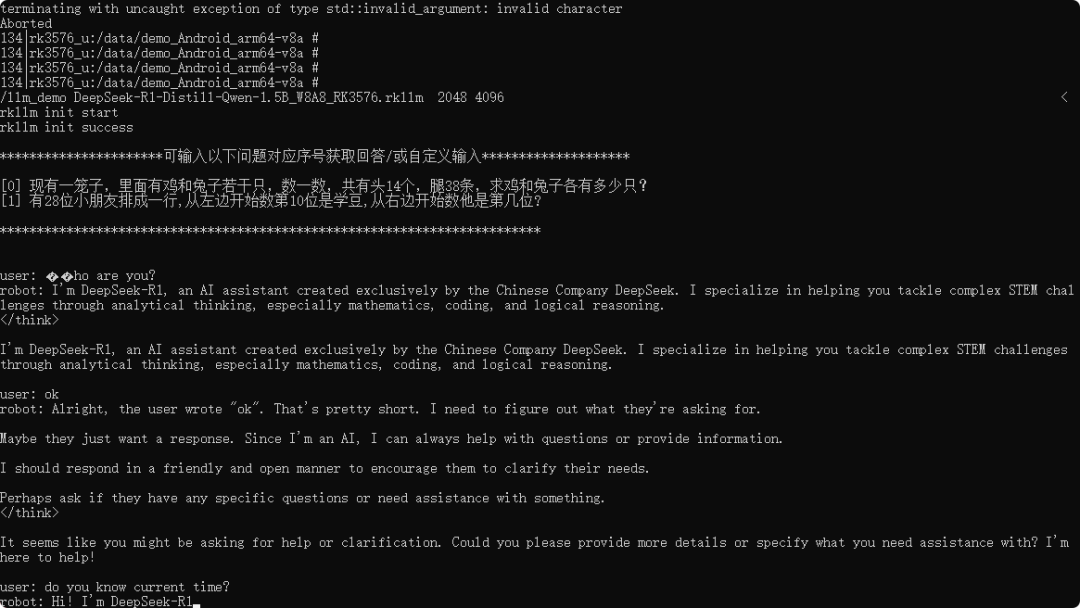
图18:DeepSeek-R1模型在RK3576开发板上成功运行,并与用户进行数学问题和自我介绍等对话。
可以修改 C语言源码,通过传入参数来实时获取对应的输出。
可以将 NPU 跑到 80% 使用率。
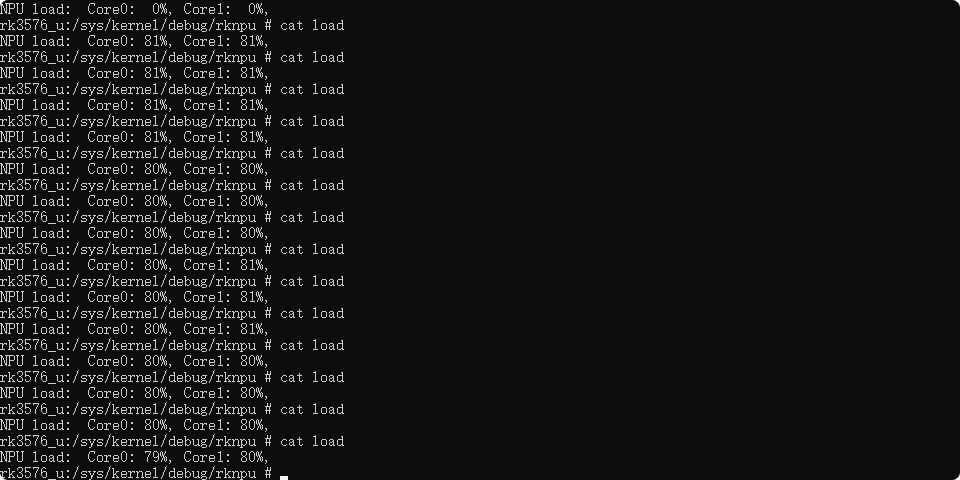
图19:通过查看/sys/kernel/debug/rknpu/load监控NPU各核心的实时负载情况。
源码分析与核心概念
# 参数含义依次为:模型地址,max_new_tokens,max_context_len
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3576.rkllm 2048 4096
- Max Tokens (max_new_tokens): 最大令牌数。
- 在进行推理(即模型生成文本)时,max_tokens 指定模型在停止生成之前可以生成的最大令牌(或词)的数量。
- 它限制了模型输出的长度,这不仅影响文本的详细程度,还影响到模型处理长篇内容的能力。
- Context Length (max_context_len): 上下文长度。
- 指的是模型在进行一次特定的推理时可以考虑的最大令牌数,即生成响应之前可以回顾和理解的输入内容的长度。
- 参数决定了模型可以记住和参考多少先前的信息。较长的上下文长度允许模型在生成响应时利用更多的历史信息。
- 两者数值需要平衡,更高数值需要更多的计算资源和更长的处理时间。
RKLLM Demo 源码分析
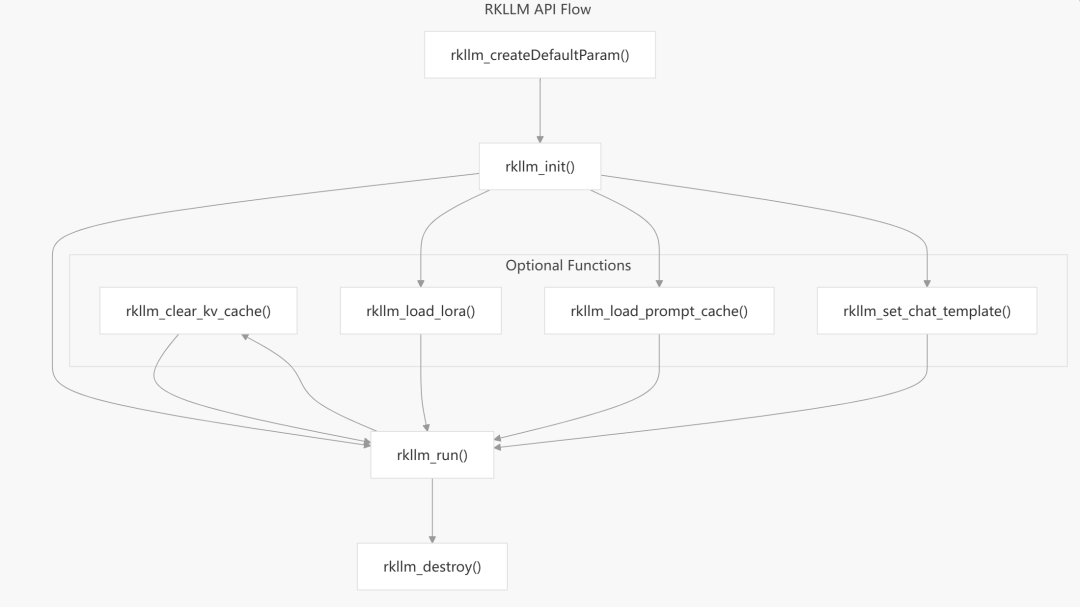
图20:RKLLM API标准调用流程,从初始化、可选功能配置、运行到销毁。

图21:RKLLMInput结构体定义,用于向模型传递提示文本(prompt)或令牌(token)输入。
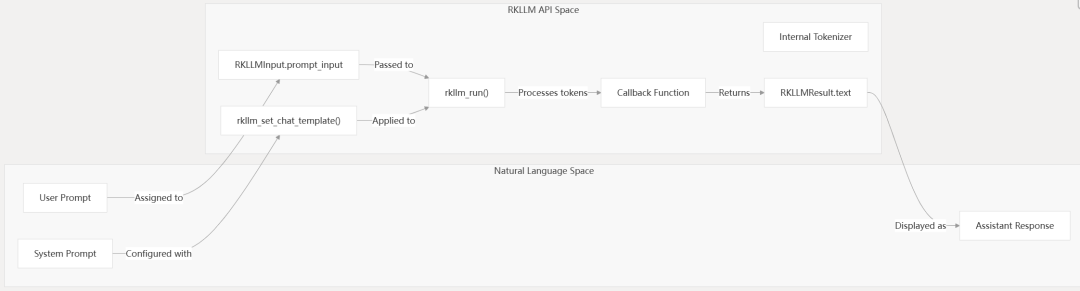
图22:展示了用户提示如何通过RKLLM API空间和内部处理,最终转换为助手响应的完整流程。
/*
handle : 指向将接收已初始化RKLLM实例的句柄的指针
param : 指向参数结构的指针
callback: 用于接收推理结果的函数指针
*/
int rkllm_init(LLMHandle *handle, RKLLMParam *param, RKLLMCallback callback);
// 成功时返回 0 否则返回非零错误代码
// 释放RKLLM实例关联的所有资源
void rkllm_destroy(LLMHandle handle);
/**
对输入使用输入模型进行推理
handle: RKLLM实例的句柄
input: 指向包含提示符或标记的输入结构的指针
infer_param:指向推理参数的指针,或NULL表示默认行为
userdata:传递给回调函数的用户自定义数据
**/
int rkllm_run(LLMHandle handle, RKLLMInput *input, RKLLMInferParam *infer_param, void *userdata);
/*
清除用于上下文跟踪的键值缓存
handle: RKLLM实例的句柄
clear_all:指示是否清除所有缓存的标志1 或不清除所有缓存 0
*/
int rkllm_clear_kv_cache(LLMHandle handle, int clear_all);
LoRA:低秩适应 (Low-Rank Adaptation) 是一种无需重新训练整个模型即可让大型机器学习模型适应特定用途的方法。
LoRA 为模型添加一个轻量级可修改的部分,使其适应新的环境或特定任务。LoRA 不会重新构建整个模型,而是会冻结模型的权重和参数,然后在原始模型之上,添加一个称为低秩矩阵的轻量级附加项,然后将其应用于新输入以获得特定于环境的结果。低秩矩阵会根据原始模型的权重进行调整。
/**
LoRA适应(低秩适应):允许在不修改模型原始权重的情况下对模型进行微调
handle: RKLLM实例的句柄
lora_adapter: 指向LoRa适配器配置的指针。
成功返回0 失败返回非零
**/
int rkllm_load_lora(LLMHandle handle, RKLLMLoraAdapter *lora_adapter);
/**
加载之前保存的提示符缓存
handle:RKLLM实例的句柄
prompt_cache_path:提示符缓存文件的路径
*/
int rkllm_load_prompt_cache(LLMHandle handle, const char *prompt_cache_path);
/**
配置聊天模版,用于格式化对话
handle: RKLLM实例的句柄
system_prompt:系统提示文本
user_prefix:用户消息前缀
assistant_prefix:助手消息的前缀
*/
int rkllm_set_chat_template(LLMHandle handle, const char *system_prompt, const char *user_prefix, const char *assistant_prefix);
/**
回调函数
result:指向结果结构的指针
userdata: 传递给用户定义的数据rkllm_run
state: 推理过程的状态
LLMCallState:
RKLLM_RUN_NORMAL正常生成进行中
RKLLM_RUN_FINISH:生成完成
RKLLM_RUN_ERROR:生成过程中发生错误
**/
typedef void(*RKLLMCallback)(RKLLMResult *result, void *userdata, LLMCallState state);
官方 demo 代码 (核心片段摘要)
#include<string.h>
#include<unistd.h>
#include<string>
#include"rkllm.h"
#include<fstream>
#include<iostream>
#include<csignal>
#include<vector>
using namespace std;
//初始化RKLLM实例句柄
LLMHandle llmHandle = nullptr;
// 退出的回调函数
void exit_handler(int signal)
{
if (llmHandle != nullptr)
{
{
cout << "程序即将退出" << endl;
LLMHandle _tmp = llmHandle;
llmHandle = nullptr;
rkllm_destroy(_tmp);
}
}
exit(signal);
}
// 回调函数,实时输出接收的结果
int callback(RKLLMResult *result, void *userdata, LLMCallState state)
{
if (state == RKLLM_RUN_FINISH)
{
printf("\n");
} else if (state == RKLLM_RUN_ERROR) {
printf("\\run error\n");
} else if (state == RKLLM_RUN_NORMAL) {
/* ================================================================================================================
若使用GET_LAST_HIDDEN_LAYER功能,callback接口会回传
内存指针:last_hidden_layer,
token数量:num_tokens
与隐藏层大小:embd_size
通过这三个参数可以取得last_hidden_layer中的数据
注:需要在当前callback中获取,若未及时获取,下一次callback会将该指针释放
===============================================================================================================*/
if (result->last_hidden_layer.embd_size != 0 && result->last_hidden_layer.num_tokens != 0) {
int data_size = result->last_hidden_layer.embd_size * result->last_hidden_layer.num_tokens * sizeof(float);
printf("\ndata_size:%d",data_size);
std::ofstream outFile("last_hidden_layer.bin", std::ios::binary);
if (outFile.is_open()) {
outFile.write(reinterpret_cast<const char*>(result->last_hidden_layer.hidden_states), data_size);
outFile.close();
std::cout << "Data saved to output.bin successfully!" << std::endl;
} else {
std::cerr << "Failed to open the file for writing!" << std::endl;
}
}
printf("%s", result->text);
}
return 0;
}
// 实例调用: ./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3576.rkllm 2048 4096
int main(int argc, char **argv)
{
if (argc < 4) {
std::cerr << "Usage: " << argv[0] << " model_path max_new_tokens max_context_len\n";
return 1;
}
// 注册退出信号
signal(SIGINT, exit_handler);
printf("rkllm init start\n");
//设置参数及初始化
RKLLMParam param = rkllm_createDefaultParam();
param.model_path = argv[1]; // 获取模型地址
//设置采样参数
param.top_k = 1;
param.top_p = 0.95;
param.temperature = 0.8;
param.repeat_penalty = 1.1;
param.frequency_penalty = 0.0;
param.presence_penalty = 0.0;
// 读取参数,设置 max_new_tokens 和 max_context_len
param.max_new_tokens = std::atoi(argv[2]);
param.max_context_len = std::atoi(argv[3]);
param.skip_special_token = true;
param.extend_param.base_domain_id = 0;
param.extend_param.embed_flash = 1;
// 初始化 RKLLM系统,设置参数和输出回调函数
int ret = rkllm_init(&llmHandle, ¶m, callback);
if (ret == 0){
printf("rkllm init success\n");
} else {
printf("rkllm init failed\n");
exit_handler(-1);
}
// 提供预设的问题程序
vector<string> pre_input;
pre_input.push_back("现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只?");
pre_input.push_back("有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位?");
cout << "\n**********************可输入以下问题对应序号获取回答/或自定义输入********************\n"
<< endl;
for (int i = 0; i < (int)pre_input.size(); i++)
{
cout << "[" << i << "] " << pre_input[i] << endl;
}
cout << "\n*************************************************************************\n"
<< endl;
//初始化RKLLMInput
RKLLMInput rkllm_input;
memset(&rkllm_input, 0, sizeof(RKLLMInput)); // 将所有内容初始化为 0
// 初始化 infer 参数结构体
RKLLMInferParam rkllm_infer_params;
memset(&rkllm_infer_params, 0, sizeof(RKLLMInferParam)); // 将所有内容初始化为 0
// 1. 初始化并设置 LoRA 参数(如果需要使用 LoRA)
// RKLLMLoraAdapter lora_adapter;
// memset(&lora_adapter, 0, sizeof(RKLLMLoraAdapter));
// lora_adapter.lora_adapter_path = "qwen0.5b_fp16_lora.rkllm";
// lora_adapter.lora_adapter_name = "test";
// lora_adapter.scale = 1.0;
// ret = rkllm_load_lora(llmHandle, &lora_adapter);
// if (ret != 0) {
// printf("\nload lora failed\n");
// }
// 加载第二个lora
// lora_adapter.lora_adapter_path = "Qwen2-0.5B-Instruct-all-rank8-F16-LoRA.gguf";
// lora_adapter.lora_adapter_name = "knowledge_old";
// lora_adapter.scale = 1.0;
// ret = rkllm_load_lora(llmHandle, &lora_adapter);
// if (ret != 0) {
// printf("\nload lora failed\n");
// }
// RKLLMLoraParam lora_params;
// lora_params.lora_adapter_name = "test"; // 指定用于推理的 lora 名称
// rkllm_infer_params.lora_params = &lora_params;
// 2. 初始化并设置 Prompt Cache 参数(如果需要使用 prompt cache)
// RKLLMPromptCacheParam prompt_cache_params;
// prompt_cache_params.save_prompt_cache = true; // 是否保存 prompt cache
// prompt_cache_params.prompt_cache_path = "./prompt_cache.bin"; // 若需要保存prompt cache, 指定 cache 文件路径
// rkllm_infer_params.prompt_cache_params = &prompt_cache_params;
// rkllm_load_prompt_cache(llmHandle, "./prompt_cache.bin"); // 加载缓存的cache
rkllm_infer_params.mode = RKLLM_INFER_GENERATE;
// By default, the chat operates in single-turn mode (no context retention)
// 0 means no history is retained, each query is independent
// 默认独立模式,不依赖上下文
rkllm_infer_params.keep_history = 0;
//The model has a built-in chat template by default, which defines how prompts are formatted
//for conversation. Users can modify this template using this function to customize the
//system prompt, prefix, and postfix according to their needs.
// rkllm_set_chat_template(llmHandle, "", "<|User|>", "<|Assistant|>");
// 该模型默认内置了一个聊天模版,用于定义提示词在对话中的格式,用户可以通过修改此函数修改模版,
// 根据自身需求自定义系统提示词,前缀和后缀
while (true)
{
std::string input_str;
printf("\n");
printf("user: ");
std::getline(std::cin, input_str); //读取用户输入文本
if (input_str == "exit")
{
break;
}
if (input_str == "clear")
{
ret = rkllm_clear_kv_cache(llmHandle, 1, nullptr, nullptr);
if (ret != 0)
{
printf("clear kv cache failed!\n");
}
continue;
}
for (int i = 0; i < (int)pre_input.size(); i++)
{
if (input_str == to_string(i))
{
input_str = pre_input[i];
cout << input_str << endl;
}
}
rkllm_input.input_type = RKLLM_INPUT_PROMPT;
rkllm_input.role = "user";
rkllm_input.prompt_input = (char *)input_str.c_str();
printf("robot: ");
// 若要使用普通推理功能,则配置rkllm_infer_mode为RKLLM_INFER_GENERATE或不配置参数
rkllm_run(llmHandle, &rkllm_input, &rkllm_infer_params, NULL);
}
rkllm_destroy(llmHandle);
return 0;
}
参考资料与扩展学习
参考资料
附加学习
本文详细记录了在Rockchip NPU平台上部署AI模型的完整流程,涵盖了从环境搭建、模型转换到真机部署与源码分析的方方面面。希望这份基于实践的技术指南能帮助更多开发者快速上手嵌入式人工智能应用开发。如果你在部署过程中遇到问题,或想了解更多底层细节,欢迎在云栈社区的相关板块进行讨论。
 发表于 2025-12-30 04:08:47
|
查看: 424|
回复: 0
发表于 2025-12-30 04:08:47
|
查看: 424|
回复: 0
