
图1:AWS Trainium3芯片,专为下一代生成式AI工作负载设计
2025年底,亚马逊 AWS 发布的 Trainium3 芯片,给白热化的 AI 算力战场投下了一枚重磅炸弹。
一、开场暴击:Trainium3 凭什么搅动算力江湖?
这款基于台积电 3nm 工艺的“性能怪兽”,单芯片 FP8 算力飙至 2.52 PFLOPs(约 2520 TFLOPS),较上一代直接暴涨 4.4 倍;144GB HBM3e 显存搭配 4.9TB/s 带宽,创下当前行业最高引脚速度纪录。更令人瞩目的是,由 144 颗芯片组成的 UltraServer 集群,能攒出 362 PFLOPs 算力、20.7TB 显存的“超级计算机”,直接瞄准数万亿参数大模型的训练需求。
Anthropic、Decart 等早期用户已经给出实锤:训练成本砍半,视频生成速度是传统 GPU 的 4 倍。这款芯片的横空出世,不仅是亚马逊自研芯片的里程碑,更预示着云厂商与专业芯片巨头的正面战场,正式拉开序幕。
二、技术拆解:3nm 架构里藏着哪些黑科技?
Trainium3 的强悍性能,绝非单纯堆料的结果,而是从核心引擎到系统架构的全链路创新。
1. 计算核心:MXFP 精度革命与算力倍增
Trainium3 搭载的 NeuronCore-v4 引擎,是性能跃升的关键。与上一代相比,它新增了两大杀招:
- MXFP 混合精度技术:支持 MXFP8 和 MXFP4 两种自定义精度格式,能将 BF16 数据无损量化,在保证模型精度的前提下,把算力利用率拉满 —— 这让其 FP8 算力达到 2517 TFLOPS,是 Trainium2 的两倍;
- Softmax 硬件加速:内置快速指数运算单元,吞吐量是普通 Scalar 引擎的 4 倍,专门解决 Transformer 模型中 Attention 机制的计算瓶颈,推理响应速度直接提升 4 倍。
8 个 NeuronCore-v4 引擎协同工作,再加上对 4:16 到 1:2 全范围稀疏矩阵的硬件支持,让 Trainium3 在大模型训练时既能“猛算”又能“巧算”。
2. 内存突破:破解大模型的“带宽焦虑”
大模型训练的核心痛点是“内存墙”—— 数据在显存与计算核心间的搬运速度,往往比计算本身更慢。Trainium3 直接用硬件暴力破解:
- 12 层堆叠 HBM3e:把显存容量从 Trainium2 的 64GB 翻倍至 144GB,引脚速度从 5.7Gbps 提至 9.6Gbps,带宽飙升至 4.9TB/s,相当于每秒能传输 2000 部高清电影的数据量;
- 片上 SRAM 扩容:每个 NeuronCore-v4 集成 32MB SRAM,比上一代增加 14%,高频数据不用反复调取显存,进一步降低延迟。
这种“大显存 + 高带宽”的组合,让 Trainium3 处理 10 万亿参数模型时,不用频繁进行数据分片,训练效率直接提升 3 倍以上。
3. 互连架构:144 颗芯片的“无延迟协作”
单芯片再强,集群协同拉胯也是白搭。Trainium3 的 NeuronSwitch-v1 互联方案,彻底解决了大规模集群的通信瓶颈:
- 芯片间带宽翻倍:每个芯片配备 4 个 NeuronLink-v4 接口,双向带宽达 2.56 TB/s,是上一代的两倍;
- 全连接集群拓扑:单个 UltraServer 能将 144 颗芯片连成一体,跨芯片通信延迟压到 10 微秒以内,比谷歌 TPU v7p 的集群延迟还低 20%;
- 超大规模扩展:通过 EC2 UltraClusters 3.0 网络,能将 集群扩展到数十万颗芯片,支撑全球最大规模的分布式训练。
4. 系统设计:从芯片到液冷的协同思维
亚马逊的野心不止于芯片本身,而是打造“芯片 - 服务器 - 散热”的闭环方案:
- 异构计算单元:每个计算托架集成 4 颗 Trainium3 和 1 颗 Graviton4 CPU,算力与控制效率最大化;
- 液冷刚需配置:单台 UltraServer 功耗超 60kW,必须搭配板级直冷或两相浸没式液冷,才能将温度锁定在 85℃ 以下,这也倒逼数据中心基础设施升级。
三、友商对决:Trainium3 能硬刚英伟达吗?
要评判 Trainium3 的真实战力,必须拉上英伟达、谷歌这些对手同台 PK。我们从性能、成本、生态三个维度做次硬碰硬的对比:
1. 性能硬碰硬:各有胜负的“单项冠军”
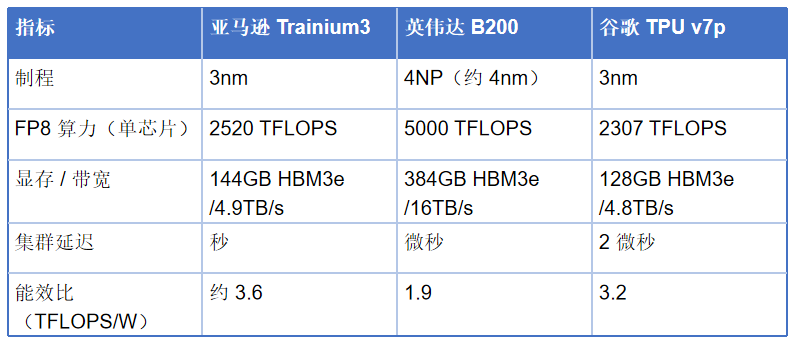
图2:Trainium3、英伟达B200、谷歌TPU v7p关键性能指标对比
数据可见,英伟达 B200 在绝对算力和显存带宽上仍占优势,但 Trainium3 凭借 3nm 工艺实现了更高能效比,集群延迟表现更优 —— 在需要大规模扩展的 MoE 模型训练中,Trainium3 的综合效率反而领先 15%-20%。
2. 成本杀手锏:云厂商的“主场优势”
对企业用户来说,成本往往比参数更重要。Trainium3 的定价策略直击英伟达的软肋:
单卡成本:Trainium3 单芯片采购成本约为 B200 的 60%,而 144 芯片集群的总投入比同算力 GPU 集群低 40%;
使用成本:AWS EC2 Trn3 实例的小时租金,比搭载 B200 的 p5 实例便宜 30%,长期训练能省出数百万美元;
隐性成本:内置的内存压缩、稀疏计算优化,进一步降低了数据存储和传输开销,Anthropic 透露其训练成本直接砍半。
这种成本优势,源于亚马逊“芯片 - 云服务”的垂直整合能力 —— 不用像英伟达那样追求硬件利润最大化,而是通过低价吸引用户,靠云服务生态赚钱。
3. 生态短木板:离“替代 GPU”还有距离
不过,Trainium3 并非完美无缺,其最大短板仍是软件生态:
模型适配范围:目前对主流 LLaMA、GPT-OSS 的适配已成熟,但对小众模型或自定义算子的支持不足,开发者需用 Neuron SDK 重构部分代码;
通用性局限:作为 ASIC 专用芯片,Trainium3 在 AI 训练外的通用计算场景(如科学计算)表现乏力,而英伟达 GPU 能覆盖更多元需求。
这一点上,谷歌 TPU 也面临类似困境,二者都难以撼动英伟达在通用 AI 算力市场的统治地位。
四、行业影响:算力市场要变天了?
Trainium3 的登场,不止是一款芯片的胜利,更标志着 AI 算力市场进入“三国杀”时代。
1. 云厂商主导的“算力垂直整合”成新趋势
亚马逊用行动证明:云厂商做芯片,根本不是“玩票”。通过“自研芯片 + 云服务 + 生态”的闭环,既能降低对英伟达的依赖,又能通过差异化算力服务锁定客户。
微软的 Maia 100、谷歌的 TPU v7p 早已跟进,未来云厂商的竞争,将从“服务易用性”下沉到“算力底层架构”—— 谁能提供更便宜、更高效的定制化算力,谁就能掌握 AI 时代的入场券。
2. 英伟达的“霸权松动”与应对
面对 Trainium3 们的挑战,英伟达并非无动于衷:一方面加速推出 GB200 等更强性能的芯片,另一方面通过 CUDA 生态绑定开发者,同时联合微软、Oracle 等云厂商推出“GPU + 云服务”套餐,用生态壁垒抵消硬件成本劣势。
但不可否认的是,云厂商自研芯片已经撕开了一道口子 —— 在 Anthropic、Meta 等超大规模用户的采购清单里,Trainium3、TPU 正逐渐占据一席之地,英伟达的市场份额首次出现下滑迹象。
3. 企业选型:该选 GPU 还是云厂商 ASIC?
对企业来说,现在的算力选型更像“选择题”而非“必答题”:
- 选 Trainium3/TPU:适合长期在 AWS / 谷歌云平台运行 LLaMA、GPT 等主流大模型的企业,能显著降低成本,且对定制化需求不高;
- 选英伟达 GPU:适合需要多场景适配、依赖自定义算子,或已深度绑定 CUDA 生态的企业,尤其在科学计算 + AI 融合场景中不可替代;
- 混合架构:像 Decart 这样的初创公司,已经开始用 Trainium3 做模型训练,用 GPU 做推理优化,兼顾成本与灵活性。
五、结语:算力战争的终局是生态战争
Trainium3 的横空出世,再次印证了一个真理:AI 算力的竞争,早已不是“谁的芯片参数更高”,而是“谁能提供从芯片到应用的全栈解决方案”。
亚马逊用 3nm 工艺、MXFP 精度、集群互连的技术组合,证明了云厂商在算力硬件上的实力;但英伟达凭借 CUDA 生态的护城河,仍牢牢占据行业主导地位。这场战争没有捷径,也没有终点。
对我们普通人来说,这场算力军备竞赛的最大受益者,终将是每一个 AI 应用的使用者 —— 毕竟,更便宜、更高效的算力,才能让大模型真正走进千家万户。
更多AI与云计算深度讨论,欢迎访问云栈社区。
 发表于 2025-12-30 04:47:57
|
查看: 252|
回复: 0
发表于 2025-12-30 04:47:57
|
查看: 252|
回复: 0
