复盘一场字节跳动的高级开发面试,其中涉及一个经典的生产级难题:如何从一个存有10亿条日志的Elasticsearch集群中,快速且安全地全量导出数据?
候选人从最初的错误思路,到进阶方案,再到最终被面试官点出性能瓶颈,整个过程揭示了处理海量ES数据导出时必须跨越的三个核心关卡。
一、 入门级陷阱:强行突破10000条限制
面对“导出10亿数据”的需求,许多开发者的第一反应是使用 from+size 进行分页。然而,这是ES手册中明确警告的操作,因为默认深度分页限制在10000条。此时,有人可能会想:修改 index.max_result_window 配置不就行了?
但这恰恰是第一个,也是最危险的陷阱。
当查询深入到第1000万条数据时,协调节点需要每个数据分片都返回前1000万条数据,然后在内存中对 1000万 * 分片数 的数据进行全局排序和合并。对于协调节点而言,这无异于用一个小容量的漏斗去承接海量的水。
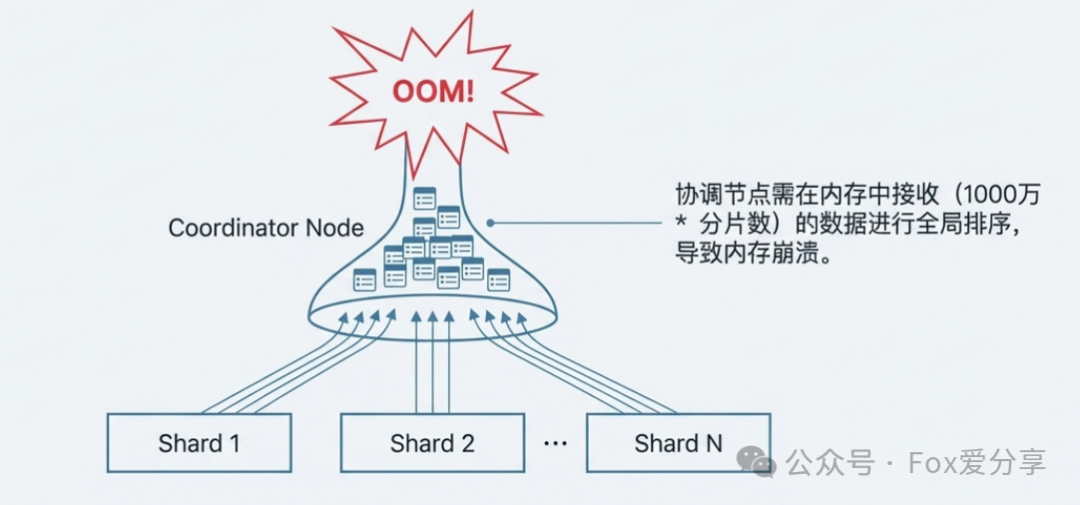
图1:协调节点(Coordinator Node)因需在内存中对海量分片数据进行全局排序而引发OOM
结果就是集群性能急剧下降,轻则抛出 Result window is too large 异常,重则导致协调节点OOM,整个集群宕机。
二、 进阶瓶颈:单线程游标的性能天花板
既然 from+size 行不通,官方推荐的深分页方案 SearchAfter 便成为自然的选择。它通过维护一个游标进行O(1)跳转,不占用大量内存,似乎完美解决了问题。
但这引出了第二个关卡:无法接受的时间成本。
让我们从架构师的角度进行一次容量预估:
- 数据总量:10亿条。
- 批处理大小:每次查询1000条(兼顾效率与网络开销)。
- 单次请求耗时:约0.2秒(包含内网RTT、ES查询fetch以及结果反序列化)。
- 总请求次数:10亿 / 1000 = 100万次。
- 总耗时估算:
100万次 * 0.2秒 = 200,000秒 ≈ 55.5小时。
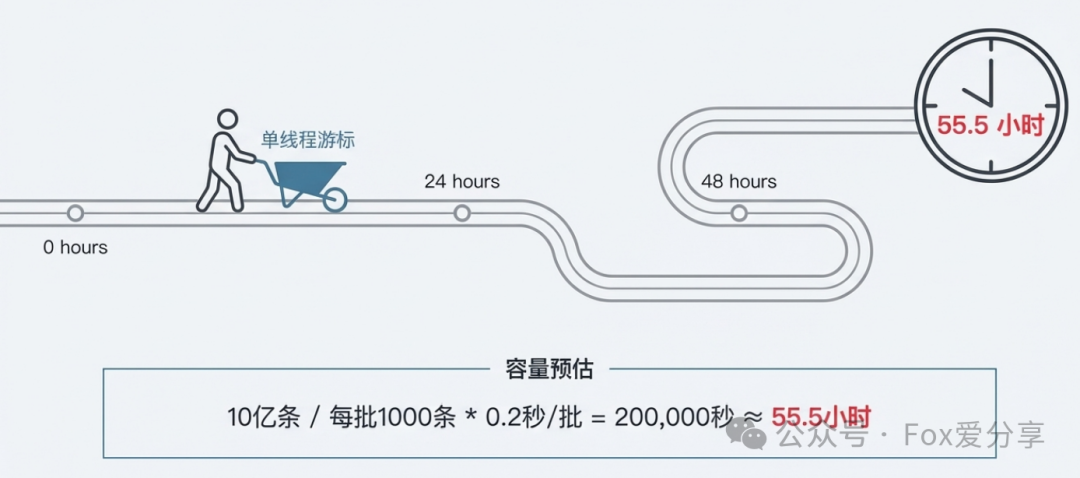
图2:单线程游标方案处理10亿数据,预估耗时长达55.5小时
近两天半的导出时间,对于任何需要实时或准实时数据分析的业务场景来说都是不可接受的。这就像用独轮车去搬运一座小山,即便不累垮,工程也早已延误。
三、 生产级方案:PIT + Slice 并行切片加速
真正的生产级解决方案,必须采用“空间换时间”的策略。在Elasticsearch 7.10+版本中,结合 PIT(Point In Time) 和 Slice(切片) 功能,可以实现安全高效的并行导出。
核心原理如下:
- 创建PIT快照:首先,使用PIT API创建一个数据视图的时间点快照。这是保证数据一致性的关键,确保在导出过程中,即使有新的数据写入或旧数据删除,所有并行线程处理的数据集仍然是同一时刻的快照。
- 进行数据切片:将整个PIT快照视图逻辑上切分为N个切片(Slice)。一个最佳实践是将切片数量设置为索引的主分片数量。如果主分片数量过多(例如超过20),可以酌情减少,例如设置为
CPU核心数 * 2,以避免创建过多并发任务。
- 并行处理:启动多个线程或进程,每个处理一个独立的切片,从而实现真正的并行加速。
通过此方案,总耗时可以从单线程的55.5小时大幅压缩至数小时(例如2.5小时),效率提升超过20倍。
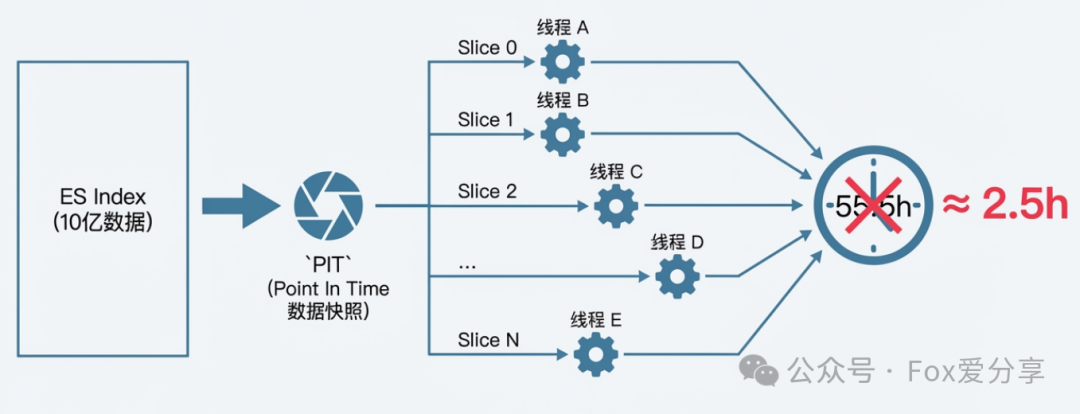
图3:通过PIT快照与切片技术,将单线程任务并行化,显著缩短导出时间
核心实现代码示例
以下是一个基于Java High Level REST Client的并行导出核心逻辑示例:
/**
* 基于 ES 7.10+ 的并行导出方案
* 警告:生产环境务必配置好 RestClient 的 SocketTimeout,建议设为 30 秒
*/
public void parallelExport(String indexName, int primaryShards, RedisTemplate redisTemplate) throws IOException {
// 1. 动态确定 Slice 数量:对齐主分片数,最多不超过 20
int totalSlices = Math.min(primaryShards, 20);
// 2. 【核心】创建全局 PIT,初始存活 10 分钟(避免网络波动导致过期)
String pitId = client.openPointInTime(new OpenPointInTimeRequest(indexName)
.keepAlive(TimeValue.timeValueMinutes(10))).getPointInTimeId();
// 3. 【优化线程池】避免任务堆积内存溢出
ExecutorService executor = new ThreadPoolExecutor(
totalSlices, // 核心线程数
totalSlices * 2, // 最大线程数
60L, TimeUnit.SECONDS, // 空闲线程存活时间
new ArrayBlockingQueue<>(100), // 有限任务队列,防止无限堆积
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:主线程兜底执行,避免任务丢失。注意:生产环境建议自定义策略
);
try {
for (int i = 0; i < totalSlices; i++) {
int sliceId = i;
String finalPitId = pitId;
executor.submit(() -> exportSlice(sliceId, totalSlices, finalPitId, redisTemplate));
}
executor.shutdown();
// 等待所有任务完成,超时 4 小时(预留充足时间)
if (!executor.awaitTermination(4, TimeUnit.HOURS)) {
// 超时未完成,记录未完成切片
redisTemplate.opsForSet().add("es_export_timeout_slices", "index:" + indexName + ",slices:" + totalSlices);
}
} finally {
// 【关键点 1】必须强制关闭 PIT,哪怕任务失败
closePit(pitId);
// 优雅关闭线程池
if (!executor.isShutdown()) {
executor.shutdownNow();
}
}
}
/**
* 单个切片导出,含重试、IO 优化、失败记录
*/
private void exportSlice(int sliceId, int totalSlices, String pitId, RedisTemplate redisTemplate) {
Object[] lastSortValues = null;
int retryCount = 3; // 最多重试 3 次
String exportKey = "es_export_slice_" + sliceId;
while (retryCount > 0) {
// 【优化 1】BufferedWriter + 分布式存储优先,避免本地磁盘瓶颈
try (BufferedWriter writer = getExportWriter(sliceId)) {
while (true) {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.size(1000)
// 【性能优化】_doc 排序:按磁盘顺序读,效率是时间排序的数倍
.sort("_doc", SortOrder.ASC)
.slice(new SliceBuilder(sliceId, totalSlices))
// 【集群友好】设置查询优先级为 LOW,不抢占业务查询资源
.priority(Priority.LOW)
// 【优化】优先查询本地分片,减少节点间数据传输
.preference("_local");
// 续用上一次的排序位置
if (lastSortValues != null) {
searchSourceBuilder.searchAfter(lastSortValues);
}
// 【关键点 2】PIT 续命 + 兜底:每次请求续期 10 分钟
searchSourceBuilder.pointInTimeBuilder(new PointInTimeBuilder(pitId)
.keepAlive(TimeValue.timeValueMinutes(10)));
SearchRequest request = new SearchRequest();
request.pointInTimeBuilder(new PointInTimeBuilder(pitId));
request.source(searchSourceBuilder);
// 执行查询
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
if (hits.length == 0) break;
// 批量写入,减少 IO 调用
for (SearchHit hit : hits) {
writer.write(hit.getSourceAsString());
writer.newLine();
}
// 记录当前进度(用于监控)
long currentCount = response.getHits().getTotalHits().value;
redisTemplate.opsForValue().set(exportKey, currentCount);
// 更新下一次的排序位置
lastSortValues = hits[hits.length - 1].getSortValues();
}
// 导出成功,标记完成
redisTemplate.opsForSet().add("es_export_success_slices", sliceId + "");
retryCount = 0; // 退出重试
} catch (Exception e) {
retryCount--;
log.error("Slice {} 导出失败,剩余重试次数 {}", sliceId, retryCount, e);
if (retryCount == 0) {
// 重试耗尽,记录失败切片,用于后续人工处理
redisTemplate.opsForSet().add("es_export_failed_slices", sliceId + "");
}
// 重试前睡眠 1 秒,避免高频重试加剧集群压力
try { Thread.sleep(1000); } catch (InterruptedException ie) {}
}
}
}
四、 生产环境进阶考量
1. 进度监控与容错
对于长时间运行的导出任务,完善的监控和容错机制必不可少:
- 进度统计:每个切片将当前导出数量实时写入Redis。
- 独立监控线程:定期汇总所有切片进度,计算整体完成百分比。
- 可视化与告警:将进度数据接入Prometheus/Grafana看板。设定规则,如某切片长时间无进度或失败切片过多,触发告警。
2. 常见疑问与架构权衡
- 为何不用Kibana导出? Kibana适用于数据可视化与即席查询,其聚合结果为近似值,且无法满足复杂的、需要原始数据(如关联分析、模型训练)的导出需求。
- 为何不用Spark/Flink? 对于单纯的批量数据搬运,轻量级的应用级多线程方案成本更低。若导出过程伴随复杂的ETL清洗、多表关联,则应考虑Spark等大数据框架。架构选择本质是成本与收益的权衡。
- ES 6.x 版本如何实现? 6.x版本不支持PIT,可使用
Scroll + Slice 作为替代。但需警惕:Scroll上下文消耗堆内存,切片数最好等于主分片数,且任务结束后必须调用 ClearScroll API清理上下文,防止内存泄漏。
- 多线程写文件的IO瓶颈? 如果所有线程并发写入同一块机械硬盘,会造成磁头争用,形成“假并行”。优化方案包括:使用
BufferedWriter 缓冲、将不同切片写入不同物理磁盘、或优先采用流式上传至OSS/HDFS等分布式存储系统。
五、 面试应答逻辑梳理
在面试中回答此类问题,可以遵循以下逻辑,展现系统性思考:
- 识别陷阱:首先否定
from+size 及其修改配置的方案,指出其存在深度分页限制和引发OOM的风险。
- 分析瓶颈:肯定
SearchAfter 在内存安全性上的优势,但指出其单线程模式下,处理10亿量级数据耗时过长(约55小时),无法满足业务时效性要求。
- 提出方案:阐述采用 PIT + Slice 并行导出 作为最终方案。说明通过创建一致性快照(PIT)和逻辑切片,实现了并行化,将耗时压缩到小时级别。
- 展现深度:补充生产级细节,如切片数量与主分片对齐、使用受限队列的自定义线程池防止内存溢出、通过Redis记录进度与实现重试兜底、设置查询优先级为LOW以保障集群业务不受影响等。
总结
从规避OOM,到突破性能瓶颈,再到实现并行化与生产兜底,处理Elasticsearch海量数据导出问题,是一个典型的从开发者到架构师的思维跃迁过程。技术方案没有绝对的银弹,关键在于根据具体场景(数据量、时效性、资源成本)做出最合理的权衡与设计。掌握此类数据库中间件的高阶用法,是后端工程师迈向资深和架构师岗位的重要阶梯。更多深入的技术讨论与实践分享,欢迎在云栈社区与大家交流。
 发表于 2025-12-30 21:34:12
|
查看: 336|
回复: 0
发表于 2025-12-30 21:34:12
|
查看: 336|
回复: 0
