通过强化学习训练的大语言模型智能体在解决复杂多步骤任务方面展现出巨大潜力。然而,其性能常常受限于上下文爆炸问题:随着任务复杂度提升,智能体需频繁调用外部工具查询,产生冗长的检索输出。现有方法通常将这些结果直接拼接到上下文中,这对模型的上下文管理能力提出了极高要求,而模型有限的上下文窗口在处理冗长输入时又会限制其推理能力。
为应对这一挑战,佐治亚理工学院与阿里巴巴联合提出了一种新颖的分层智能体框架CoDA。该框架通过解耦高层策略规划与底层任务执行,有效缓解了上下文过载问题。研究团队还配套提出了一种端到端的强化学习策略PECO,能够协同优化规划器与执行器两个角色。在复杂的多跳问答基准测试中,CoDA取得了SOTA性能,准确率较现有最佳方法最高提升了6.0%。在长上下文场景下,当其他基线方法性能严重下降时,CoDA仍能保持稳定表现,这充分验证了其分层设计在缓解上下文过载方面的有效性。
图:CoDA论文标题页,展示了作者及所属机构信息。

方法
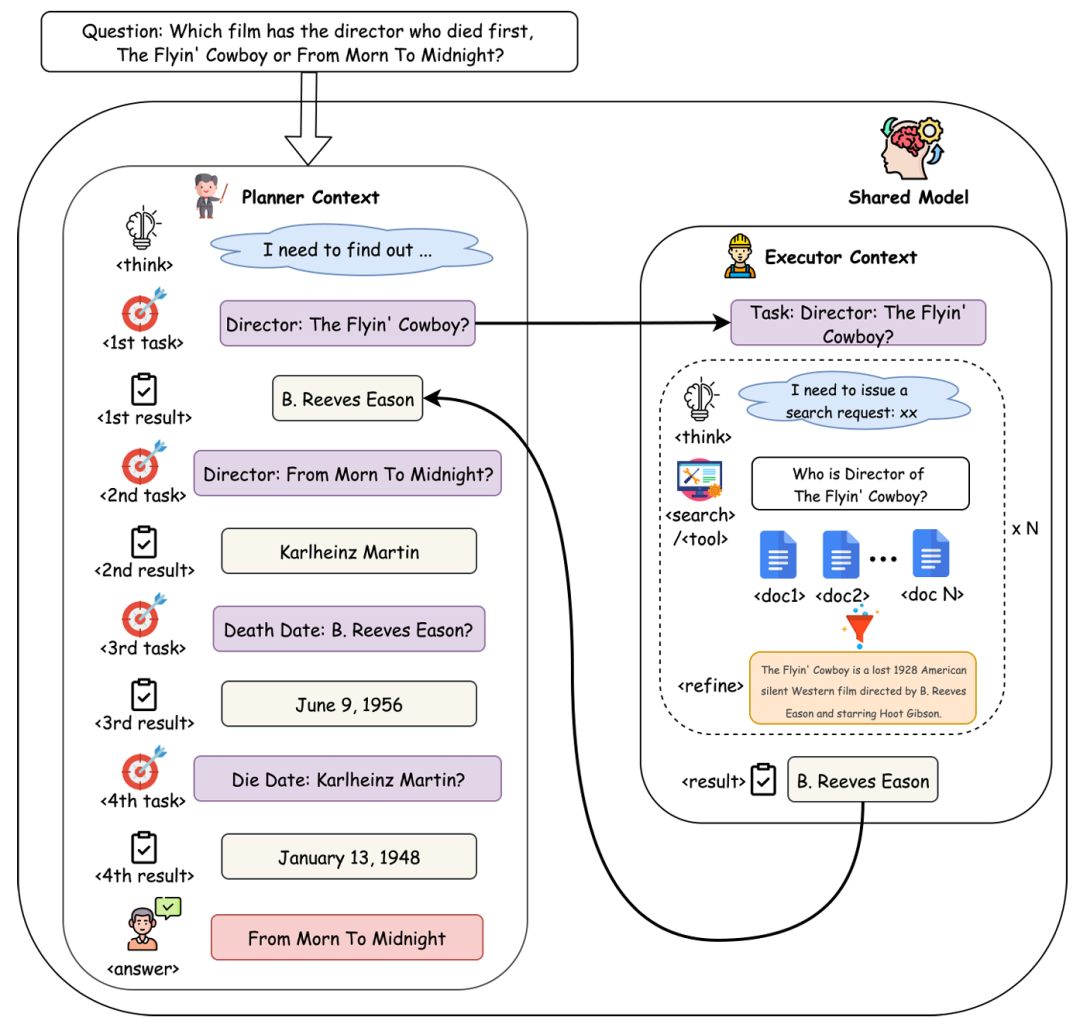
图1:CoDA框架工作流程。一个共享模型同时充当规划器(左侧)来分解任务,并作为执行器(右侧)在隔离上下文中处理工具调用。
研究团队的核心洞察是:要克服上下文过载,需要一个既能从结构上分离高层规划与底层执行、又具备整体可学习性的框架。
受“分而治之”原则启发,他们提出了分层智能体框架CoDA。其核心思想是将单一决策过程分解为两个协同工作但上下文隔离的角色:规划器和执行器。这两个角色由同一个模型 π_θ 实现,但在不同的上下文中运行。
-
规划器:作为高级策略制定者,在一个简洁的策略上下文 C_P 中运行。其职责是生成子任务或最终答案。策略上下文仅包含高层信息:
C_P = {Q, (task_1, result_1), ..., (task_{t-1}, result_{t-1})}
在每个步骤 t,规划器生成下一个子任务 task_t = π_θ(C_t)。当判断信息足够时,该过程终止,规划器会将收集的结果综合为最终答案。
-
执行器:作为专注的任务处理者,在一个临时执行上下文 C_E 中运行。它接收来自规划器的单个任务 task_t,并负责通过工具调用完成它。其内部流程如下:
- 初始化:
C_E ← {task_t}。
- 执行:调用工具以检索原始文档
D_t。
- 提炼:对原始文档
D_t 进行总结,生成简洁摘要 s_t = Refine(D_t)。
- 结论:基于提炼后的信息,生成最终结果
result_t 返回给规划器。
关键在于,冗长的原始文档 D_t 不会进入规划器的策略上下文 C_P。执行器充当黑盒模块,自动屏蔽掉嘈杂细节,实现了有效的上下文解耦。
强化学习策略PECO
研究团队采用基于GRPO算法的结果监督式强化学习方法,对CoDA框架进行端到端训练。其核心策略是:运用单一轨迹级奖励来更新共享策略模型 π_θ,同时确保每个token的梯度计算都基于其所属角色的特定上下文。
-
分层轨迹生成:
- 规划器从用户查询开始,生成思考步骤和一个动作(待委派的
<task> 或最终 <answer>)。
- 若生成
<task>,则启动独立的执行器子循环。该会话仅用该子任务初始化,与规划器历史隔离。在此上下文中,模型作为执行器迭代生成 <search> 动作、接收结果并推理,直至为该子任务生成 <answer>。
- 执行器生成的最终答案被封装为
<result> 返回给规划器。
- 收集所有生成的序列,标记为 ‘planner‘ 或 ‘executor‘,构成一个轨迹组
G。
-
组级信用分配:
每个查询生成 k>1 条独立轨迹。所有源自同一查询的轨迹构成轨迹组 G,并计算标量奖励 R(G)。遵循GRPO原理,通过将每个组的奖励与其同伴组的统计值归一化来实现信用分配。第 i 组的优势 A(G_i) 计算如下:
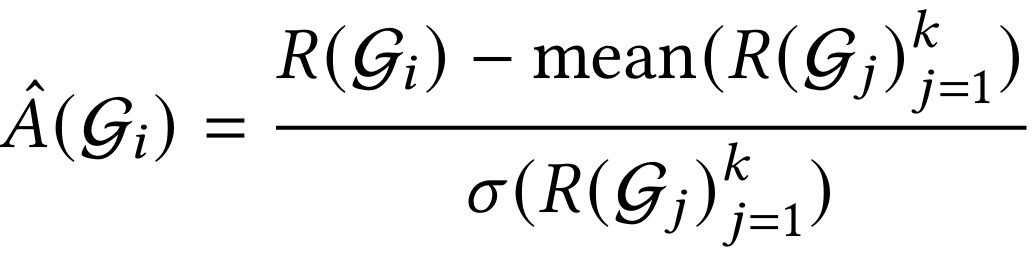
该优势值统一应用于轨迹组 G_i 中所有策略生成的token,确保中间步骤动作的价值能根据其对最终成功的贡献被合理评估。
-
基于损失掩码的上下文依赖策略更新:
尽管优势信号统一,但策略更新以逐个token的方式进行,并通过损失掩码确保模型仅从自身动作中学习,而非环境观察。采用GRPO的目标函数来更新策略 π_θ:
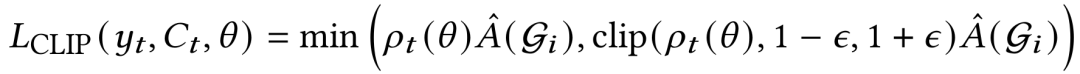
其中,ρ_t(θ) = π_θ(y_t|C_t) / π_θ_old(y_t|C_t) 是重要性采样比率。
策略 π_θ 的整体学习目标是最大化GRPO的替代目标函数 J(θ),并通过KL散度正则项约束其与参考策略 π_θ_ref 的差异:
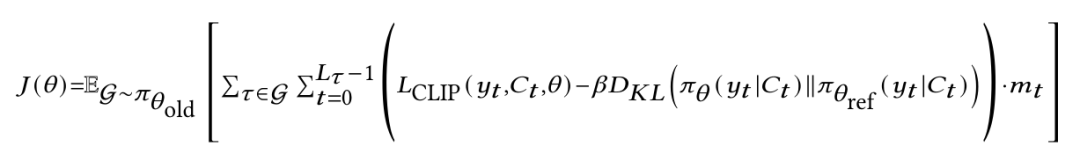
其中,掩码 m_t 是实现动作-观察分离的关键:智能体自身生成的动作token(m_t=1)参与损失计算;而来自环境的观察token(如 <result> 块、<documents> 块,m_t=0)则被掩码掉。
-
复合奖励设计:
为了引导模型掌握所需复杂行为,设计了一种复合奖励函数 R(G),同时激励三个目标:
R(G) = R_ans(G) + R_format(G) + R_refine(G)
- 答案正确性
R_ans:基于规划器生成的最终答案与真实答案集之间的F1分数。
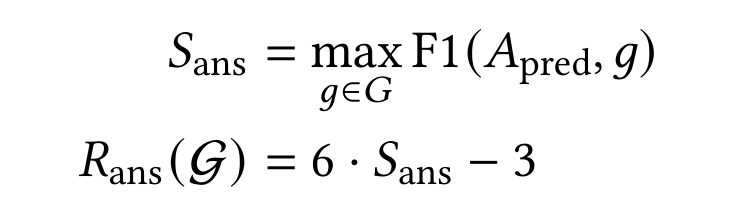
- 格式合规性
R_format:奖励智能体生成正确格式的XML风格标签。
R_format(G) = I_P(G) + I_E(G)
其中,I_P(G) 和 I_E(G) 分别是规划器和所有执行器输出格式正确的指示函数。
- 提炼质量
R_refine:激励执行器从嘈杂搜索结果中提炼关键信息。该奖励检查提炼内容是否非空且包含真实答案。
s_combined = ⊕ s_i = s_1 ⊕ s_2 ⊕ ... ⊕ s_m
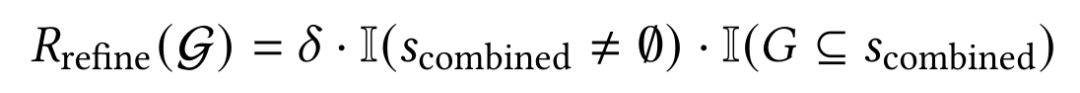
评估
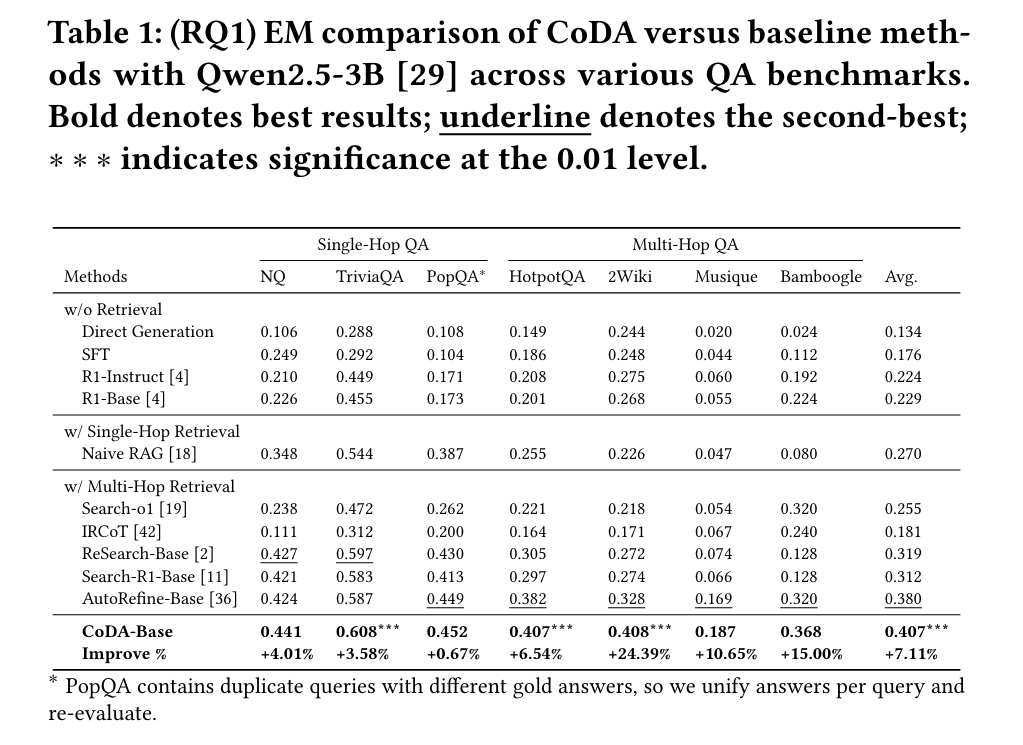
表1:CoDA与基线方法在多个问答基准上的EM分数对比。CoDA-Base取得了0.407的最高平均分。
在七个不同的问答基准测试上,CoDA-Base展现出SOTA性能。其优势在复杂的多跳问答场景中尤为明显。CoDA始终以显著优势超越所有基线方法,在2WikiMultiHopQA和Musique这两个需要复杂跨文档推理的数据集上,相较于强大的AutoRefine基线,分别实现了高达24%和10%的性能提升。
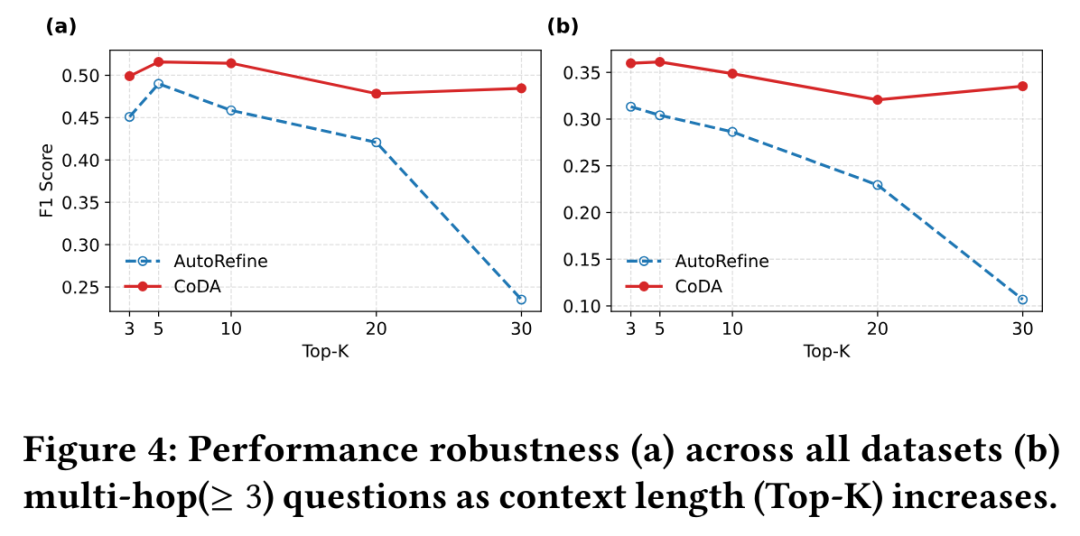
图4a:随着检索文档数量(Top-K)增加,CoDA性能保持稳定,而AutoRefine显著下降。
为评估CoDA应对“上下文爆炸”的稳健性,研究团队进行了鲁棒性测试:通过增加检索工具的top-k参数来模拟信息过载。结果显示,CoDA在所有k值下均表现出极强的稳定性。而AutoRefine基线的性能则随文档数量增加持续下降,F1分数相对下降达52%。CoDA的鲁棒性直接源于其上下文解耦设计——冗长信息在执行器层被隔离和提炼,避免了对高层规划的干扰。
在3-4跳的复杂问题上,CoDA的优势进一步凸显。
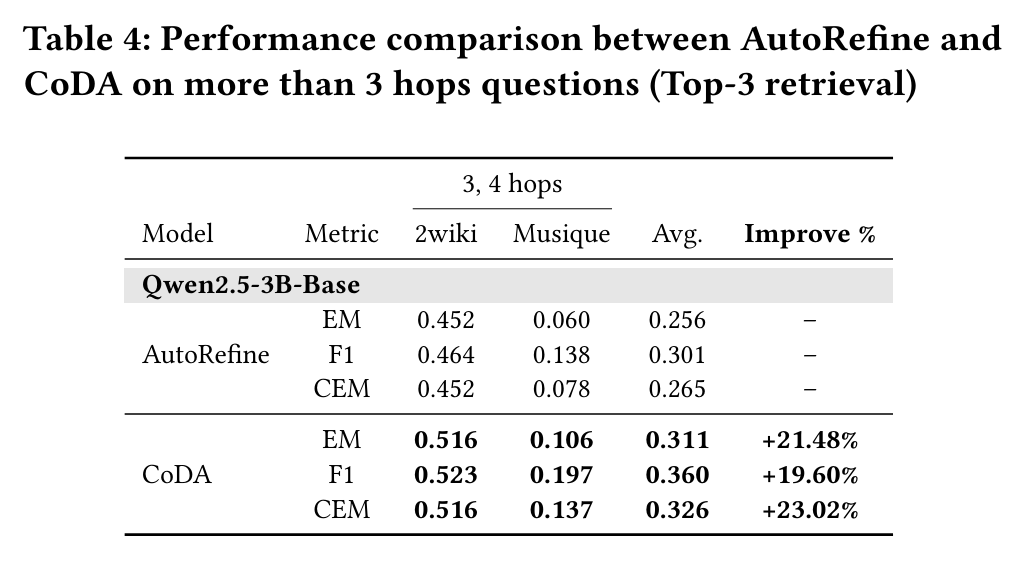
表4:在超过3跳的问题上,CoDA在EM、F1、CEM指标上均显著优于AutoRefine。
在多跳问答任务中,上下文过载问题尤为严峻,多步骤检索的信息会累积放大噪声。在需要超过3个推理跳数的问题上,CoDA显著优于AutoRefine,在两个多跳数据集上实现了EM平均相对提升+21.48%,F1提升+19.60%,CEM提升+23.02%。
总的来说,以AutoRefine为代表的单智能体方法在多跳长上下文下性能急剧下降,因为每跳的原始文档不断污染其上下文。相比之下,CoDA展现出卓越的鲁棒性。其分层架构将含噪声的长上下文信息隔离在执行器的临时工作空间中,执行器仅输出简洁摘要,规划器则始终保持一个干净、高层的策略上下文。这种解耦机制有效防止了信息稀释,保障了推理质量。即使在多跳推理叠加大量上下文的极端挑战下,CoDA依然能维持稳定且强劲的性能。
本文讨论的分层智能体与强化学习技术,是当前AI研究的前沿方向。对这类话题感兴趣的开发者,欢迎前往 云栈社区 的人工智能板块,获取更多深度技术解读与开源项目资源。
 发表于 2025-12-31 02:46:28
|
查看: 301|
回复: 0
发表于 2025-12-31 02:46:28
|
查看: 301|
回复: 0
