赚钱很难,但亏钱很快。黑产的脚本一秒钟能跑一千次。做反欺诈,必须实时。今天就来探讨一下,如何利用 Flink 将风控系统的响应速度提升至毫秒级。
过去,很多公司依赖 Hadoop/Hive 构建离线数仓进行风控分析。这种方式通常是每天凌晨跑批处理任务,到了第二天早上才能看到前一天的异常数据。当面对盗刷、高频交易或薅羊毛等场景时,这种滞后的分析模式毫无还手之力,等到发现异常,损失往往已经无法挽回。
事后追责意义有限,风控的核心在于 阻断,关键决策往往需要在 200 毫秒内完成。计算特征、匹配规则、运行模型,所有流程都必须在瞬间完成,以决定是放行、拦截还是发起二次验证。这正是实时流计算的战场。
Flink 作为一款原生流处理框架,在应对风控这类对时效性要求极高的场景时,具有天然的优势。
状态管理 (State)
风控逻辑非常依赖对历史行为的记忆。例如,判断一个用户在过去1小时内的登录失败次数。Flink 的 State 机制能够将这些历史数据高效地存储在任务节点的本地内存或外部存储(如 RocksDB)中,读取速度极快。同时,其 Checkpoint 容错机制保证了状态数据在故障时不丢失、不重复,这比在高并发场景下频繁查询外部存储(如 Redis)要高效得多。
窗口计算 (Window)
风控策略离不开基于时间窗口的统计。例如,计算用户过去5分钟的交易总额,或者统计最近10次操作的平均时间间隔。Flink 提供了丰富且强大的窗口机制,能够精准处理乱序到达的数据,无论是滚动窗口、滑动窗口还是会话窗口,都能开箱即用。
复杂事件处理 (CEP)
单个用户行为可能看似正常,但一系列行为组合起来就可能暴露风险。例如,一个账户短时间内发生“异地登录 -> 修改密码 -> 发起大额转账”这一连串事件,就很可能是盗号洗钱的典型模式。使用传统 SQL 难以优雅地描述这种连续的、带有状态的模式,而 Flink CEP 可以用几行代码就定义并检测此类复杂事件序列。
架构实战
一个健壮的实时风控系统,其核心架构通常可以抽象为三层:Source(数据源)、Process(实时计算)、Sink(决策输出)。
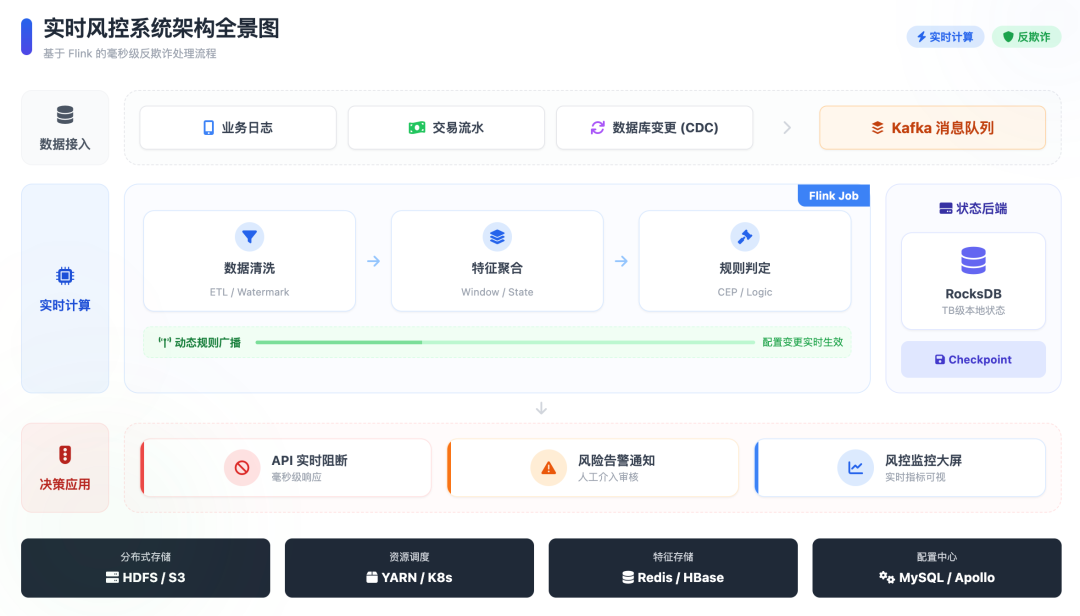
图1:基于Flink的毫秒级实时风控系统架构图,展示了从数据接入到决策反馈的全流程。
数据源层
这一层负责采集所有相关的业务日志和交易流水,包括登录、注册、下单、支付、转账等事件。这些数据通常会统一写入高吞吐的消息队列,如 Kafka,以实现海量数据的稳定接入与缓冲。
实时计算层
这是 Flink 发挥核心价值的环节,主要包含三个步骤:
- 数据清洗:过滤无效或格式错误的数据,对字段进行标准化处理,确保后续计算的准确性。
- 特征计算:结合实时数据流与用户的历史状态(State)进行聚合计算,生成实时特征。例如,计算用户当前会话的转账频率、常用设备或地理位置的变化等。
- 规则匹配:将计算出的实时特征与预定义的风险规则(阈值、CEP模式等)进行比对,触发相应的风控策略。
决策应用层
计算层产生的结果需要立即作用于业务:
- 实时阻断:通过 API 接口 同步返回
Pass 或 Reject 等指令给业务系统,在交易链路中实现毫秒级拦截。
- 风险告警:对于高风险但未达到自动阻断标准的行为,触发告警系统,通过钉钉、短信等方式通知风控人员人工审核。
CEP 模式匹配逻辑
以检测“暴力破解”为例,规则可定义为:10秒内,连续出现3次登录失败事件,且紧接着出现1次成功事件。
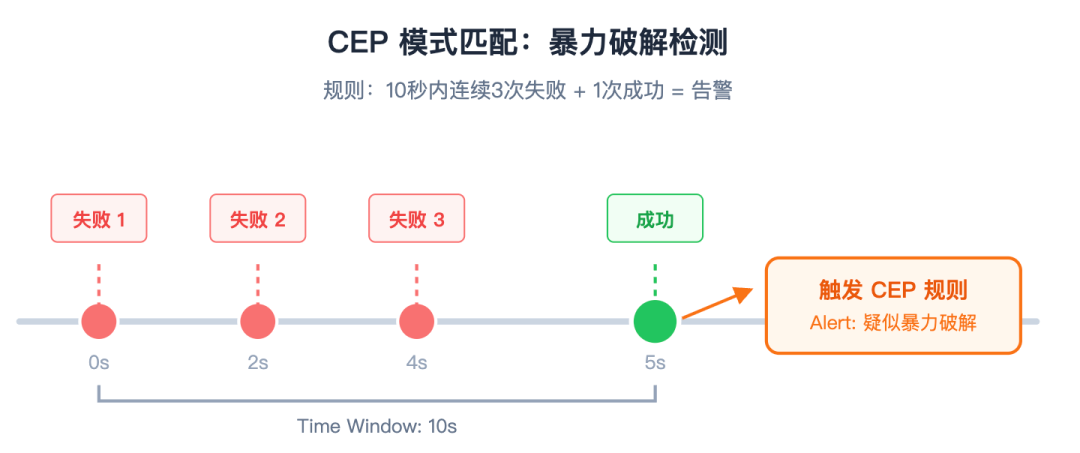
图2:CEP规则示意图,展示10秒内“失败-失败-失败-成功”的事件序列如何触发告警。
Flink CEP 引擎会在数据流中持续监测。一旦发现某个用户的事件流符合上述“失败->失败->失败->成功”的严格顺序,并且所有事件发生在10秒的时间窗口内,系统会立即触发告警(Alert),判定为疑似暴力破解攻击。这种方式远比编写冗长的 if-else 逻辑判断更加清晰和高效。
动态规则与状态管理
在生产环境中,还需要解决两个关键问题:规则的动态更新和海量状态的管理。
规则如何动态更新?
黑产手段不断变化,风控规则也需要快速调整。如果每次修改规则都要重启 Flink 作业,会严重影响服务的可用性。
解决方案是利用 Flink 的 Broadcast State 模式。

图3:动态规则广播流程图,展示了规则从管理台到Flink任务毫秒级生效的全过程。
当运营人员在管理后台修改规则后,新规则首先被存入数据库。随后,变更数据捕获(CDC)工具会实时将这一变更同步到消息队列(如Kafka)的特定 Topic 中,形成一个“规则变更流”。Flink 任务会实时消费这个流,并将最新的规则广播给所有并行的 TaskManager 实例。当处理交易数据时,每个数据都能立即应用最新的规则进行判断,从而实现规则的热更新,整个过程延迟极低。
状态过大怎么办?
对于拥有上亿用户的平台,如果将每个用户长时间的行为状态都保存在内存中,很容易导致 JVM 内存溢出(OOM)。
解决方案是组合使用 RocksDBStateBackend 和 状态 TTL。
- 将 Flink 的 State Backend 配置为 RocksDB,将状态数据存储在本地磁盘上,内存仅作为缓存,从而支撑更大的状态数据量。
- 为状态设置 TTL 过期时间。例如,只保留用户最近24小时的行为数据进行计算,超时的旧状态会自动清理,有效防止状态无限膨胀占用资源。
实时风控是企业资产至关重要的“防盗门”,而 Flink 为打造这扇坚固、灵敏的大门提供了核心材料。通过其强大的状态管理、窗口计算和复杂事件处理能力,我们能够构建一个能实时感知、快速计算、智能决策的风控大脑。无论技术如何演进,风控的终极目标始终不变:比黑产更快一步。
希望这篇关于 Flink 在实时风控中应用的分享对你有帮助。想了解更多关于 大数据 和实时计算的实战内容,欢迎持续关注云栈社区的技术文章。
 发表于 2025-12-31 06:14:30
|
查看: 390|
回复: 0
发表于 2025-12-31 06:14:30
|
查看: 390|
回复: 0
