5.1 语言模型

5.1.1 统计语言模型
统计语言模型的核心是基于统计学方法来计算和估计文本序列中单词或词组的出现概率。其中,传统方法通常依赖 n-gram 模型来实现这一目标。
n-gram 模型的相关介绍可回顾本系列第4讲的4.1小节。

5.1.2 神经网络语言模型 (NNLM)
神经网络语言模型利用神经网络架构来预测文本序列中的下一个词。相较于传统统计方法,NNLM 通过学习海量文本数据中词汇间的复杂概率关系,能够更有效地捕捉语言的深层结构和上下文语境,从而生成更连贯、更符合语义的文本。
1. NNLM 模型结构
NNLM的核心任务是:给定第t个词之前的n-1个词作为上下文,预测词典中每个词出现在第t个位置的概率。其数学表达式为:
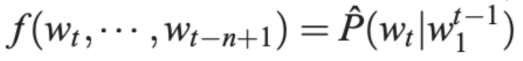
图2:NNLM的条件概率公式
其中,函数 f 的输出大于0,且所有可能结果的概率之和为1。根据经典论文《A Neural Probabilistic Language Model》的描述,NNLM 通常包含一个三层神经网络结构,其模型框架如下:
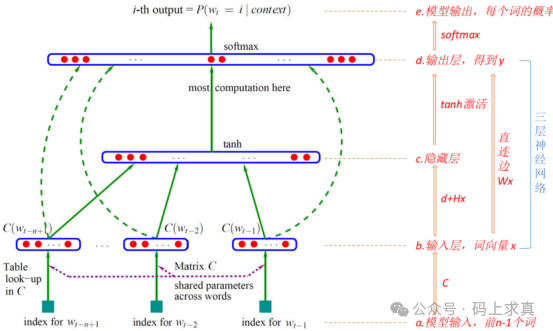
图3:NNLM模型结构示意图
模型的具体工作流程可分为以下几步:
- 模型输入:输入为位置t之前的n-1个词。通过查找一个词向量矩阵 C,将每个输入词转换为对应的词向量。矩阵C的维度为 V×m,其中 V 是语料库总词数,m 是词向量的维度。
- 输入层:将上一步得到的n-1个词向量首尾拼接,形成一个整合后的向量 x。
- 隐藏层:这是一个全连接层,计算过程为
tanh(d + Hx)。其中 d 是偏置项,H 是权重矩阵,tanh 是激活函数。
- 输出层:隐藏层的输出会经过另一个全连接层映射到输出空间。此外,从输入层到输出层存在一个线性变换直连边(实验表明加入直连边有助于加速收敛)。最终得到位置t上对应 V 个词语的未归一化对数概率 y。其计算公式为:
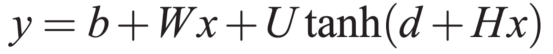
图4:NNLM输出层计算公式
其中,U 是维度为 V×h 的矩阵(h为隐藏层单元数),W 是直连边的权重矩阵,若无需直连边则 W 为0。
- 模型输出:将输出层的结果 y 送入 Softmax 函数,得到归一化后的概率分布,即词典中每个词作为下一个词出现的概率。
2. 模型训练目标及参数
在NNLM中,不仅神经网络的权重需要训练,其输入——词向量本身也是需要学习的参数。因此,NNLM的训练是词向量与模型参数同步优化的过程。
-
模型参数: NNLM 的所有可训练参数集合为:
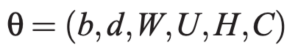
图5:NNLM模型参数集合
-
训练目标: NNLM 的训练目标是最大化训练语料上的对数似然函数。该目标函数同时包含了模型预测的准确性和可能的正则化项 R(θ),以防止过拟合:
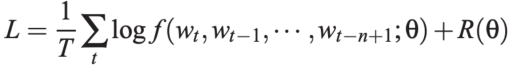
图6:NNLM训练目标函数
参数通过随机梯度下降法进行更新:
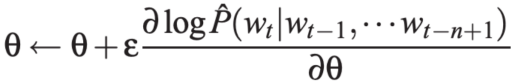
图7:参数更新公式

图8:动态示意图
5.2 注意力机制 (Attention Mechanism)
Attention 机制的引入,使得模型在处理信息时能够“看到”并聚焦于全局上下文中更相关的部分,而不仅仅是局部或固定窗口的信息。
5.2.1 通俗理解 Attention
人类在观察场景时,视觉系统会本能地忽略大量冗余信息,而将有限的注意力资源集中在关键区域上。例如,看一幅人像时,我们会更关注面部;阅读文章时,视线会优先落在标题和首句。这种选择性关注机制极大地提升了信息处理效率。
深度学习中的注意力机制借鉴了这一思想。其核心是在处理输入信息时,动态地为不同部分分配不同的重要性权重,让模型能够聚焦于与当前任务最相关的“关键信息”,从而提升模型的性能和可解释性。
5.2.2 基本原理
注意力机制可以形式化地理解为一种“软性”的寻址过程。给定一个查询(Query),通过计算它与一系列键(Key)的相似度,得到每个键对应值(Value)的权重,最后对这些值进行加权求和,得到注意力输出值。
其核心计算过程涉及三个核心概念:
- Source(源): 由一系列
<Key, Value> 键值对构成,可以看作是待查询的信息库。
- Query(查询): 代表当前需要关注什么的请求。
- Attention Value(注意力值): 根据Query和Key的相似度,对Value进行加权求和后的结果,它融合了源信息中与查询最相关的部分。
注意力机制的计算公式抽象地表示为:
Attention(Query, Source) = Σ Similarity(Query, Key_i) * Value_i
注意力机制的核心在于权重系数 Similarity(Query, Key_i) 的计算,它决定了不同 Value 对最终输出的贡献大小。权重越大,表示对应的 Value 信息越重要。
5.2.3 注意力机制的计算过程
标准的注意力计算通常分为三个阶段:
-
第一阶段:计算相似度得分
计算 Query 与每个 Key 的相似性或相关性,得到原始得分。常用的计算方法包括点积、Cosine相似性,或通过一个小的神经网络(MLP)来学习。
图9:相似度计算方法(点积、Cosine、MLP)
-
第二阶段:得分归一化
对第一阶段得到的原始得分进行归一化处理,通常使用 Softmax 函数将其转化为权重系数(所有系数之和为1)。这既保证了权重的概率化解释,也放大了重要得分的影响。
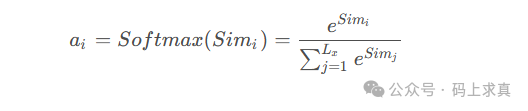
图10:Softmax归一化公式
-
第三阶段:加权求和
使用归一化后的权重系数对对应的 Value 进行加权求和,得到最终的 Attention Value。
Attention(Query, Source) = Σ a_i * Value_i
5.2.4 注意力机制的分类
注意力机制可以根据不同的标准进行分类。
1. 按可微性分类
- 硬注意力 (Hard-Attention): 一种随机性的注意力,对输入区域的选择是“非0即1”的决策过程(如选择图像中某个精确坐标)。由于其不可微,通常需要使用强化学习等方法进行训练。
- 软注意力 (Soft-Attention): 一种确定性的注意力,为输入的所有部分分配一个
[0,1]之间的连续权重。它是可微的,可以直接通过标准的反向传播算法进行端到端训练,是目前最主流的注意力形式。
2. 按关注域分类
- 空间注意力 (Spatial Attention): 关注特征图在二维空间(高度、宽度)上不同位置的重要性。通常通过对通道维度进行池化(如MaxPool, AvgPool),再结合卷积操作来生成空间权重图。
图11:空间注意力模块示意图
- 通道注意力 (Channel Attention): 关注特征图在不同通道(特征维度)上的重要性。典型方法如SENet,通过对特征通道进行全局池化,再经过MLP学习通道间的依赖关系,生成通道权重。
图12:通道注意力模块示意图
- 其他: 还有层注意力、混合域注意力、时间注意力等变体,应用于更复杂的网络结构或时序数据。
5.2.5 基于 Encoder-Decoder 的注意力机制
在传统的 Encoder-Decoder 框架(如早期用于机器翻译的RNN模型)中,编码器将整个输入序列压缩为一个固定长度的语义向量 C,解码器再基于这个单一的C生成输出。这种方式存在信息瓶颈,所有输入词对解码的贡献被均等看待,可以视为一个“分心模型”。
引入注意力机制后,解码器在生成每一个输出词时,都可以动态地访问编码器输出的所有隐藏状态,并为这些状态分配不同的注意力权重。这意味着,语义表示不再是单一的 C,而是一系列根据当前解码状态动态加权求和的 {C1, C2, ...}。这极大地提升了模型处理长序列和捕捉远距离依赖的能力,并成为了现代NLP模型(如Transformer)的核心组件。
本文深入剖析了语言模型从统计方法到神经网络,再到注意力机制的演进核心,希望能帮助你构建清晰的认知脉络。更多前沿技术讨论,欢迎访问云栈社区。
 发表于 2025-12-31 06:36:43
|
查看: 336|
回复: 0
发表于 2025-12-31 06:36:43
|
查看: 336|
回复: 0
