如果你正在开发一个具备“动手”能力的AI智能体(Agent),很快就会面临一个绕不开的现实:它想干活,就得操作文件;而文件操作,往往是风险的源头。
你希望它能帮你写代码、改配置、跑脚本、整理目录。但你也担心它“一激动”删除了关键文件、窃取了敏感信息,或者将系统环境搞得一团糟。这时,一套精心设计的架构图便显得至关重要:它并非简单地将组件堆砌在一起,而是清晰地指明了——在赋予智能体动手能力的同时,如何将潜在的危险关进笼子里。
你可以将这套设计的核心思想概括为一句话:所有的文件操作都被约束在一个被层层隔离的安全空间内,它能够完成工作,但绝无可能触及你的系统核心命脉。
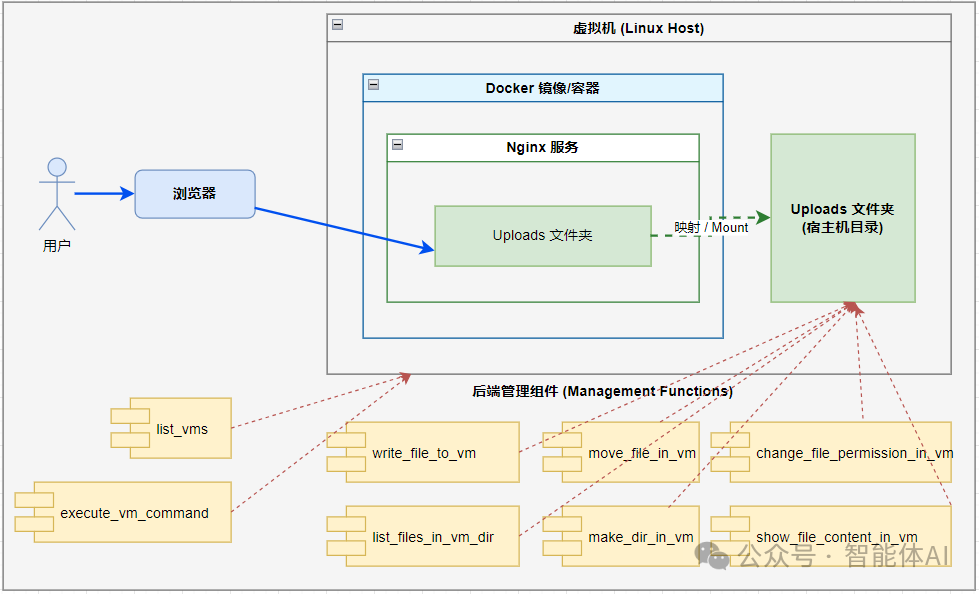
图1:AI智能体安全沙盒五层隔离架构示意图,展示了从用户界面到数据存储的完整安全链路。
一、逐层解码:智能体沙盒的“五重结界”
这套架构最具借鉴价值之处,在于它将“智能体的操作能力”一步步限制在五道明确的边界之内。每一道边界都承担着具体的安全职责。
第 1 重:用户界面层——浏览器背后的指令通道
架构的起点是“用户 → 浏览器”。这一层的安全意义常被低估。
因为所有潜在的危险操作,必须有一个清晰、可追踪的入口:
- 用户在网页中的每一次点击、上传和指令发送。
- 系统如何将这些行为转换为智能体可理解的任务。
- 每一个动作是否能够被回放、审计和追责。
这一层如果设计得当,后续每一层的安全状态都能被“清晰溯源”。如果设计不当,后续的隔离措施也可能演变为无法观测的黑盒。
第 2 重:虚拟化层——Linux 虚拟机的“安全屋”
图中最大的虚线框:虚拟机(Linux),这就是整个沙盒的“安全屋”。
为什么需要这一层?因为它提供了一种硬件级的强隔离:
- 智能体的所有操作,其影响范围主要被限制在虚拟机内部。
- 即使虚拟机崩溃或环境被污染,只需快速重建即可恢复。
- 最关键的是,虚拟机和宿主机之间,存在天然的、坚固的边界。
而 Lima 这类工具的价值在于:它让你能够在 Mac 等平台上,以“轻松、可控”的方式创建这个 Linux 安全屋,无需从零开始手动配置复杂的虚拟化细节。
你可以将其理解为:先将所有危险操作从“宿主机”转移出去,放入一个可随时拆卸与重建的独立工作间。
第 3 重:容器化层——Docker 的“隔离舱”
如果说虚拟机是“房子”,那么 Docker 容器就像是“房子里的独立隔间”。
容器化解决的是另一组问题:环境一致性、快速启动和精细的资源控制。
- 使用相同的镜像,在任何机器上都能复现一致的运行结果。
- 可以为每个容器单独限制 CPU、内存使用量,防止智能体耗尽系统资源。
- 出现问题直接删除容器并重启,过程干净利落。
虚拟化提供了“重量级隔离”,而容器化(Containerization)则提供了“轻量级隔离”。两者结合的意义在于:先用虚拟机将宿主机保护起来,再用容器将内部服务拆解为更可控、更易复制的单元。
第 4 重:服务层——Nginx 的“接待前台”
在许多架构图中,Nginx 仅被视为“一个 Web 服务器”。但在智能体沙盒中,它扮演着“前台接待员 + 安全门卫”的双重角色。
它主要完成三件重要的事:
- 接收外部请求(例如处理来自浏览器的文件上传)。
- 将请求路由到正确的服务或目录(防止上传路径被滥用为任意文件写入入口)。
- 执行第一层安全策略(限制上传文件大小、校验路径、记录访问日志,并在需要时进行身份鉴权)。
简而言之:智能体服务不应直接暴露在互联网上,Nginx 负责抵挡并过滤第一波流量。
第 5 重:数据层——Uploads 文件夹的“映射魔法”
图中那条绿色的虚线箭头“映射 ->”,是整个设计中最“优雅也最易出错”的部分。
它通常意味着:Docker Volume(或 bind mount)。
你需要这个映射,是因为:
- 用户上传的文件需要落盘到一个“容器能够访问”的位置。
- 容器生成的结果需要能够被外部系统获取或预览。
- 但你绝对不希望容器拥有随意读写宿主机任意目录的权限。
因此,正确的做法是:仅映射必要的目录(例如 Uploads/),让容器“只能看到它应该看到的”,完全隔绝其访问其他系统目录的可能。
这就是“文件操作间”的核心逻辑:给它一张工作台、一套限定工具、一扇观察窗,但绝不提供整栋建筑的钥匙。
二、智能体的“武器库”:八大文件操作接口解析
沙盒环境搭建完成后,智能体的能力来自于一组明确定义的“工具接口”。你可以将它们视为智能体的手脚,但这些手脚必须佩戴“手套”,并遵循既定流程。
下面按照实际工作流,将这些接口分为四类进行解析。
1)侦查类:智能体的“眼睛”
2)核心执行类:智能体的“大脑和双手”
execute_vm_command:在虚拟机内部执行 Shell 命令。
这是能力上限最高、同时也是风险最高的接口。其危险性在于:一旦命令执行被放开,智能体就可能因“手滑”造成破坏。
建议从一开始就建立严格的规则:- 仅允许在特定的工作目录内执行命令(例如
/workspace)。
- 建立命令白名单(如
node, python, npm, pytest, ls, cat)。
- 默认禁止网络访问(需要时再通过审批机制开放)。
- 设置超时限制、输出长度截断以及 CPU/内存/磁盘资源配额。
示例:
execute_vm_command(vm, cwd=“/workspace/site”, cmd=“npm test”)
你会发现:智能体并不需要“root 权限”,它需要的是“足以完成任务的最小权限”。
3)文件操作类:智能体的“创作工具”
这类接口最贴近日常开发:创建、查看、移动文件。
write_file_to_vm:创建或覆盖文件(用于编写代码、配置文件)。
write_file_to_vm(vm, “/workspace/site/index.html”, html_text)
show_file_content_in_vm:查看文件内容(用于需求分析、结果复盘)。
spec = show_file_content_in_vm(vm, “/uploads/brand-guideline.md”)
move_file_in_vm:移动或重命名文件(用于整理项目结构、归档产出物)。
move_file_in_vm(vm, “/workspace/site/tmp/logo.png”,
“/workspace/site/assets/logo.png”)
这三类接口的共同原则是:操作路径必须受控、作用范围必须收敛、每一次写入都必须有日志记录。
4)系统管理类:智能体的“权限钥匙”
最后两个工具如同“专用钥匙”,平时未必频繁使用,但在关键时刻必不可少。
make_dir_in_vm:创建目录(用于搭建项目结构)。
make_dir_in_vm(vm, “/workspace/site/assets”)
change_file_permission_in_vm:修改文件权限(部署前经常需要)。
change_file_permission_in_vm(vm, “/workspace/site/start.sh”, “755”)
为什么智能体需要修改权限?典型的应用场景包括: - 生成了需要执行的脚本文件。
- 生成了需要被 Web 服务读取的静态文件。
- 需要严格区分“可写目录”与“只读目录”。
正确的做法并非“授予其全部权限”,而是:让它在必要时“申请并获得特定的、必要的权限”,在其他时间则遵循权限最小化原则。
三、实战推演:智能体创建企业官网的完整流程
假设用户提出需求:“我需要一个企业官网,风格简洁现代,能够展示产品、团队和联系方式。”
智能体如何在沙盒中安全地完成这个任务?你可以将此流程视为一条可复现的流水线。
步骤 1:用户上传设计稿与文案
文件流向:浏览器 → Nginx → Uploads 映射目录
在此阶段,文件尚未进入“执行环境”,只是被安全地接收和存储。
步骤 2:智能体接收任务,先侦查再理解
list_files_in_vm_dir:定位已上传的素材文件。show_file_content_in_vm:读取文案、需求文档或设计规范。
步骤 3:开始创作(在工作区生成项目)
make_dir_in_vm:搭建项目目录结构(如 /workspace/site, assets, css, js)。write_file_to_vm:生成 index.html、CSS 样式表、JavaScript 脚本等。
步骤 4:调试与优化
execute_vm_command:在本地启动预览服务、运行代码检查(lint)、执行构建命令。move_file_in_vm:将生成的资源文件整理到正确的位置。
步骤 5:权限调整与最终交付
change_file_permission_in_vm:确保部署脚本等文件具有可执行权限。- 最终,通过 Nginx 提供静态文件服务,用户即可在浏览器中预览完整的网站效果。
整个过程的关键在于:每一个步骤都发生在“五重结界”之内,你可以在任意环节清晰地定位并实施安全检查。
四、架构优势:安全、可观测与可复现
1)与“直接在宿主机运行智能体”的对比
直接在宿主机上运行智能体通常伴随以下问题:
- 误删关键文件、污染全局环境、滥用系统权限。
- 一旦发生事故,恢复可能需要数小时甚至数天。
- 难以保证团队成员拥有完全一致的运行环境。
沙盒架构的核心逻辑则是:将风险集中到可隔离、可快速重建、可全面审计的独立区域内。
2)三大核心工程优势
- 安全性:虚拟机 + 容器 + 最小化目录映射,形成了清晰的多层防御边界。
- 可观测性:从用户入口、文件上传、命令执行到文件写入,全链路操作均可被记录和审计。
- 可复现性:基于容器镜像定义环境,可以在任何机器上复现完全相同的操作流程。
3)良好的可扩展性
当前的架构可能只包含 Nginx 和文件上传目录。未来随着需求增长,你可以轻松地:
- 增加一个 MySQL 或 PostgreSQL 数据库容器。
- 集成 Redis 作为缓存服务。
- 引入基于队列的异步工作容器。
所有这些扩展都发生在 Docker 容器层,而虚拟机依然作为最外层坚固的安全外壳——这正是分层架构设计的优势所在。
五、从架构图到落地实施指南
1)按层次搭建你的沙盒环境
- 安装 Lima(或类似工具),创建 Linux 虚拟机(对应架构图中最大的虚线框)。
- 在虚拟机内部安装并运行 Docker 服务(对应容器层)。
- 配置 Docker 容器的 Volume 映射,将宿主机特定目录(如
Uploads)挂载到容器内(对应绿色箭头)。
- 通过浏览器完整测试文件上传与结果预览的整个链路(对应用户层)。
2)为智能体封装安全的“武器库”API
建议将前述的八大操作命令封装为一组具有严格约束的 API 接口:
- 输入校验:对路径、参数、长度、类型进行严格检查。
- 权限策略:强制执行命令白名单、工作目录限制和超时限制。
- 审计日志:详细记录“谁、在何时、执行了什么操作”。
- 默认拒绝:遵循最小权限原则,没有明确允许的操作一律禁止。
3)建立监控与调优机制
不要等到出现问题才补救,应提前建立监控体系:
- 资源监控:关注虚拟机及容器的 CPU、内存、磁盘使用量和容器数量。
- 日志分析:集中收集和分析上传日志、命令执行日志、文件变更日志。
- 性能调优:对常用基础镜像进行预热,合理设置缓存策略,限制单次命令输出的最大长度以避免内存溢出。
六、总结
智能体时代的软件开发,越来越像“与一位高度自动化的实习生协同工作”:你期望它高效、多产、能自动处理任务;但你也必须为其设定明确的边界、提供专用的工具、并建立清晰的责任链路。
本文所探讨架构背后的设计哲学其实非常朴素:
- 信任,但必须验证。
- 赋予智能体自由,但务必划定不可逾越的边界。
- 确保一切风险可控,所有产出皆可复现。
如果你正准备构建自己的 AI 智能体应用,那么从现在开始,将这套沙盒架构作为你的核心工程蓝图,无疑是一个稳健的起点。关于更多AI与云原生技术的实践讨论,欢迎在云栈社区与大家交流。
|  发表于 2025-12-31 07:12:19
|
查看: 236|
回复: 0
发表于 2025-12-31 07:12:19
|
查看: 236|
回复: 0
