随着数据中心电力和硬件成本的攀升,企业越来越需要从现有投资中挖掘更高效率。尤其是在 Kubernetes 上运行资源密集型 AI 项目的组织,对资源调度的精细度提出了更高要求。
在过去一年中,来自云原生计算基金会(CNCF)的一个跨基础工作组,一直致力于增强 Kubernetes 调度器。这项新功能——动态资源分配(Dynamic Resource Allocation, DRA)——允许用户更精准地将作业调度到节点内特定的 CPU、网卡、GPU 及各类 AI 加速器上,从而带来显著的效率与性能提升。随着 Kubernetes 1.34 和 Kubernetes 1.35 的发布,DRA 的核心组件已准备就绪,可投入生产环境。
Fluidstack 的技术专家 Byonggon Chun 在 KubeCon + CloudNativeCon 2024 North America 上兴奋地表示:“用户自定义的资源放置,是我在过去六七年里见过的社区最大改进之一。”
什么是 DRA?
在另一场题为“DRA 正式发布!”的 KubeCon 演讲中,英特尔高级软件工程师 Patrick Ohly 指出,可以将 DRA 视为一组全新的、可扩展的 Kubernetes API,它是传统设备插件的功能更丰富的替代品。
传统的设备插件只能告知节点上可用设备的数量。而通过 DRA,每个设备都会用一组属性(称为 ResourceSlice)来描述,这些属性可能包括可用内存量或计算核心数量。
这些信息会被提供给 Kubernetes 内置的作业调度器 kube-scheduler。当然,Kubernetes 生态中也有许多高性能的第三方调度器,如果你正在使用它们,需要确认其是否已支持 DRA。
当用户提交作业时,可以附带一个 ResourceClaim,明确指定作业所需的特定资源,例如特定类型的 GPU。调度器会将此请求与可用设备池进行匹配,并执行作业。“你可以根据工作负载的需求,进行任意的混合搭配,” Ohly 解释道。用户甚至可以指定配置设置,以指示底层硬件应如何配置。

图1:DRA 在 Kubernetes 中的四个组成部分,通过 ResourceSlice 和 ResourceClaim 等 API 实现精细调度。
DRA 是调度 GPU 和 CPU 集群工作的理想选择。“当你提交 GPU 请求时,调度器知道如何找到拥有 GPU 的节点,而不是只有 CPU 的节点,”英伟达杰出工程师 Kevin Klues 在同一场演讲中补充道。
目前,许多公司已经发布了与 DRA 兼容的驱动程序,包括英特尔、英伟达、谷歌、AMD 和 Furiosa。此外,谷歌与 Red Hat 合作开发的 DRANET——一款专为高性能工作负载设计的 Kubernetes 网络驱动程序,也已被捐赠给 CNCF。
DRA 的深层优化:解决硬件对齐问题
然而,DRA 的最终目标远不止是为作业匹配合适的节点,更在于优化资源调度,使用户能从硬件中获得最优性能。
DRA 有助于解决“硬件未对齐”问题,谷歌软件工程师 Gaurav Ghildiyal(曾参与 DRANET 开发)在另一场 KubeCon 演讲“通过 DRA 中的硬件对齐实现峰值性能”中解释道。如果你在 CPU 和 GPU 集群上运行 AI/ML 作业,可能已经注意到性能存在巨大差异。在他们的基准测试中,最坏情况下工作负载的效率可能仅为完全对齐时的 40%。
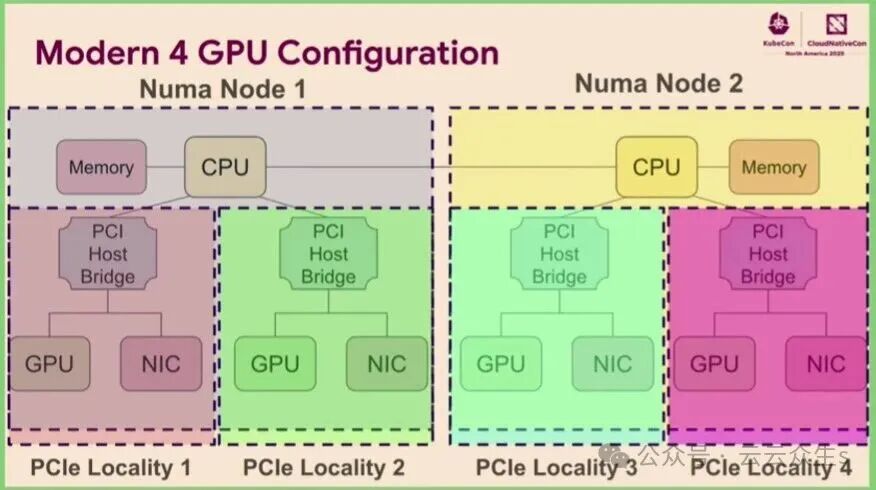
图2:现代服务器中,多GPU可能分布在不同的NUMA节点和PCIe域上,导致数据传输延迟。
现代服务器可能拥有多个 CPU,并挂载多个 GPU。这些 GPU 可能位于不同的 PCI 数据总线上,或属于独立的内存区域。即使在同一节点内,两个 GPU 之间的数据传输性能也可能因数据是否需要跨越不同的 CPU 或内存区域而产生显著波动。
当 CPU 流量必须跨越内存边界才能到达 GPU 时,数据传输时间会增加。同样,当 GPU 与网卡位于不同的内存或 PCI 域时,它们之间的数据传输也会耗时更长。传统上,K8s调度器无法理解“应将 CPU 分配给同一总线上的 GPU”这类硬件拓扑逻辑。
DRA 为用户提供了指定此类约束的基础。例如,用户可以要求 GPU 和网卡必须位于同一 PCI 总线上。DRA 将设备的“局部性”信息暴露给调度器,使其能够进行局部性感知调度。用户提交的 ResourceClaim 可以包含对特定资源属性的需求,调度器则搜索 ResourceSlice 索引来寻找满足条件的可用资源。
“关键在于,我们现在有了一种方法,可以向通用调度器‘宣传’设备的局部性质量,这在很长一段时间内都是不可能的,” Chun 在硬件对齐演讲中总结道。
资源对齐的典型用例
Ghildiyal 指出,许多工作负载都能从资源对齐中获益。
用例一:LLM 推理与训练。这是一个分布式工作负载,多个 GPU 需要彼此频繁通信(通常通过 RDMA)。理想情况下,网卡应与 GPU 位于同一 PCI 总线上。若 GPU 与网卡分离,工作负载数据不仅传输路径更长,还会在 CPU 之间的互联总线上造成“大量拥塞”。

图3:基准测试显示,GPU与网卡对齐(最佳情况)与未对齐(最差情况)下的相对NCCL峰值带宽差异显著。
基于 DRA 的解决方案可以在 ResourceClaim 上附加一个资源约束(例如 resource.kubernetes.io/pcieRoot),指示调度器仅选择那些网卡和 GPU 位于同一 PCI 总线根下的节点。
用例二:将 LLM 数据加载到 GPU。此时,CPU 与 GPU 的对齐可以节省大量时间。
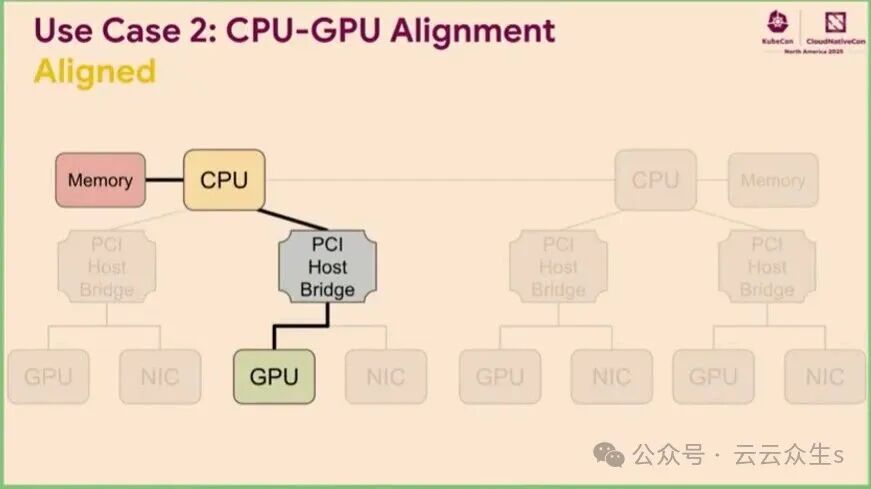
图4:CPU内存与GPU显存对齐,可以减少数据传输延迟,提升数据加载效率。
同样,CPU 与网卡之间的对齐对于数据库等网络密集型应用也至关重要。在演示者进行的基准测试中,一组未对齐的资源其吞吐量仅为完全对齐资源的 71%(Ghildiyal 指出,更高的网络带宽会进一步放大这种收益)。
Patrick Ohly 表示,尽管 DRA 的核心组件现已可用,但工作组计划开发更多功能以实现更强大的资源控制,例如扩展硬件拓扑描述能力。因此,未来几年对于 Kubernetes 调度器生态而言,仍将是充满创新与挑战的时期。
译自: Kubernetes: Get the Most from Dynamic Resource Allocation
 发表于 2025-12-31 07:33:02
|
查看: 404|
回复: 0
发表于 2025-12-31 07:33:02
|
查看: 404|
回复: 0
