Kubernetes 出问题时,最怕的不是故障本身,而是不知道从哪里下手。真正高效的运维团队,依赖的并非临场经验,而是一套固定、可复用的标准化排查路径。
本文将为你梳理一份详尽的 Kubernetes 故障排查 Checklist ,遵循 从现象 → Pod资源 → 节点 → 网络 → 控制面 的步骤,帮你一步步缩小问题范围,做到心中有数。
01 第一眼:明确现象,界定范围
动手前,先快速回答三个问题以界定故障范围:
- 是 服务完全不可用 ,还是 部分功能或实例异常 ?
- 是 新发布/变更后立刻出现 ,还是 运行中突然发生 ?
- 是 单个 Pod 或节点的问题 ,还是 全局性、集群级别的问题 ?
这对应着几种典型的故障现象:
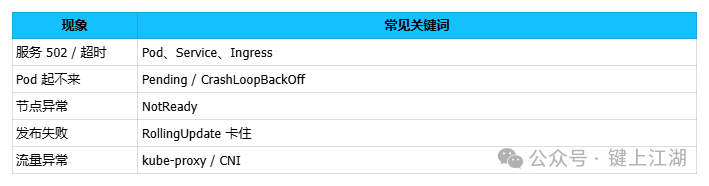
图1:K8s常见故障现象与排查关键词对应表
👉 核心思路:先定位问题发生的层级与范围,再深入具体细节。
02 Pod 维度排查(80%的问题在此)
Pod是应用运行的载体,大部分问题首先在这里显现。
✅ 检查 Pod 状态
kubectl get pod -A
重点关注异常状态:
PendingCrashLoopBackOffImagePullBackOffEvicted
✅ 查看 Pod 详情
kubectl describe pod <pod-name> -n <namespace>
通过 describe 命令的输出,可以快速定位三类问题:
- 调度失败:NodeAffinity / Taint / 资源不足
- 启动失败:镜像拉取错误、启动命令(Command)或环境变量(Env)问题
- 运行失败:就绪/存活探针(Probe)失败、端口冲突、依赖服务不可用
✅ 查看 Pod 日志
kubectl logs <pod-name> -n <namespace>
kubectl logs <pod-name> -n <namespace> --previous # 查看前一个容器的日志(用于重启后的Pod)
日志分析要点:
- 容器是否在反复重启?
- 是否卡在某个初始化阶段?
- 是否在尝试连接外部依赖(如数据库、消息队列、API)时失败?
03 调度与资源排查(针对 Pending 状态)
当Pod处于Pending状态时,通常意味着调度器无法为其找到合适的节点。
✅ 分析调度失败原因
kubectl describe pod <pod-name> -n <namespace>
在 Events 部分寻找常见提示:
Insufficient cpu / memory (节点资源不足)node(s) had taint (节点存在污点)didn‘t match PodAffinity (Pod亲和性规则不满足)
✅ 检查节点与Pod资源使用情况
kubectl top node
kubectl top pod -A
关注点:
- 集群节点CPU/内存是否已接近上限?
- 特定Pod的
requests 和 limits 配置是否不合理,导致无法调度或运行?
✅ 检查资源回收与驱逐
- 是否有大量Pod状态为
Evicted (被驱逐)?
- 是否触发了节点压力(Node Pressure),如
MemoryPressure、DiskPressure?
04 节点状态排查(针对 Node NotReady)
当 kubectl get node 显示节点状态为 NotReady 时,需要立即关注。
✅ 检查节点状态与详情
kubectl get node
kubectl describe node <node-name>
重点关注 Conditions 字段,查看 NodeReady、MemoryPressure、DiskPressure、PIDPressure 等状况。
✅ 常见 Node NotReady 原因速查

图2:K8s节点NotReady常见原因与排查方向
05 网络与 Service 连通性排查
服务访问不通,是另一个常见故障场景。
✅ 检查 Service 的 Endpoint
kubectl get ep <service-name> -n <namespace>
关键点:如果 Endpoint 列表为空,问题通常不在 Service 本身,而是背后的 Pod 未达到 Ready 状态(就绪探针失败或Pod本身异常)。
✅ 检查 Pod 到 Pod 的网络连通性
kubectl exec -it <source-pod-name> -n <namespace> -- curl <destination-pod-ip>:<port>
如果失败,优先检查:
- CNI 网络插件状态(如 Calico / Cilium 的 Pod 是否正常)
- 节点间网络:路由、VXLAN/IPIP隧道等是否正常
✅ 理清 Service 流量路径
ClusterIP:依赖 kube-proxy 维护的 iptables/IPVS 规则。NodePort:检查节点防火墙是否放行了对应端口。LoadBalancer:检查云服务商提供的负载均衡器状态与配置。
06 发布与滚动升级问题排查
滚动更新(RollingUpdate)卡住,会导致服务处于中间状态。
✅ 检查 Deployment 状态
kubectl rollout status deployment/<deployment-name> -n <namespace>
常见卡住原因:
readinessProbe 一直失败,新Pod无法进入Ready状态。- 新Pod因镜像、配置等问题无法启动(回到第02步排查)。
maxUnavailable 或 maxSurge 策略配置不合理,导致更新无法继续。
✅ 执行回滚(先恢复服务)
kubectl rollout undo deployment/<deployment-name> -n <namespace>
黄金法则:线上故障,先执行回滚“止血”,保障服务可用性,然后再分析根本原因。
07 控制面组件排查(应对全局异常)
当你遇到以下情况时,需要怀疑控制面(Control Plane)健康状态:
- 所有 Pod 调度都失败(
Pending)。
- 创建、更新任何资源都卡住或无响应。
kubectl 命令执行异常缓慢或超时。
需要检查的核心组件:
kube-apiserver:集群入口,检查其负载、日志和可用性。kube-scheduler:检查调度决策与日志。kube-controller-manager:检查各类控制器的状态。etcd:集群的大脑,检查其健康状态、存储空间和延迟。
(注:生产集群的控制面通常由平台或SRE团队维护,需协作排查。这部分也体现了稳定高效的运维体系的重要性。)
08 系统级兜底检查
如果以上所有层面都未发现明显问题,可以考虑以下“边角”因素:
- 节点时间同步:所有节点时间是否一致(NTP服务)?
- DNS解析:集群内DNS(如CoreDNS)是否工作正常?
- 网络策略:是否配置了过于严格的
NetworkPolicy 误杀了流量?
- 近期变更:最近是否有过任何配置变更、升级或发布?
09 一张总结表(值班速查)
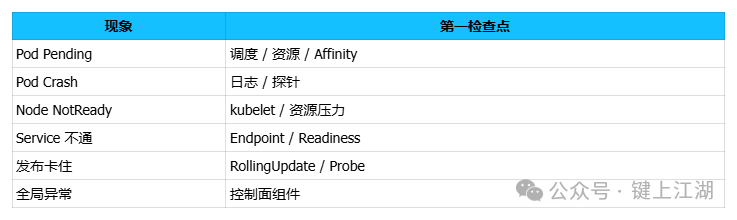
图3:根据现象快速定位第一检查点的故障排查速查表
结语:排障依赖系统性路径,而非随机猜测
高效的 Kubernetes 故障排查,其核心在于:
- ❌ 不是漫无目的地翻看海量日志。
- ❌ 不是依靠零散的经验盲目尝试。
- ✅ 而是 遵循一个清晰的 Checklist,自顶向下,逐层递进,系统地缩小问题范围。
始终坚持 先定位问题层级(现象),再定位具体组件(Pod/Node/网络等),最后定位配置或代码细节 的路径。这套方法不仅能用于Kubernetes,也是云原生基础设施运维的通用思路。掌握系统化的排障方法,是保障服务稳定性的关键技能。如果你希望深入探讨容器化环境下的稳定性实践,可以参考更多运维与云原生领域的专业内容。
 发表于 2025-12-31 07:36:09
|
查看: 217|
回复: 0
发表于 2025-12-31 07:36:09
|
查看: 217|
回复: 0
