做后端和监控开发的同学,大概都有过这种焦虑时刻:当日志数据量大到一定规模后,原本顺畅的查询就开始“罢工”。监控服务疯狂报警,或者老板急着要数据,结果你调用的日志接口一直卡住,最后直接报请求超时。
最近,我们配合一位深度用户(某大型业务团队),在他们的核心日志场景里落地了 SLS 物化视图。我们在生产环境中对比了开启该功能前后的表现,无论是硬指标的性能数据,还是实际的使用体验,差距都非常大。
本文将结合真实的业务场景与结果数据,复盘一下我们是如何把几个总是超时的慢查询,优化到“秒级”响应的。
案例一:SDK 高并发“轰炸”,终于不再超时了
这是一个非常典型的自动化监控场景。用户的监控服务通过 SDK 高频调用日志接口,拉取服务间的调用延时数据。
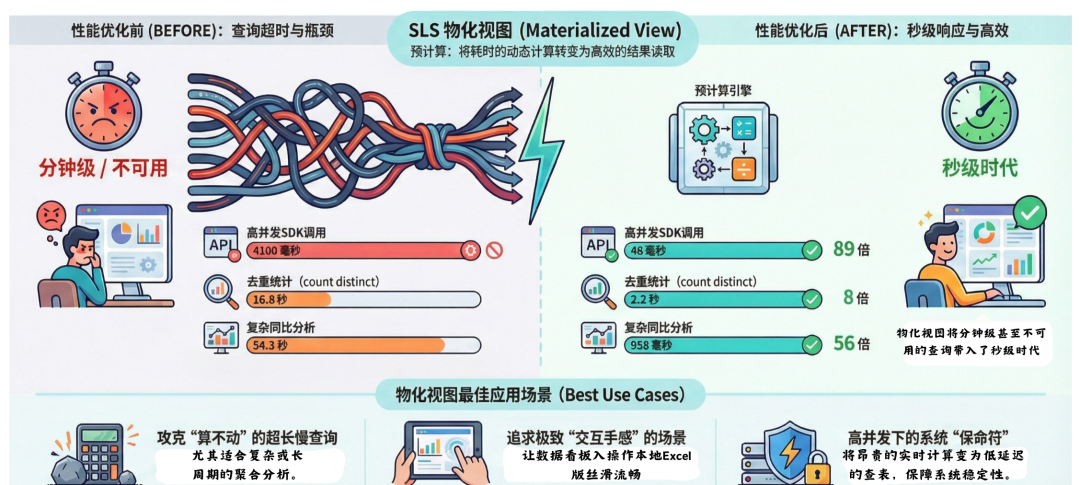
痛点:这个场景的难点在于“高并发 + 动态条件”。监控程序会在短时间内发出大量请求,每个请求的查询条件都在变,比如这一秒查 columnx:"abc",下一秒查 columnx:"abd"。这种用法对后端压力较大。优化前,平均一次查询要 4100 毫秒。这就导致一个恶性循环:查询慢 -> 线程池积压 -> 并发进一步争抢资源 -> 最终大面积超时。
去掉业务语义后的 SQL:
query| select
column1, column2, column3,
(timestamp - timestamp % 3600) as time_slot,
count(*) as cnt,
avg(metric_val) as avg_lat
from log
group by column1,column2,column3,time_slot
使用物化视图后:查询耗时直接降到了 46 毫秒,性能提升了 89 倍。更重要的是,现在无论 SDK 的并发有多高,或者查询条件怎么变,由于只需要读取预计算好的结果,响应时间都非常稳定,彻底解决了 高并发 下的超时问题。
案例二:搞定“去重统计”这个性能杀手
做过数据的都知道,count(distinct) 是资源消耗大户,尤其是在数据量很大的场景下。
用户 SQL:
query | select
project_id,
count(1) as event_cnt,
count(distinct hash_val) as issue_cnt
from log
group by project_id
为了统计去重后的错误特征(Hash),在数据量较大时,这个 SQL 跑起来较吃力。
- 优化前:这个查询之前平均耗时 16.8 秒。稍微把时间范围拉长一点(比如看过去一个月的趋势),或者高峰流量大一点,就很容易查不出来。
- 优化后:通过物化视图加速,查询时间降到了 2.2 秒,8 倍的性能提升,已经让这个功能从“经常不可用”变成了“可以随时查”。
案例三:同比分析,从“54 秒超时”到“秒级响应”
这是这次优化中性能提升最大的一个场景。用户有一个查看操作日志读延迟同比变化的需求(对比 1 天前、3 天前、7 天前的数据)。
用户 SQL:
type:read|
select
time,
diff [1] as day1,
diff [2] as day2,
diff [3] as day3,
diff [4] as day7
from (
select
time,
ts_compare(avg_latency, 86400, 172800,604800) as diff
from (
select
avg(latency) as avg_latency,
date_trunc('hour', __time__) as time
from log
group time )
group by time order by time )
这个 SQL 涉及 ts_compare 和多层子查询嵌套,当查询时间范围较大时,计算量非常大。
- 优化前:耗时 54.3 秒,后端服务稍微抖动一下,用户的请求就超时了,基本上就是一个不可用的状态。
- 优化后:耗时 958 毫秒,从接近一分钟的漫长等待,直接变成了不到 1 秒。性能提升了 56 倍。这种从“查不出来”到“秒开”的体验变化,对于等着看数据的运维同学来说,是最直观的。
算一笔账
这次优化的 ROI(投入产出比)非常划算:
- 利用率高:一天下来,这几个视图累积命中了 10,223 次 查询。
- 成本极低:大家可能担心存一份结果会不会很贵,实际看下来,新增的存储成本还不到原始日志存储费用的千分之一,几乎可以忽略不计。
总结
结合这次实战经验,我们也总结了 SLS 物化视图最适合的三个场景。如果你的业务也中了下面这些情况,直接开启物化视图吧:
-
专治“必死”的超长慢查询:如果你的 SQL 里包含大量的去重统计(count distinct)、高精度的百分位计算(approx_percentile),或者像案例三那样涉及长周期时间范围的数据分析。这些操作在原始数据量较大时,怎么优化都很难跑进几秒内,甚至直接超时。物化视图能把这些“算不出来”的硬骨头提前啃完,把“超时”变成“秒出”。
-
对“交互手感”要求极高的场景:并不是说不超时就够了。对于直接面向用户的数据产品,或者老板天天看的核心大盘,10 秒 和 1 秒 是完全不同的体验。如果你的目标是让大盘操作起来像本地 Excel 一样丝滑,预计算是绕不开的路。
-
高并发轰炸下的“保命符”:这是最容易被忽视的一点。很多时候单次查询虽然能忍,但一旦故障发生,几十号人同时刷新大盘,再加上自动化巡检脚本(SDK)几百个并发打过来,很容易触发服务端的资源瓶颈。物化视图的本质是把昂贵的“现场计算”变成了低延迟的“查表读取”。在关键时刻,这就是系统不崩盘的基石。
千言万语不如一张图。我们将本次实战的核心性能指标与最佳适用场景浓缩成了下面这张全景图,希望能为您的 日志分析 与性能优化提供参考。
希望以上实战经验能为你的系统优化提供思路。更多关于系统架构与性能调优的深度讨论,欢迎访问 云栈社区 与广大开发者交流分享。
 发表于 2026-1-3 10:30:06
|
查看: 276|
回复: 0
发表于 2026-1-3 10:30:06
|
查看: 276|
回复: 0
