在分布式系统或复杂的单体应用中,当请求量激增或调用链路变长时,一个常见的问题是:如何在海量日志中快速定位属于同一次请求的所有记录?如果每条日志都是孤立的,排查问题就像大海捞针。
虽然 Spring Cloud 生态中有 Zipkin、OpenTelemetry 等成熟的分布式追踪解决方案,但对于纯 Spring Boot 项目,或者希望以更轻量、更简单的方式实现请求跟踪的场景,利用 Spring 自带的 MDC(Mapped Diagnostic Context)来生成和传递 TraceId 是一个高效且实用的选择。
通过为每个请求分配唯一的 TraceId 并将其贯穿于整个处理链路,你只需通过某一条关键日志找到对应的 TraceId,就能一键筛选出该请求的所有相关日志,极大提升问题排查效率。本文将详细介绍如何基于 MDC 在 Spring Boot 项目中实现 TraceId 的全链路透传,并覆盖以下核心场景的处理方案:
- HTTP 请求
- 消息队列(以 RabbitMQ 为例)
- 线程池异步任务
- 定时任务(以 XXL-Job 为例)
MDC 实现原理简述
MDC 是 SLF4J/Logback 提供的一种线程级别的诊断上下文存储机制。其内部本质是一个依附于线程的 ThreadLocal<Map<String, String>>。
- 当你在某个线程中调用
MDC.put("traceId", "xxx") 时,这个键值对就会被存储在当前线程独有的上下文中。
- 日志框架(如 Logback)在输出日志时,可以识别日志模式中的特定占位符(如
%X{traceId}),并自动从当前线程的 MDC 中取出对应的值进行填充。
- 由于基于 ThreadLocal,不同线程之间的 MDC 上下文是相互隔离的,互不干扰。
第一步:配置 Logback 日志输出
要让 TraceId 能够打印出来,首先需要在日志配置文件中进行相应配置。
1. 控制台输出(开发环境)
修改 logback-spring.xml 文件,在定义控制台日志模式的 property 标签中,加入 TraceId 的占位符 [traceId:%X{traceId}]。
<property name="CONSOLE_LOG_PATTERN"
value="${DEFAULT_CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} [traceId:%X{traceId}] %clr(${LOG_LEVEL_PATTERN:-%5p})
%clr(${PID:- }){magenta} %clr(---){faint} %clr([%t]){faint} %clr(%-40.40logger{39}){cyan}
%clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
配置后,本地控制台输出的日志格式将类似于:[traceId:7e01902b18ef4c2b9f49609c57d769fa] INFO ...

2. 文件输出(测试/生产环境)
对于输出到日志文件的 Appender(如全量日志、错误日志),如果希望以结构化格式(例如 JSON)收集日志,需要在对应的 JSON 模式(pattern)中添加 TraceId 字段。
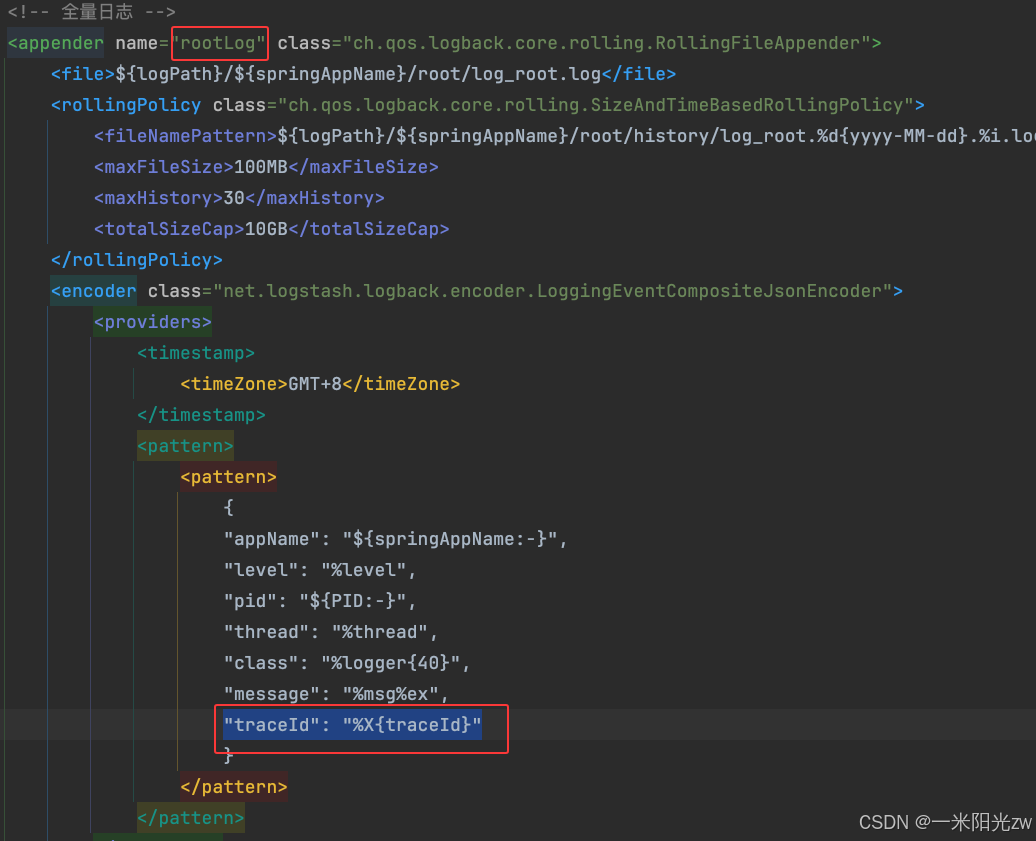
以下是一个全量日志 Appender 的配置示例,注意在 pattern 中添加了 "traceId": "%X{traceId}":
<appender name="rootLog" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${logPath}/${springAppName}/root/log_root.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${logPath}/${springAppName}/root/history/log_root.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>10GB</totalSizeCap>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>GMT+8</timeZone>
</timestamp>
<pattern>
<pattern>
{
"appName": "${springAppName:-}",
"level": "%Level",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"message": "%msg%ex",
"traceId": "%X{traceId}"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
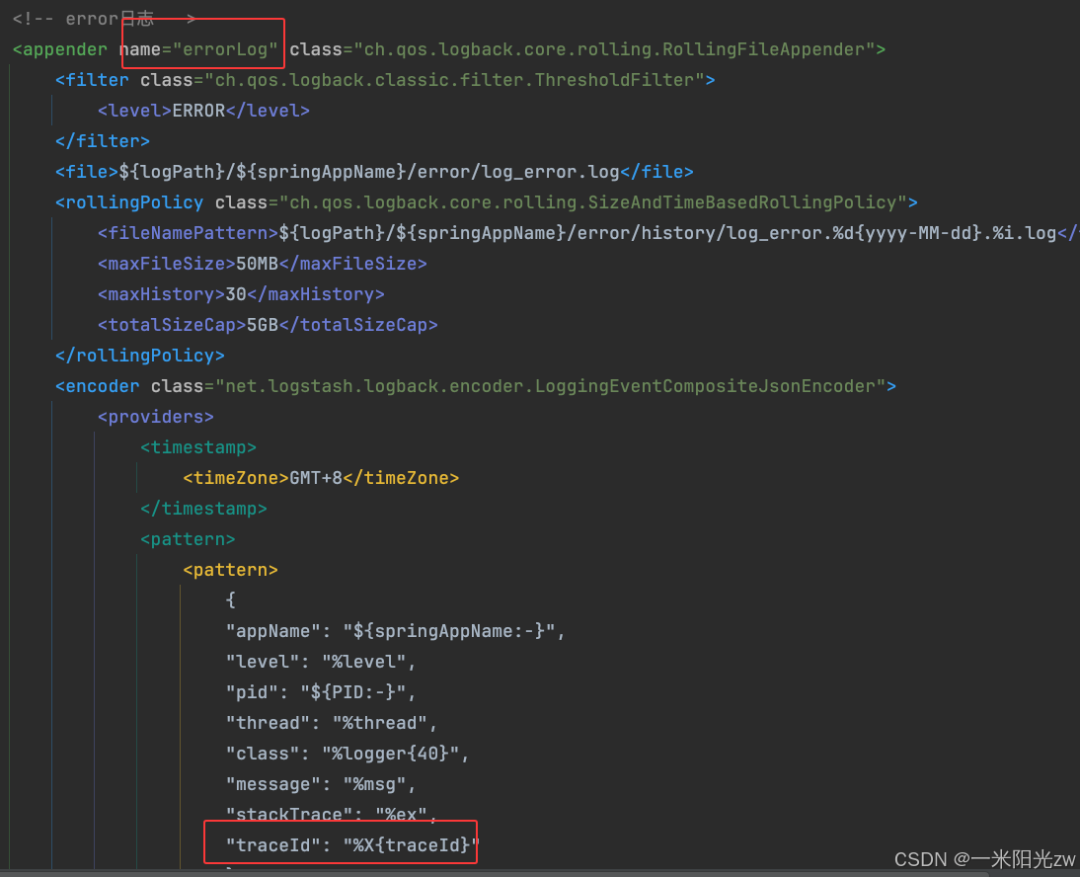
同样地,错误日志的 Appender 也需要进行类似配置,确保在排查错误时也能关联到 TraceId。
第二步:处理 HTTP 请求
对于 HTTP 请求,最直接的方式是使用一个过滤器(Filter),在请求进入时生成并设置 TraceId,在请求结束后清理。
import org.slf4j.MDC;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.UUID;
/**
* 日志traceId过滤器
*/
@Component
public class TraceIdFilter extends OncePerRequestFilter {
private static final String TRACE_ID = "traceId";
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
// 跳过预检请求(OPTIONS)
if ("OPTIONS".equalsIgnoreCase(request.getMethod())) {
filterChain.doFilter(request, response);
return;
}
try {
String traceId = UUID.randomUUID().toString().replace("-", "");
MDC.put(TRACE_ID, traceId);
filterChain.doFilter(request, response);
} finally {
MDC.remove(TRACE_ID);
}
}
}
第三步:处理线程池异步任务
当业务逻辑使用线程池执行异步任务时,由于任务会在不同的线程中执行,而 MDC 是基于 ThreadLocal 的,所以主线程的 TraceId 不会自动传递到子线程。我们需要手动包装任务,实现上下文传递。
核心思路是:在提交任务时,复制当前线程的 MDC 上下文;在任务执行开始时,将其设置到子线程中;任务执行完毕后,恢复子线程原有的上下文(避免影响线程池中该线程的下一次任务)。
// 假设这是一个自定义的线程池执行器封装类
public void execute(Runnable task) {
defaultThreadPoolExecutor.execute(wrap(task, MDC.getCopyOfContextMap()));
}
public <T> Future<T> submit(Callable<T> task) {
return defaultThreadPoolExecutor.submit(wrap(task, MDC.getCopyOfContextMap()));
}
/**
* 封装 Runnable,复制 MDC 上下文
*/
private Runnable wrap(Runnable task, Map<String, String> contextMap) {
return () -> {
Map<String, String> previous = MDC.getCopyOfContextMap();
if (contextMap != null) {
MDC.setContextMap(contextMap);
} else {
MDC.clear();
}
try {
task.run();
} finally {
// 恢复线程池线程原来的 MDC,避免影响下一次任务
if (previous != null) {
MDC.setContextMap(previous);
} else {
MDC.clear();
}
}
};
}
/**
* 封装 Callable,复制 MDC 上下文
*/
private <T> Callable<T> wrap(Callable<T> task, Map<String, String> contextMap) {
return () -> {
Map<String, String> previous = MDC.getCopyOfContextMap();
if (contextMap != null) {
MDC.setContextMap(contextMap);
} else {
MDC.clear();
}
try {
return task.call();
} finally {
// 恢复线程池线程原来的 MDC,避免影响下一次任务
if (previous != null) {
MDC.setContextMap(previous);
} else {
MDC.clear();
}
}
};
}
第四步:处理消息队列(RabbitMQ)
对于 RabbitMQ 这类消息中间件,透传 TraceId 需要生产者和消费者配合。
1. 生产者发送消息时携带 TraceId
在发送消息时,将当前线程的 TraceId(如果不存在则生成一个)放入消息的 Header 中。
public <T> void sendMq(MqEnum.TypeEnum typeEnum, MqMessage<T> message) {
rabbitTemplate.convertAndSend(MqEnum.Exchange.EXCHANGE_NAME, typeEnum.getRoutingKey(), message,
msg -> {
String traceId = MDC.get(TRACE_ID);
if (traceId == null) {
traceId = UUID.randomUUID().toString().replace("-", "");
MDC.put(TRACE_ID, traceId);
}
msg.getMessageProperties().getHeaders().put(TRACE_ID, traceId);
return msg;
});
}
2. 消费者统一接收 TraceId
利用 Spring AMQP 的 Advice 机制,可以创建一个全局的拦截器,在所有 @RabbitListener 方法执行前,从消息 Header 中取出 TraceId 并设置到当前消费线程的 MDC 中。
@Bean
public Advice traceIdAdvice() {
return (MethodInterceptor) invocation -> {
Object[] args = invocation.getArguments();
String traceId = null;
for (Object arg : args) {
if (arg instanceof Message message) {
traceId = (String) message.getMessageProperties().getHeaders().get(TRACE_ID);
break;
}
}
if (traceId != null) {
MDC.put(TRACE_ID, traceId);
}
try {
return invocation.proceed();
} finally {
MDC.remove(TRACE_ID);
}
};
}
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(
ConnectionFactory connectionFactory,
Advice traceIdAdvice) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setAdviceChain(traceIdAdvice);
return factory;
}
第五步:处理定时任务(XXL-Job)
对于 XXL-Job 定时任务,我们可以利用 AOP 切面,为所有标注了 @XxlJob 的方法自动添加 TraceId,无需在每个任务方法中手动编写。
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.slf4j.MDC;
import org.springframework.stereotype.Component;
import java.util.UUID;
@Aspect
@Component
public class XxlJobTraceAspect {
private static final String TRACE_ID = "traceId";
@Pointcut("@annotation(com.xxl.job.core.handler.annotation.XxlJob)")
public void xxlJobMethods() {}
@Around("xxlJobMethods()")
public Object aroundXxlJob(ProceedingJoinPoint joinPoint) throws Throwable {
String traceId = UUID.randomUUID().toString().replace("-", "");
MDC.put(TRACE_ID, traceId);
try {
return joinPoint.proceed();
} finally {
MDC.remove(TRACE_ID);
}
}
}
实践效果验证
编写测试接口,验证上述场景下 TraceId 的透传是否一致。
1. 测试异步任务
@GetMapping(value = "/test/traceId/async")
public Result<NullResult> traceId() {
log.info("主 traceId");
asyncExecutors.execute(() -> log.info("execute traceId"));
asyncExecutors.submit(() -> {
log.info("submit traceId");
return "ok";
});
List<Runnable> list = new ArrayList<>();
list.add(() -> log.info("execute list traceId"));
asyncExecutors.execute(list);
return Result.buildSuccess();
}
调用该接口,观察日志,可以看到主线程与各个异步任务线程打印的 TraceId 完全相同。
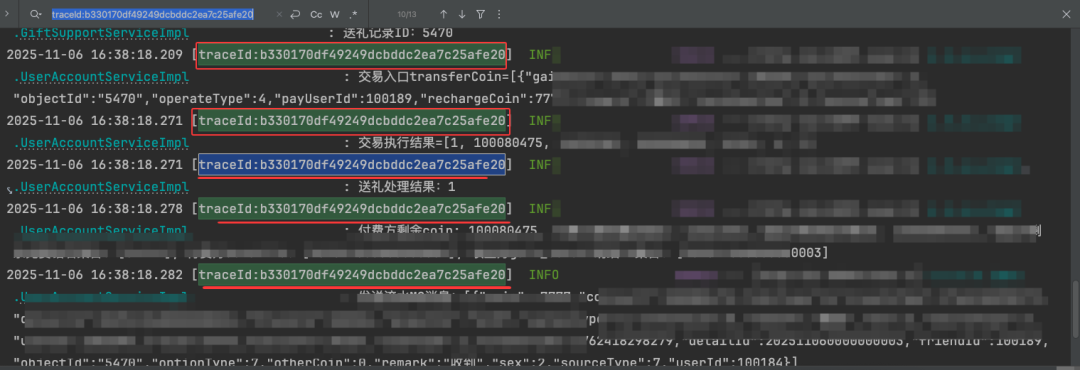
2. 测试消息队列
@GetMapping(value = "/test/traceId/mq")
public Result<NullResult> mq() {
log.info("主mq traceId");
MqMessage<String> message = new MqMessage<>();
message.setData(JSON.toJSONString(Collections.emptyList()));
mqSender.sendMq(MqEnum.TypeEnum.PROP_SEND, message);
return Result.buildSuccess();
}
调用接口后,查看消息发送端和消费者端的日志,它们的 TraceId 也应保持一致。
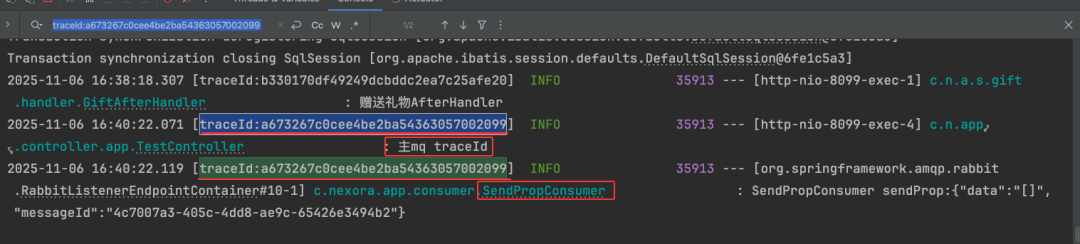
下图进一步展示了线程池中多种任务提交方式下,TraceId 的一致性。
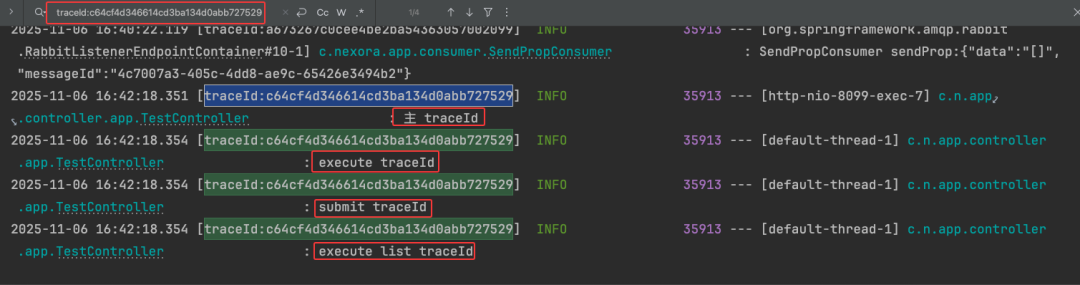
3. 测试定时任务
对于 XXL-Job 任务,执行后可以在日志平台中,通过切面自动生成的 TraceId 来关联查看该次任务执行的所有日志。
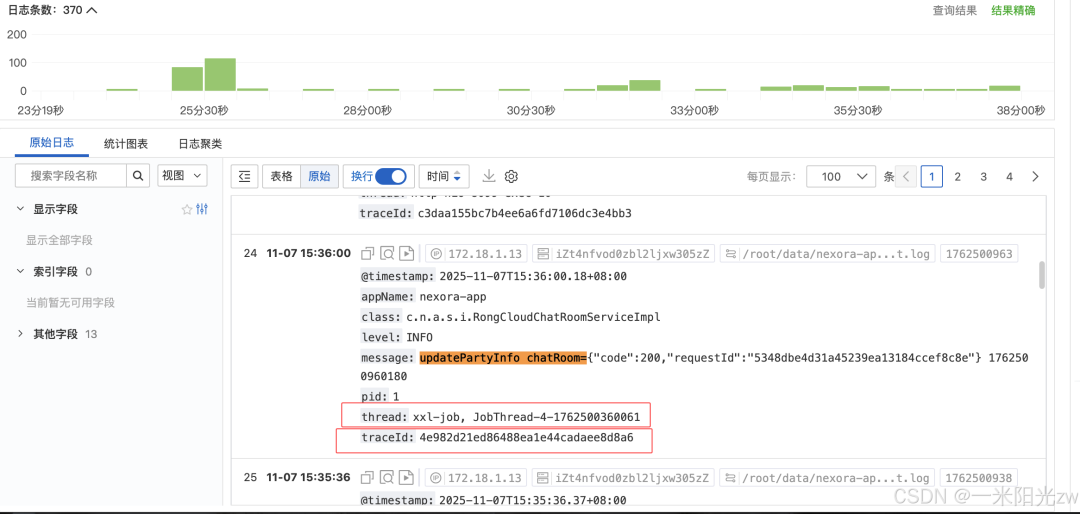
总结
通过上述步骤,我们无需引入复杂的分布式追踪组件,仅利用 Spring Boot 原生支持的 MDC 和 SLF4J/Logback,就实现了 TraceId 在 HTTP、异步任务、消息队列和定时任务等多种常见场景下的全链路透传。这套方案轻量、易实现,能显著提升在复杂调用链路下的日志排查效率,是中小型项目或追求简洁架构场景下的一个绝佳选择。
希望这篇实践指南能对你有所帮助。更多关于系统架构、Java 高级特性及后端开发的深度讨论,欢迎访问 云栈社区 与广大开发者共同交流。
 发表于 2026-1-4 14:57:44
|
查看: 345|
回复: 0
发表于 2026-1-4 14:57:44
|
查看: 345|
回复: 0
