南京大学、腾讯 ARC Lab 与上海 AI Lab 的联合研究团队提出了 TimeLens 项目。该研究针对基于大模型的视频时间定位任务,从数据和算法两个维度进行了系统性的重新思考与优化。
通过构建高质量的评测基准和训练数据集,并设计出一系列简洁有效的算法改进,TimeLens 系列模型以仅 8B 的参数量,在开源模型中实现了 SOTA 性能,甚至超越了 Gemini-2.5-Flash 等前沿闭源模型。
TimeLens 的模型、评测基准与训练集均已开源。

论文链接:
https://arxiv.org/abs/2512.14698
项目主页:
https://timelens-arc-lab.github.io/
代码与模型:
https://github.com/TencentARC/TimeLens
背景问题与研究动机
随着多模态大模型技术的发展,模型在理解视频内容(即“发生了什么”)方面已表现出色。然而,当被问及事件“何时发生”时,现有模型的表现往往不尽如人意。
解决这一问题的关键在于提升模型的视频时间定位能力。在该任务中,模型需要根据文本查询,准确定位视频中对应事件发生的起止时间。尽管已有大量研究致力于此,但该领域仍面临两大核心挑战:
- 被忽视的数据质量问题:现有的主流评测基准中存在大量标注错误、查询模糊等问题,导致评估结果不可靠。同时,用于训练的数据集也存在类似噪声,这使得算法设计的真实效果难以被准确衡量。
- 未定型的算法设计:对于如何让模型有效感知时间信息、何种训练范式最为有效等关键问题,现有研究方案不一,缺乏系统性的最佳实践探索。
TimeLens 项目旨在从数据质量和算法设计两个层面,系统性地解决上述问题。
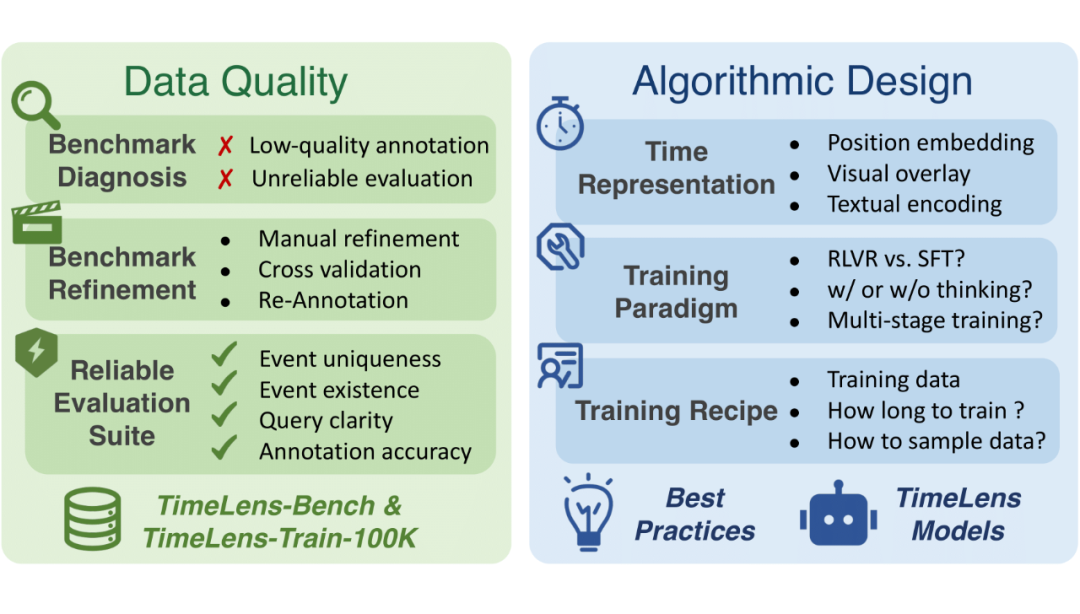
数据质量:去伪存真,重塑基准
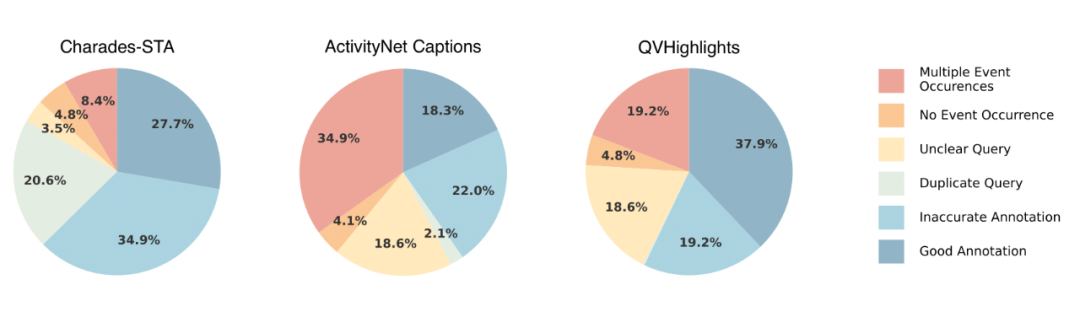
研究团队首先对主流的视频时间定位基准(Charades-STA, ActivityNet Captions, QVHighlights)进行了严格的人工检验与分析,揭示了其中普遍存在的“陷阱”。
1. 现有数据的常见错误
分析发现了多种类型的低质量问题,例如:
- 事件不存在:文本描述的事件在视频中并未发生。
- 多重事件:同一查询对应视频中多个片段,但标注不完整。
- 查询模糊:文本描述本身存在歧义,无法精确定位。
- 标注不准:标注的时间边界存在严重偏移。
统计结果显示,现有基准中错误样本的比例非常高,严重影响了评估的公正性。

2. TimeLens-Bench 与 TimeLens-100K
为纠正上述问题,团队制定了严格的标注标准,对三个数据集进行了手动重新标注,发布了高质量的 TimeLens-Bench。
评估结果表明,在修复后的新基准上,模型排名发生了显著变化:旧基准往往高估了开源模型的能力,而低估了如 Gemini 系列等前沿闭源模型的真实水平。
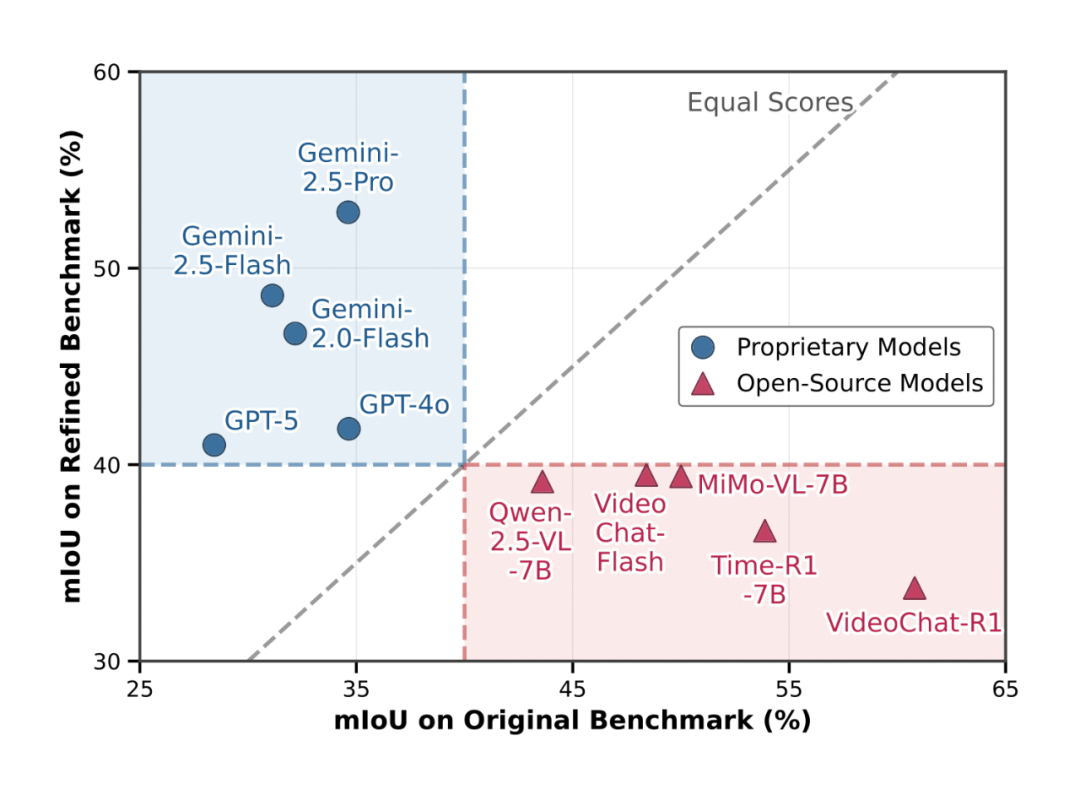
此外,团队还通过自动化流程清洗并重标注了大规模训练数据,构建了包含10万条高质量样本的 TimeLens-100K 训练集。在该数据集上训练模型,相比使用原始噪声数据带来了显著的性能提升。

算法设计:探寻最优解
在可靠的数据基础上,TimeLens 对算法设计的核心组件进行了深入探索,得出了一系列有价值的结论。
1. 时间表示:交错文本编码最优
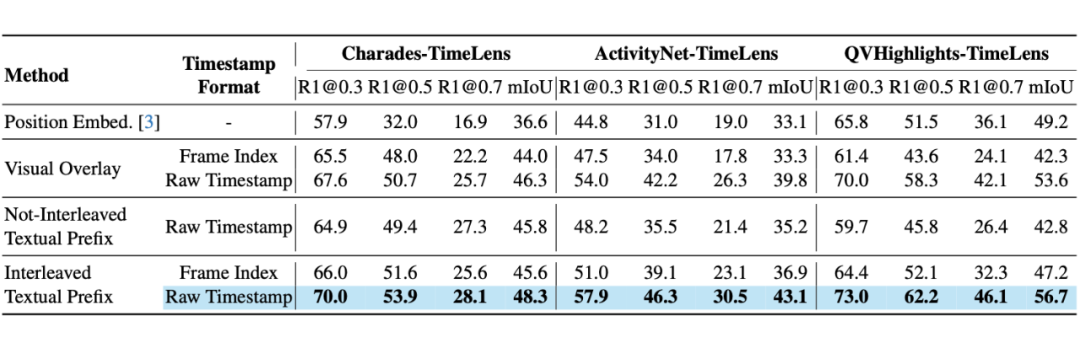
如何让大语言模型准确理解每一帧视频的时间信息?团队对比了多种主流方法,包括位置编码、视觉时间戳叠加和文本时间戳编码。
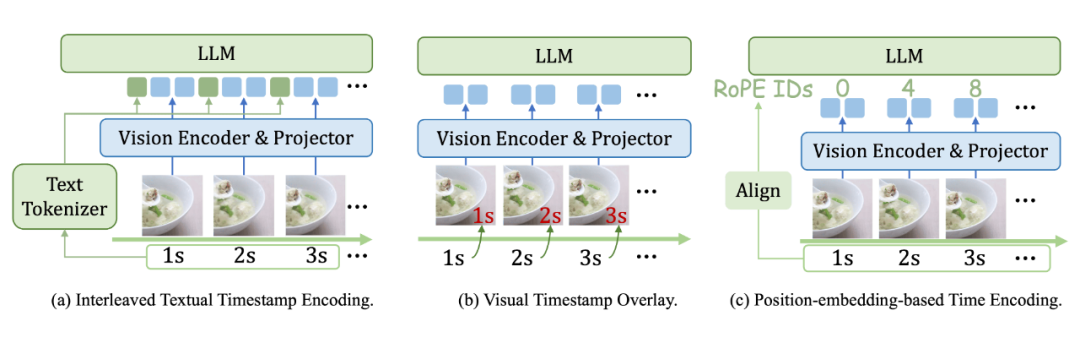
实验结论清晰表明:简单的交错文本前缀编码效果最佳。该方法在每帧视觉特征前插入文本形式的时间戳,无需修改模型架构,保持了极大的简洁性。
2. 训练范式:Thinking-free RLVR
以往工作多采用监督微调来训练视频定位模型。而近期,基于可验证奖励的强化学习范式受到关注。那么,对于 VTG 任务,何种训练范式最优?
团队系统对比了 SFT、RLVR 及其组合。特别针对 RLVR,还探究了显式“思考”过程的必要性。
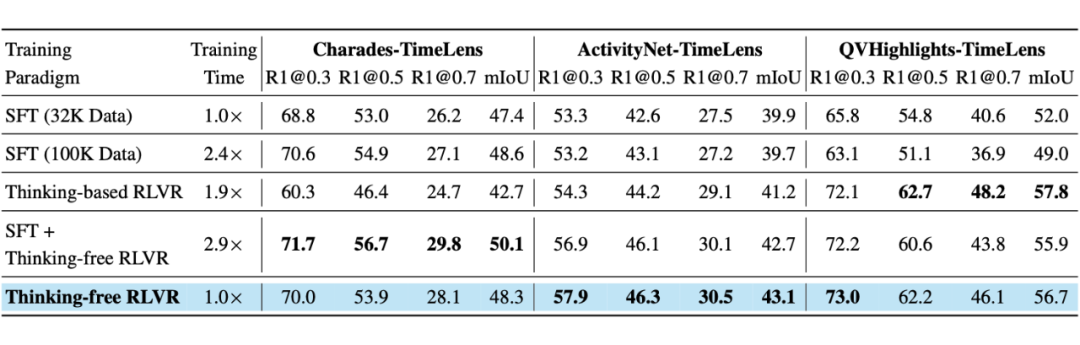
结论出人意料:仅使用无思考过程的 RLVR 进行训练,不仅能取得最佳性能,还显著提升了训练和推理效率。
3. 训练秘籍:早停策略与基于难度采样
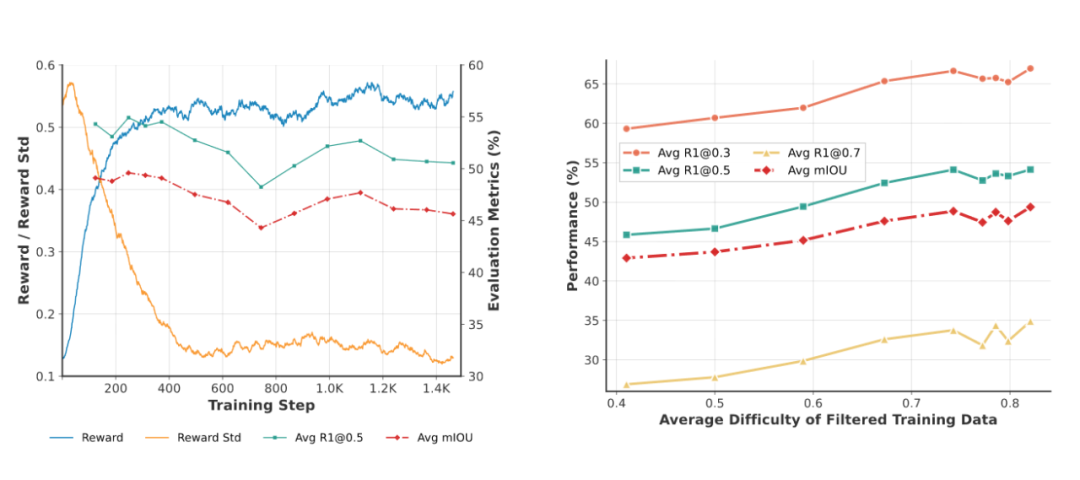
基于 Thinking-free RLVR 范式,团队进一步探究了训练过程中的关键因素,总结出两项重要“秘籍”:
- 早停策略:在 RL 训练中,当奖励指标进入平台期时应立即停止,过度训练反而会导致性能下降。
- 基于难度的数据采样:训练数据的难度需与模型当前能力匹配。通过预先估计样本难度并筛选,可以最大化训练收益。
实验结果:SOTA 性能
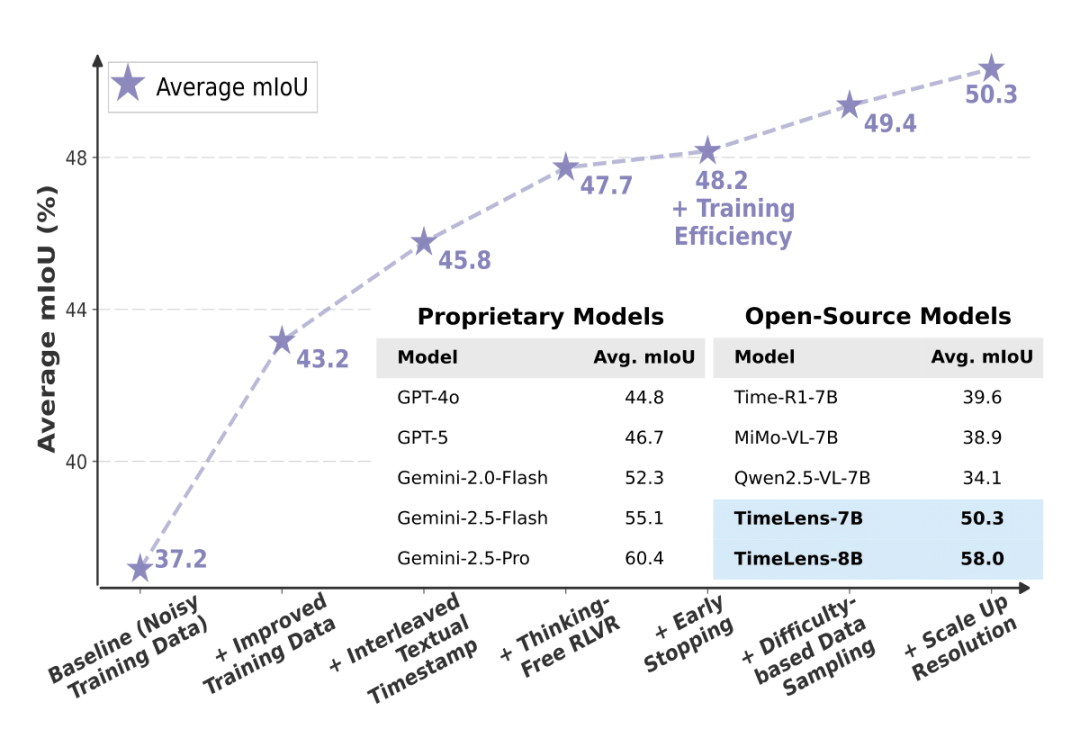
集成上述在数据与算法层面的系列最佳实践,团队最终发布了 TimeLens 系列开源模型。
评测结果显示,TimeLens 模型相对基线取得了全面且显著的提升。其中,TimeLens-8B 模型以仅 8B 的参数量,在多项指标上全面超越了 GPT-5 和 Gemini-2.5-Flash 等前沿闭源模型,确立了开源模型中的新 SOTA。
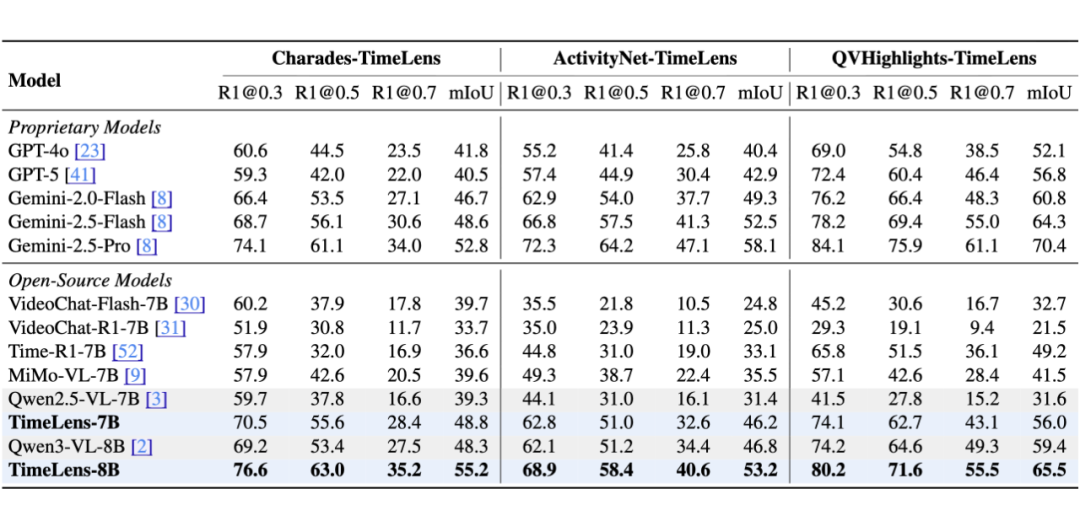
从基线开始,在数据和算法上的每一步改进,都为最终的优异表现做出了清晰可见的贡献。
结语
TimeLens 工作的价值不仅在于提供了一个强大的开源视频时间定位模型,更在于它通过揭露数据质量陷阱和系统性探索算法最佳实践,为未来的视频理解研究指明了更加可靠的方向。所有代码、数据与模型均已开源,为社区在多模态大模型和计算机视觉领域的进一步探索提供了坚实基石。对这类前沿人工智能技术感兴趣的朋友,欢迎关注云栈社区获取更多深度技术解读与开源实战资源。
 发表于 2026-1-4 14:51:04
|
查看: 287|
回复: 0
发表于 2026-1-4 14:51:04
|
查看: 287|
回复: 0
