基于可验证奖励的强化学习(RLVR)在训练工具使用大语言模型(LLMs)方面显示出潜力。然而,现有方法大多忽视了显式推理奖励在增强模型推理和工具利用方面的潜力。此外,简单地结合推理和结果奖励可能导致性能次优,甚至与主要优化目标相冲突。
为此,中国科学院自动化研究所与美团的研究团队联合提出了 优势加权策略优化(AWPO, Adaptive Weighted Proximal Policy Optimization) 。这是一个全新的强化学习框架,能够有效集成显式推理奖励,从而显著增强LLM的工具使用能力。AWPO巧妙地结合了方差感知门控和难度感知加权机制,能够基于组内的相对统计信息自适应地调整推理信号的优势,同时还配备了定制的动态剪裁机制,以确保优化过程的稳定性。
大量实验表明,AWPO在标准工具使用基准上实现了SOTA性能,尤其在具有挑战性的多轮对话场景中,表现超越了众多闭源模型。更值得一提的是其卓越的参数效率:团队训练的4B模型在多轮对话上的准确率超过了Grok-4模型16%,同时在分布外的MMLU-Pro基准上保持了强大的泛化能力。关于人工智能的更多前沿研究和讨论,欢迎访问云栈社区的相关板块。

方法
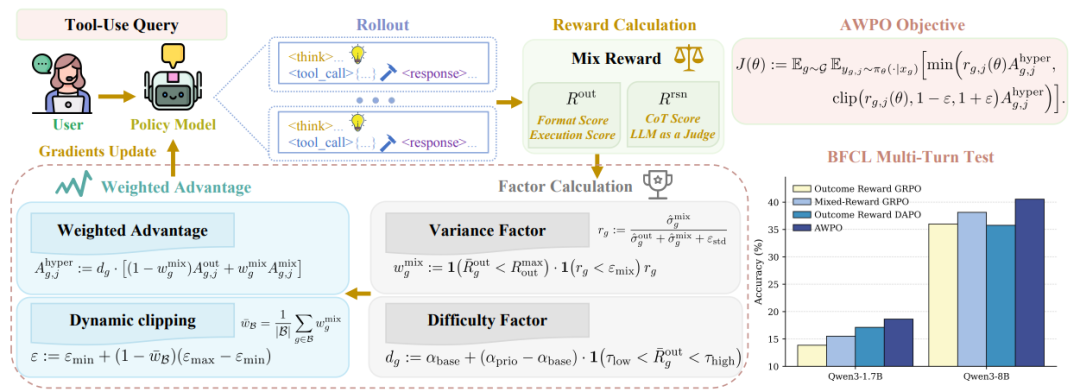
图1:AWPO框架概述。
如图1所示,研究团队首先建立了一个理论框架,用于在GRPO(Group Relative Policy Optimization)框架内结合推理奖励和结果奖励。通过推导期望策略改进的上界,团队证明了改进潜力由一个复合信号项控制。该信号项取决于优势函数与策略梯度的一致性及其方差。这一理论分析为后续的方法设计提供了指导,AWPO的核心便是动态调整优势权重,以最大化强化学习过程中的策略改进。
(1)方差感知门控机制
方差感知门控根据推理奖励与结果奖励在组内的相对方差,动态缩放推理奖励的影响。当结果奖励的判别性方差不足时,AWPO会优先引入推理奖励信号,从而避免优化陷入停滞。其形式化定义如下:
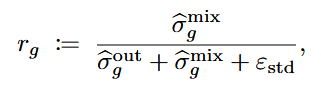
为了防止在结果目标已饱和后仍然过度依赖混合信号,研究团队引入了基于规则均值的饱和门控,其中 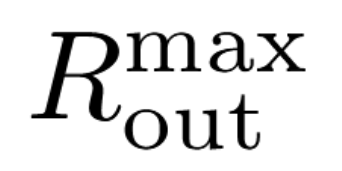 是结果奖励的峰值组均值。
是结果奖励的峰值组均值。
(2)难度感知加权
难度感知加权机制将优化焦点集中在中等难度的提示组上,通过调整组权重来最大化策略改进的潜力。权重定义为:
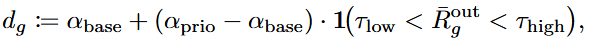
其中,α_prio > α_base 为缩放因子,τ_low 和 τ_high 为难度阈值。这种机制有效减轻了那些接近性能饱和或持续表现低下的提示组对整体策略优化的不当影响。
(3)动态剪裁机制
为了稳定优化过程,AWPO引入了动态剪裁半径,该半径会根据整个批次对细粒度信号的依赖程度来自适应调整剪裁范围:
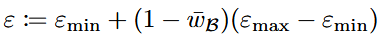
该机制能在高方差信号下收紧信任区域,从而抑制梯度噪声。这与理论见解一致:具有更高方差的信号需要更紧的信任区域来约束潜在的噪声风险。
(4)算法流程
完整的AWPO训练策略见以下算法1伪代码。

评估
(1)BFCL基准结果
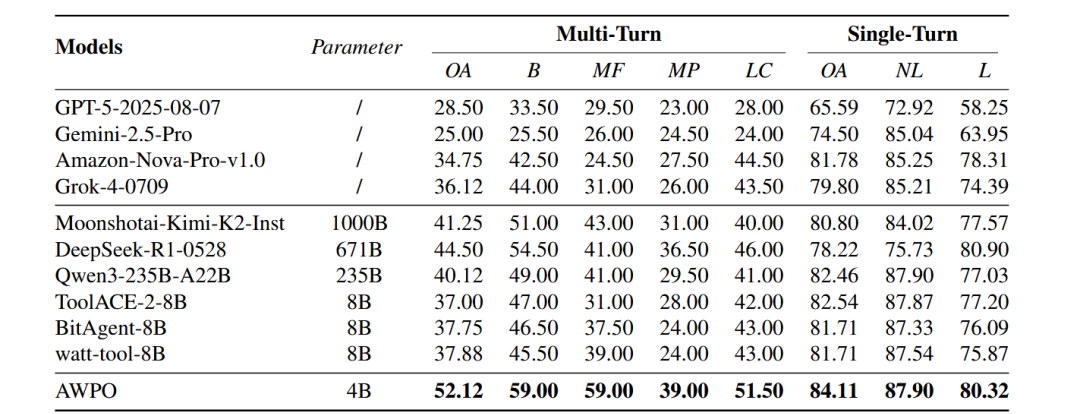
表1:不同模型在BFCL基准上的表现对比。
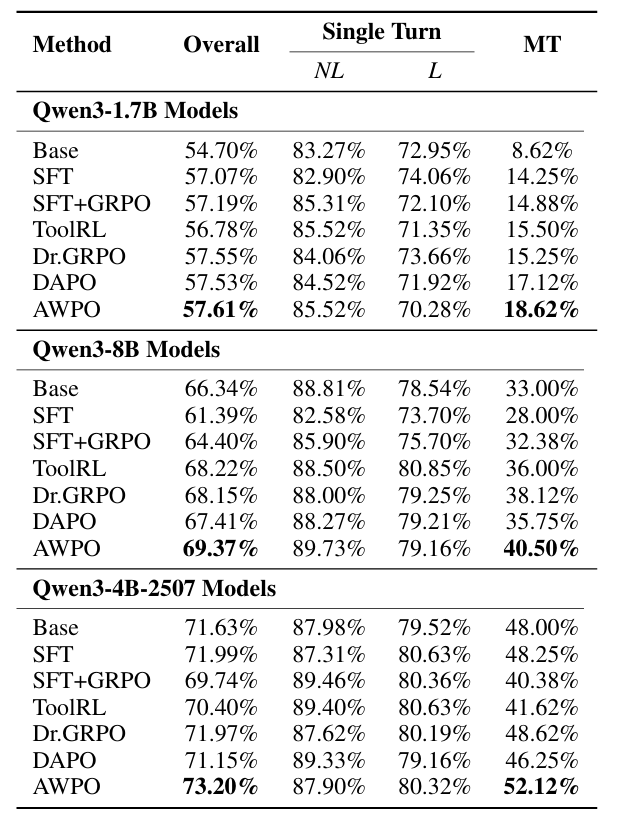
表2:不同强化学习方法在BFCL基准上的表现对比。
如表1和表2所示,在BFCL基准上,AWPO在三个不同规模的模型(Qwen3-1.7B, 8B, 4B-2507)下均取得了最强的多轮对话性能,并且没有牺牲单轮对话的准确率。
以Qwen3-4B-2507模型为例,其多轮准确率从ToolRL方法的41.62%提升到了AWPO的52.12%,绝对增益为10.50%,相对改进高达25.2%。同时,整体分数也从70.40%提升至73.20%。最佳替代RL基线Dr.GRPO取得了48.62%的多轮准确率和71.97%的整体分数,但仍分别落后AWPO 3.50%和1.23%。
表1中的外部模型排行榜进一步凸显了AWPO的算法效率优势:参数量仅4B的AWPO模型取得了52.12%的多轮整体准确率和84.11%的单轮整体准确率。这一表现显著超越了那些专为工具调用优化的8B参数量系统,如ToolACE-2-8B和wai-tool-8B。并且,4B的AWPO模型在多轮对话准确率上超过了Grok-4模型16%。这表明AWPO在模型性能与计算效率之间实现了更优的权衡。
(2)API-Bank基准结果
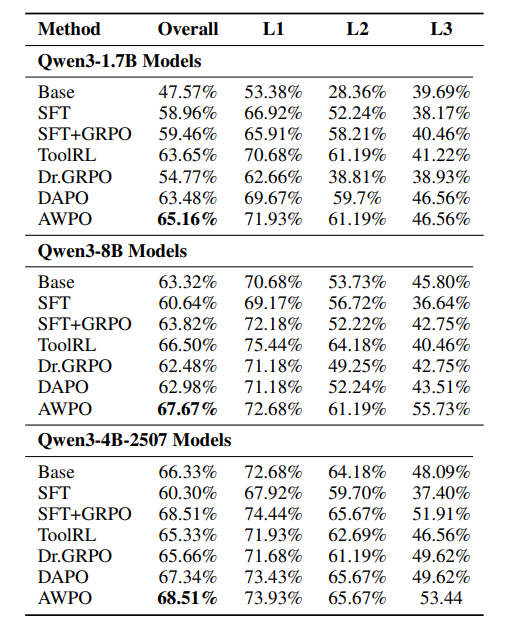
表3:不同方法在API-Bank基准上的表现对比。
在API-Bank基准上,AWPO在所有三个模型规模上实现了最强或并列最强的性能,尤其在Level-3(L3)任务上提升幅度最大,这类任务最具组合性和多步复杂性。
对于Qwen3-8B模型,AWPO将整体准确率从ToolRL的66.50%和DAPO的62.98%提升至67.67%。更突出的是,L3准确率从ToolRL的40.46%和DAPO的43.51%跃升至55.73%,相对于ToolRL的相对改进达到了37.7%。
这些结果表明,在面对具有挑战性的组合任务(L2/L3)时,AWPO通过引入细粒度的推理奖励,成功拓展了策略优化的能力边界。
(3)MMLU-Pro分布外评估
为了检验专注于工具调用的强化学习是否会损害模型的通用语言理解能力,研究团队在分布外的MMLU-Pro基准上进行了评估。
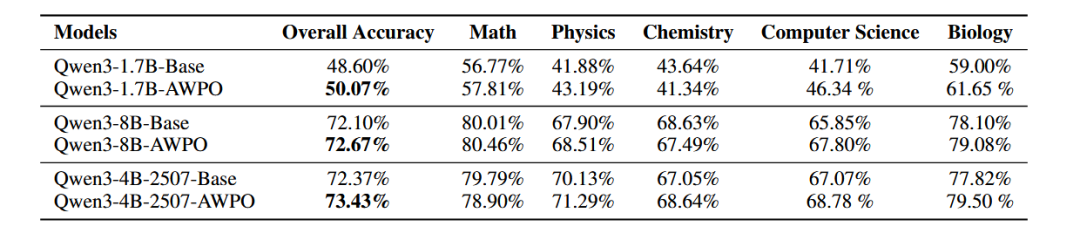
表4:在OOD MMLU-Pro基准上的表现对比。
结果显示,AWPO在所有模型规模下均保持甚至略微提升了分布外(OOD)性能:
- Qwen3-4B-2507 从 72.37% 提升至 73.43%(+1.06个百分点)
- Qwen3-8B 从 72.10% 提升至 72.67%(+0.57个百分点)
- Qwen3-1.7B 从 48.60% 提升至 50.07%(+1.47个百分点)
以上结果有力地表明,尽管AWPO的训练目标明确针对工具增强行为,但它并未导致模型对工具调用模式产生过拟合,也没有造成核心知识的退化。
(4)消融研究
研究团队在三个Qwen3主干网络上对BFCL基准进行了消融实验,以验证AWPO各个核心组件的有效性。
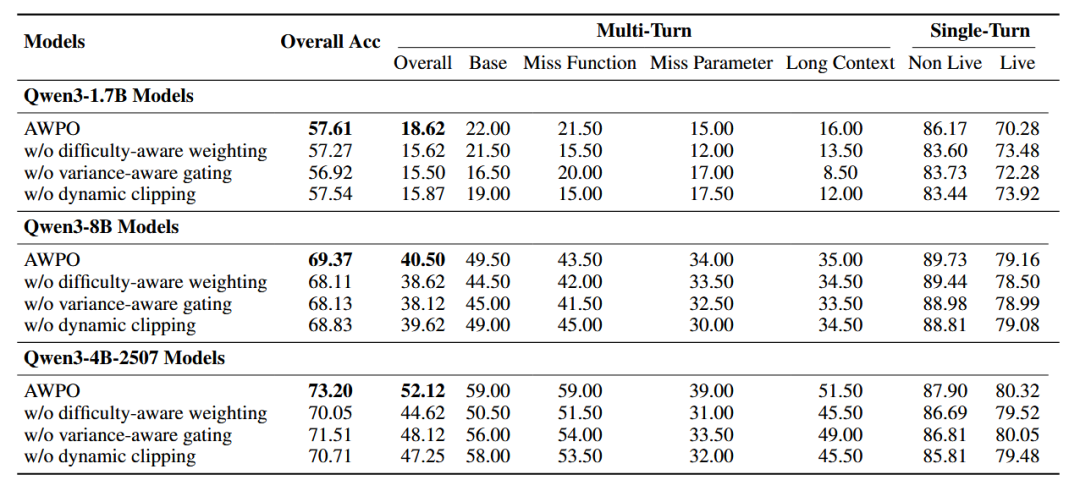
表5:在BFCL基准上对AWPO各组件进行的消融研究结果。
-
移除难度感知加权会一致地损害多轮对话性能。对于Qwen3-4B-2507,多轮整体准确率从52.12%大幅下降到44.62%,整体BFCL准确率也从73.20%下降到70.05%。
-
方差感知门控对多轮准确率同样表现出显著影响。在4B模型上,移除该机制(即仅依赖混合奖励计算优势)使多轮准确率从52.12%降至48.12%,整体准确率从73.20%降至71.51%。这些性能下降表明,方差感知门控方案比简单地混合奖励信号更为有效。
-
使用固定剪裁边界代替动态剪裁机制也会降低性能,尤其是在4B模型上最为明显。多轮准确率从52.12%下降至47.25%,整体准确率从73.20%下降至70.71%。结果表明,自适应剪裁方案通过与难度感知加权和方差感知门控互补,能够有效控制噪声同时保留有用信号。
 发表于 2026-1-5 22:35:16
|
查看: 292|
回复: 0
发表于 2026-1-5 22:35:16
|
查看: 292|
回复: 0
