很多人对 RAID 有一种普遍的误解:“只要使用了RAID,就等于数据安全了。”这句话在生产环境里,危险系数非常高。在实际案例中,RAID 出问题往往不是技术不够先进,而是对 RAID 的故障形态理解不够深入。

RAID 故障,本质上就三大类
无论你使用的是 RAID 0、1、5、6、10,还是某些厂商特有的变种,故障原因最终都可以归结为三大类:
- 单块成员磁盘故障
- 多块成员磁盘同时或先后故障
- 与磁盘无关的RAID故障(如人为操作失误、控制器故障、软件层问题)
下文我们将重点拆解 RAID 5 和 RAID 1E,因为这两种阵列模式在中小企业、NAS和通用服务器中非常常见,也最容易被“高估其安全性”。
第一类:成员磁盘故障
这是你最“幸运”的情况。
单块磁盘故障
如果RAID阵列连坏一块盘都扛不住,那它也就没资格被称为冗余磁盘阵列了。

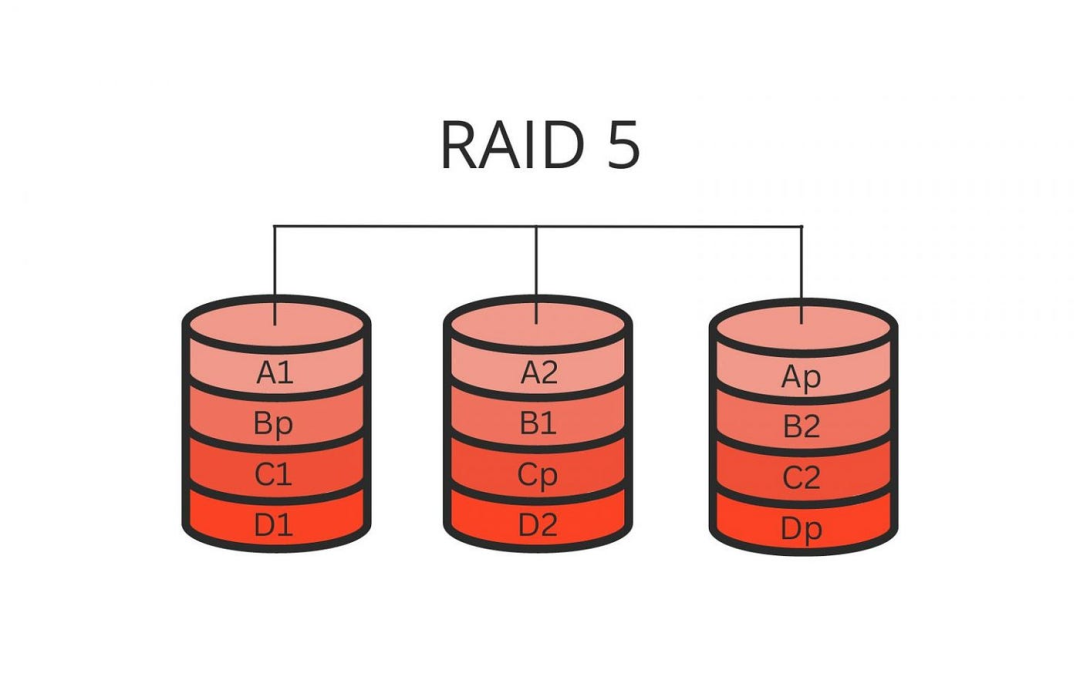
以 RAID 5 为例,它的设计目标就是:允许同时损坏 1 块磁盘而不丢失数据。
在实际环境中,故障信号通常非常直观:
- NAS设备
- 某一块盘位的状态LED灯由绿色变为红色(或闪烁橙色)。
- 设备管理界面会提示 “Degraded” 或“阵列已降级”。
- 服务器 / 软件RAID
- 硬件RAID控制器或系统日志会明确提示某块磁盘“Failed”。
- 管理工具如
mdadm、StorCLI、MegaCLI会发出告警信息。
此时,有一句非常重要的话需要牢记:阵列还能用 ≠ 阵列是安全的。
RAID在降级状态下,所有读写I/O压力都会集中在剩余的健康磁盘上,而高负载恰恰是诱发第二块磁盘故障的常见时机。
正确处理方式
- 第一时间更换故障磁盘。
- 在管理界面或通过命令行启动RAID重建(Rebuild)。
- 重建期间尽量避免高I/O负载的业务运行,以缩短重建窗口并降低风险。
如果这一套流程执行顺利,那么恭喜你,这通常是RAID故障中损失最小的一种情况。
多块磁盘故障
现在我们来谈谈更严峻的现实:RAID 5 只能容忍一块磁盘故障。
一旦出现以下任一情况:
- 同时损坏 2 块磁盘。
- 或者一块磁盘损坏后尚未完成重建,在重建过程中另一块磁盘又发生故障。
那么结果基本只有一个:阵列彻底失效,数据丢失。
常见表现
- 多个硬盘盘位的LED指示灯同时报警。
- RAID控制器本身工作正常,但阵列无法挂载(Mount)。
- 操作系统识别到的文件系统直接消失或变为RAW格式。
这时候很多人会问:“还有没有办法恢复数据?”
答案是:几乎没有完整恢复的可能。
RAID 5的数据和奇偶校验信息是分布式存储的,一旦损坏的磁盘数量超过其校验能力,缺失的数据块是无法通过数学计算还原的。

但现实没那么绝对
虽然RAID 5多盘损坏基本宣告阵列死亡,但在极少数场景下,还有可能抢救出部分文件。
能够恢复的前提通常是:
- 文件完整地存储在某一块完好的磁盘的单个条带内,没有跨盘分割。
- 文件大小小于或等于一个RAID条带(Stripe)的大小。
- 文件数据连续分布,且没有横跨到已损坏的磁盘上。
这种情况,常见于恢复:
- 小的文本配置文件。
- 部分日志片段。
- 某些独立的图片、文档文件。
但必须注意一点:这不是RAID技术在保护你,而是运气成分在起作用。 绝不能将此作为数据安全的依据。
第三类:最容易被忽视,也最危险的RAID故障
接下来这部分,是本文想重点强调的内容。
与磁盘“无关”的RAID故障
在真实生产环境中,相当比例的RAID故障,其物理磁盘本身是完好的,但阵列依然崩溃了。
常见原因包括:
- 人为误操作(例如误删除阵列、重建时磁盘顺序错误)。
- RAID控制器硬件故障或电池失效。
- RAID管理软件/驱动损坏。
- 固件Bug或升级失败导致元数据错乱。
这类故障的特点是:磁盘物理健康,但记录阵列结构的RAID元数据丢失或损坏了。
什么是RAID配置元数据?
简单来说:RAID并不是“插上几块盘就自动知道如何组织数据”。
它依赖一组关键参数来描述阵列结构,这些信息统称为元数据(Metadata),例如:
- 成员磁盘的数量和标识。
- 磁盘的顺序(谁是第 1 块盘)。
- 条带(Stripe/Block)大小。
- 数据在磁盘上的起始偏移量。
- 奇偶校验块的位置与轮转方式。
一旦这些元数据信息丢失,RAID控制器就会“失忆”,无法正确组装数据。
为什么这类故障反而更容易恢复数据?
原因很简单:
- 用户数据块还完好地保存在磁盘上。
- 数据与校验块之间的数学关系依然存在。
- 只是系统“不知道如何按照原来的规则把它们拼回去了”。
只要能通过技术手段(如人工分析或专业软件)重新识别出正确的RAID参数,就有机会:
- 在软件层面重建一个虚拟的RAID映射。
- 以只读方式挂载这个虚拟阵列。
- 成功导出其中的数据。
这也是为什么在此类场景下,专业的数据恢复服务或使用高级恢复软件进行分析的成功率相对较高。

RAID 5:为什么它常“死在大家以为最安全的时候”?
RAID 5在中小企业、NAS圈子里流行多年,但它有一个天然弱点:重建窗口期风险极高。
- 磁盘容量越大,完整重建所需的时间越长(可能长达数十小时)。
- 重建过程本身会产生持续的高强度I/O负载。
- 剩余磁盘在承受正常业务压力的同时,还要负担重建压力,第二块磁盘极容易在此关键时期发生故障。
这也是为什么现在越来越多的架构建议:
- 新环境不推荐使用RAID 5,尤其是大容量磁盘场景。
- 如果使用,必须搭配完整、独立的备份策略。
一句话总结:RAID 5 能抵抗 1 块磁盘的突然故障,但可能扛不住“漫长的重建时间 + 坏运气”。
再谈一个易踩坑的阵列:RAID 1E
RAID 1E可以理解为一种“条带化的镜像RAID”,特点是:
- 最少需要 3 块磁盘。
- 数据在相邻磁盘间进行镜像。
- 允许非相邻的磁盘同时损坏。
它常见于某些品牌(如IBM、Dell)的硬件RAID控制器中。
RAID 1E的故障特性
好消息是:
- 单盘损坏:阵列降级,但数据安全。
- 多盘损坏(非相邻):根据镜像对分布,仍可能保持部分或全部数据安全。
坏消息是:
- 相邻磁盘同时损坏 → 会导致某个数据块完全丢失(两个副本均损坏),造成数据断层。
其故障处理方式与RAID 1类似:拔掉确认故障的磁盘,保留健康磁盘,并严格遵循控制器文档进行重建操作。
经验之谈:RAID能做什么与不能做什么
最后,不讲抽象概念,讲实际经验。
RAID能做的
- 提高存储服务的可用性(在线更换故障盘)。
- 抵御少量磁盘的物理故障。
- 降低因单盘故障导致的业务中断概率。
RAID不能做的
- 不能替代备份。它防硬件故障,不防误删、病毒、软件错误。
- 不能防止人为误操作(如误删阵列)。
- 不能防止RAID控制器本身的Bug或故障。
- 不能防止多块磁盘因同一原因(如电源浪涌)同时失效。
RAID是用来“扛故障”的,不是用来“赌永远不出故障”的。

真正安全的数据架构,永远是多层次防御的结合,例如:
- RAID + 定期备份(到另一套存储或云端)。
- RAID + 异地容灾。
- RAID + 严格的人员操作流程与权限控制。
只有理解了这些故障机制,才能更好地规划与运维存储系统,避免将全部希望寄托于单一技术。关于系统运维与故障排查的更多实践,可以到专业的 运维 & 测试 板块交流学习,其涵盖的监控、自动化与日志分析等内容是保障系统稳定的重要支柱。同时,RAID技术的底层实现与磁盘调度也离不开扎实的 计算机基础 知识。
 发表于 2026-1-5 23:07:48
|
查看: 206|
回复: 0
发表于 2026-1-5 23:07:48
|
查看: 206|
回复: 0
