Trainium3是亚马逊AWS的一款3nm自研芯片,专为云端大规模AI训练和推理优化。通过提升计算密度、内存带宽与能效,提供更具成本效益的AI加速方案。该芯片支持FP8、MXFP4等多精度数据格式,并依托高带宽互连与大规模系统扩展能力,在AWS云生态内为用户提供高效、可扩展的AI计算基础设施。
本文将对Trainium3进行全面解析,涵盖其核心计算架构、内存与带宽设计、互连与系统级扩展能力,并与英伟达GB300、谷歌TPU Ironwood进行对比分析,最后探讨Trainium3面临的实践挑战及下一代Trainium4的技术方向。
AWS Trainium3 AI芯片概述
Trainium3是AWS推出的机器学习专用芯片,也是AWS首款采用台积电3nm(N3P)制程的AI芯片。单个Trainium3芯片集成八个NeuronCore-v4计算核心,延续AWS自研Neuron架构的发展路径。
与Trainium2类似,Trainium3支持逻辑神经元核心(LNC)配置,可将多个物理NeuronCore的计算与内存资源整合为单个逻辑单元,以满足更大规模模型的计算需求。下图展示了Trainium3芯片架构概览。
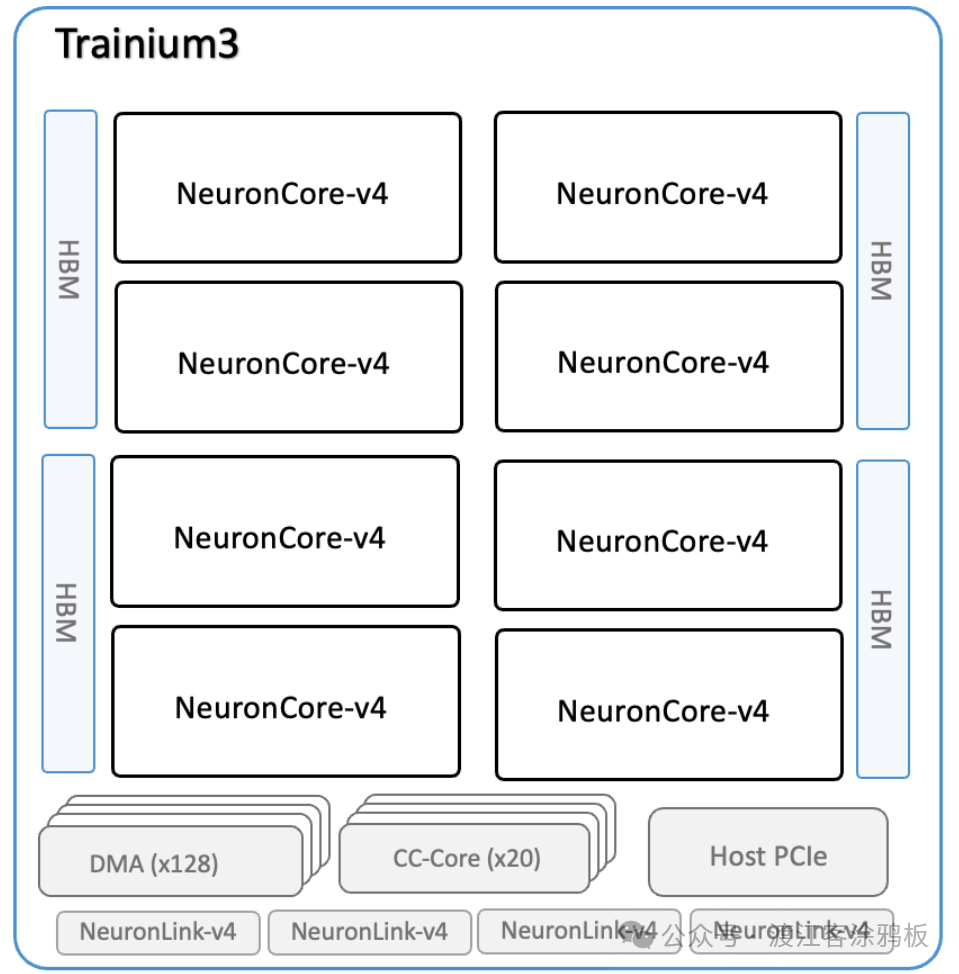
计算核心
- 3纳米制程:相比采用5纳米工艺的Trainium2,3纳米工艺显著提升晶体管密度,使单芯片能够容纳更多计算资源。Trainium3的FP8峰值算力达2.52 PFLOPs,支持在单节点上高效训练千亿参数模型。
- MXFP混合精度技术:支持MXFP8和MXFP4两种定制精度格式,可实现对BF16数据的无损量化。在保持模型精度(较FP16约降低2%)的同时,FP8算力达到2517TFLOPS,约为Trainium2的两倍,整体功耗则降低约35%。
内存与带宽
- 144GB HBM3e内存:采用12层堆叠设计,容量为上一代96GB的1.5倍,可一次性载入千亿参数模型,减少外部存储访问。
- 4.9TB/s内存带宽:引脚速率从5.7Gbps提升至9.6Gbps,整体带宽较上一代的2.9TB/s提升约70%,每秒可支持约4.9万亿字节的数据传输。
- 片上SRAM扩容:每个NeuronCore-v4集成32MB SRAM,较上一代提升约14%,高频数据访问可在片内处理,降低访问延迟。

“大显存+高带宽”的组合使得Trainium3在处理万亿参数模型时,可减少数据分片与通信开销,从而提升整体训练效率。
系统设计
- UltraServer与可扩展性:AWS将Trainium3部署于EC2 Trn3 UltraServer平台,单系统最高可集成144颗Trainium3芯片,总内存容量约20.7TB,总带宽约706 TB/s,FP8峰值算力达362PFLOPs。相比上一代平台,系统整体算力提升约4.4倍,内存带宽提升约3.9倍,单位能效提升超过4倍,支持大规模模型在同一计算域内完成训练,降低跨节点通信开销。
- 互连与散热:系统采用PCIe Gen6接口,单通道带宽达64 Gbps,为Gen5的两倍;并引入NeuronSwitch-v1全互连架构,芯片间通信能力较上一代提升约2倍。散热方面,平台采用液冷方案应对3纳米高密度计算带来的热负荷,整体PUE约1.15,低于行业常见的1.2–1.3区间。
Trainium3 vs. 英伟达GB300 vs 谷歌TPU Ironwood
从整体设计看,Trainium3更侧重于大规模云部署与成本控制,而非单芯片峰值性能。以下从多维度对Trainium3、英伟达GB300和谷歌TPU Ironwood进行系统对比。

选择Trainium3或TPU的企业通常运行在AWS或谷歌云平台上,这类企业对定制化要求低,对整体成本更为敏感。选择英伟达GPU的企业则适用于需要多场景适配,或已深度依赖CUDA软件生态的用户。部分企业采用混合架构,即在训练阶段使用Trainium3,在推理或特定优化阶段继续使用GPU,以平衡成本与灵活性。
总体而言,三者各有侧重:
- Trainium3强调云上成本与规模化部署;
- GB300侧重软件生态与算力灵活性;
- TPU Ironwood则适合深度集成谷歌生态的长期云上应用。
Trainium3未来面临的挑战
尽管Trainium3表现亮眼,但行业专家与企业客户指出其面临的现实挑战,可能影响Trainium3芯片的长期发展。
软件生态
英伟达的核心优势在于成熟的软件生态。全球超过90%的AI开发者使用CUDA,并有超过10万款第三方软件支持。相比之下,Trainium3所依赖的Neuron SDK虽支持TensorFlow和PyTorch,但在功能完整性上仍有差距。AWS Trainium项目副总裁兼首席架构师Ron Diamant表示,AWS的目标并非取代英伟达,而是为用户提供更多算力选择。
客户信任
长期使用英伟达GPU的企业客户对自研芯片普遍持谨慎态度。兼容性或稳定性问题可能严重影响生产运营。此外,Trainium3目前仅支持FP8和FP16精度,不支持FP4,限制在部分成本敏感推理场景中的应用。多数客户仍倾向于选择更成熟的英伟达GPU平台。
散热与量产风险
随着制程推进至3纳米,晶体管密度大幅提升,带来更高的功耗与散热挑战。Trainium3单芯片满载功耗约500W,较上一代提高约20%,需搭配复杂的液冷系统。这不仅增加了服务器整体成本(如Trn3 UltraServer单机售价超200万美元),也提高了系统维护的复杂性。冷却系统故障可能直接影响训练任务的连续性。此外,台积电3纳米工艺良率仍低于80%,增加了量产不确定性,可能影响AWS的算力交付进度。
展望Trainium4
下一代Trainium4将率先集成英伟达NVLink Fusion技术,实现与GPU的高效协同。AWS表示,Trainium4在设计之初就针对NVLink Fusion高速互连进行了深度优化,可在统一的MGX机架架构内与GPU、Graviton处理器及弹性结构适配器(EFA)协同工作。
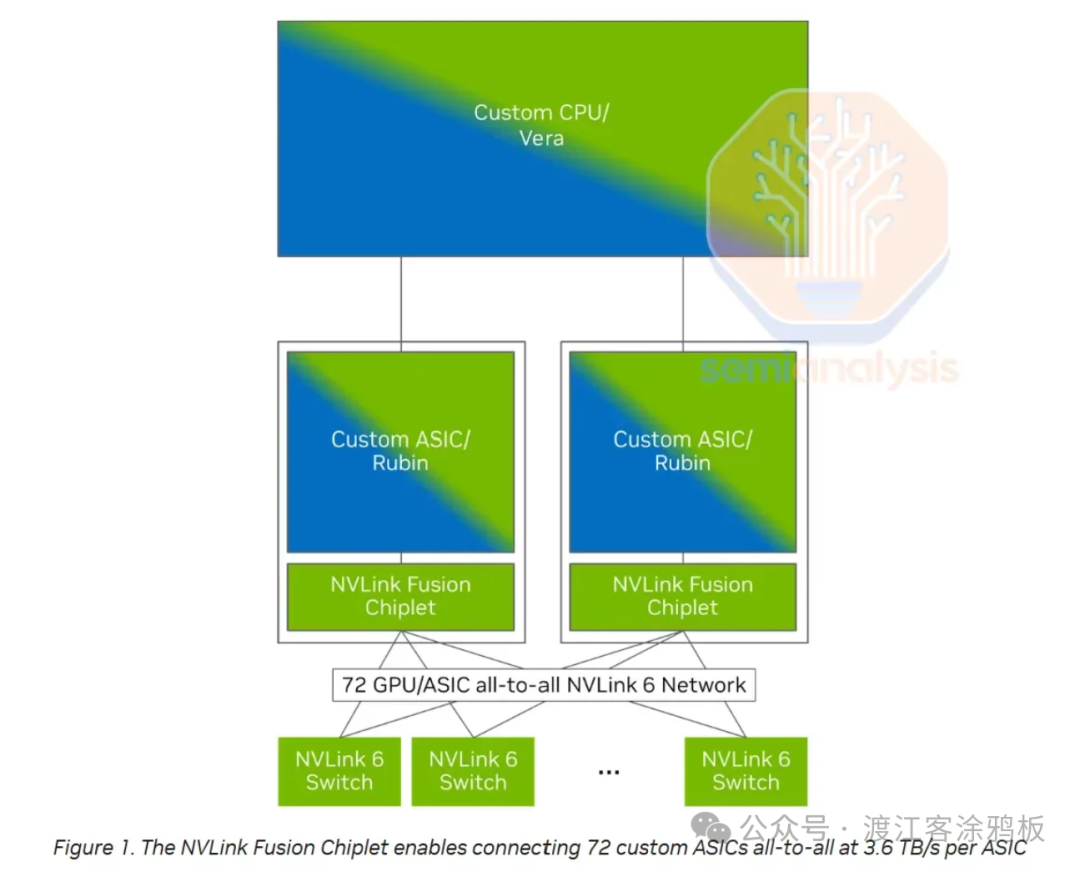
新的集成架构为数据中心提供更具成本效益的机架级AI基础设施,使得GPU与Trainium服务器可在同一平台上灵活部署、协同计算,提升整体资源利用率与系统扩展性。在性能方面,Trainium4针对下一代AI训练与推理负载进行了全面增强。官方数据显示,其算力较前代显著提升,包括FP4性能提升6倍、FP8性能提升3倍,内存带宽提升4倍。这些提升使其能够更高效地支持大模型训练与推理等高强度工作负载。
总体而言,Trainium4通过深度集成NVLink Fusion,构建了一个兼顾灵活性、性能与可扩展性的高性能AI计算平台,为未来大规模模型训练与推理场景提供了更坚实的基础设施。
结束语
Trainium3并非单纯追求峰值算力,而是在算力、内存带宽、互连效率与能效之间做出了系统级权衡。相比通用GPU与TPU,其优势与局限都较为清晰,适用性高度依赖于具体的云平台环境与工作负载类型。对于以成本效益与可扩展部署为核心需求的云端AI训练场景而言,Trainium3提供了一种具有实际意义的替代选择。
对国产算力的影响
AWS Trainium3的推出,对国产算力发展构成压力,也指明了路径。
压力在于,在3nm制程、高带宽内存(HBM3e)及系统级能效优化上树立了标杆,与英伟达、谷歌共同定义了云端AI芯片的高标准。凸显了国产芯片在先进工艺、存储技术与软硬件协同优化上的综合差距,尤其在面向大规模训练的系统级工程能力上挑战显著。
路径启示在于,首先,软硬一体与系统优化是关键。Trainium3证明,不盲目追逐单芯片峰值算力,而通过架构、互联、内存、散热和云服务的深度整合实现最优性价比,是可行的差异化路线。国产算力可借鉴此系统思维。其次,生态建设是核心。Trainium3依托AWS云生态提供“芯片即服务”,降低了用户使用门槛。国产算力亟需与国内主流AI框架、模型和应用场景深度绑定,构建从硬件到应用的垂直优化闭环。
总体而言,Trainium3加剧了高端AI算力竞争,但国产算力凭借政策支持、本土市场与自主可控需求,仍有在特定领域(如智算中心、行业大模型)构建优势生态的时间窗口。关键在于放弃单纯参数比拼,转向深耕场景、优化体验、构建可持续的商业与生态循环。对于技术爱好者而言,持续关注此类前沿硬件动态,可以在云栈社区等技术论坛与同行交流,把握行业趋势。
 发表于 2026-1-6 08:06:04
|
查看: 288|
回复: 0
发表于 2026-1-6 08:06:04
|
查看: 288|
回复: 0
