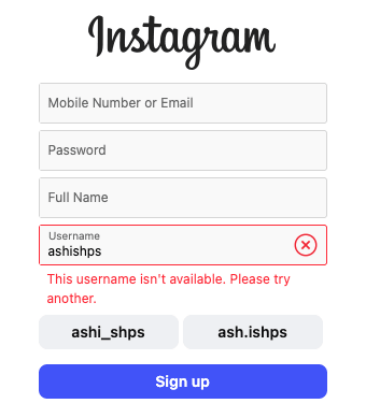
当你在 Instagram、Twitter 或 Facebook 这类平台注册时,输入心仪的用户名后,系统几乎能瞬间告诉你:这个用户名是否可用。如果已被占用,它甚至能贴心地为你推荐几个类似的备选。
对于一家仅有几千用户的小型创业公司来说,实现这个功能轻而易举:直接查询数据库即可。但对于坐拥数十亿用户的巨头们而言,情况则截然不同。每次用户注册,系统都面临着在数十亿条记录中快速定位一个特定字符串的挑战。
那么,这些平台是如何在毫秒级时间内完成这项看似不可能的任务的呢?
本文将带你层层深入,从最基础的方法开始,逐步剖析大型科技公司为此构建的复杂而精妙的架构。
第一级:直接查询数据库
检查用户名是否存在的终极方法,当然是直接询问数据库。
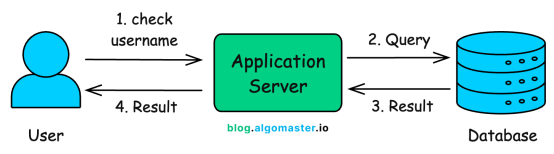
一个简单的 SQL 查询就能搞定:
SELECT COUNT(1)
FROM users
WHERE username = ‘new_user’;
如果计数大于零,说明用户名已被占用;如果为零,则用户名可用。
很简单,不是吗?对于用户量在数千乃至数百万级别的系统,这种方法完全够用。在索引完善的关系型数据库中,这种查询可以在几毫秒内返回结果。
然而,当用户规模膨胀至数亿甚至数十亿,并且数据分布在全球多个服务器与数据中心时,情况就变得复杂了:
- 索引变得臃肿:即便是 B+ 树或哈希索引这类高效数据结构,在海量数据下进行扫描和维护也变得耗时。
- 数据库不堪重负:每一次注册尝试都是一次数据库查询,这会为本就繁忙的系统带来巨大的读取压力。
简而言之,直接查询数据库虽然精确且易于实现,但面对亿级数据的实时查询需求时,性能瓶颈会立即显现。
第二级:引入缓存层
既然数据库是瓶颈,那么很自然地,我们会想到引入缓存。
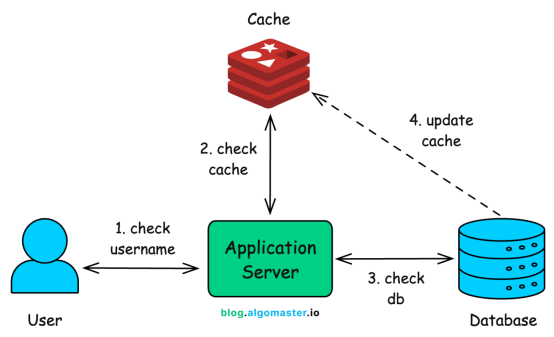
我们不再每次查询都打扰数据库,而是将最近被查询过的用户名及其结果临时存储在内存中(通常使用像 Redis 或 Memcached 这样的工具)。工作流程如下:
- 用户输入用户名:请求首先到达应用服务器。
- 缓存检查:系统首先检查缓存中是否有该用户名的最新查询结果。
- 缓存命中:立即返回结果,无需访问数据库。
- 缓存未命中:继续下一步。
- 数据库检查:如果缓存中没有,则查询数据库获取权威答案。
- 更新缓存:将数据库返回的结果(无论可用与否)写入缓存,供后续相同查询快速响应。
对于那些被频繁尝试的“热门”用户名(如 john、alex),缓存效果极佳,能瞬间响应请求。
但缓存也带来了新的权衡:
- 内存有限:不可能将数十亿用户名全部存入内存,成本过高。系统通常采用 LRU(最近最少使用) 等策略淘汰非活跃条目。
- 数据不一致:如果用户注销释放了某个用户名,但缓存尚未更新,系统仍会误判该用户名不可用。通常通过设置 TTL(生存时间)让缓存数据自动过期来缓解。
- 缓存未命中:对于一个全新的、唯一的用户名,第一次查询时仍必须访问数据库。
第三级:布隆过滤器作为“守门员”
现在,让我们引入一个更巧妙的工具:布隆过滤器(Bloom Filter)。
与其在内存中显式存储每个用户名,不如存储一个极其紧凑的“指纹”,用它来快速判断一个用户名“一定不存在”或“可能存在”。
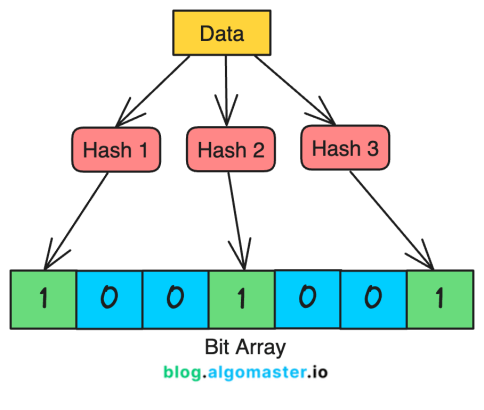
什么是布隆过滤器?
它是一种概率型数据结构,核心特性如下:
- 如果它说“不存在”,那么该用户名100%不存在于系统中。
- 如果它说“存在”,那么该用户名可能存在(有一定误报概率),需要进一步到缓存或数据库核查。
它以极小的误报率(例如1%)为代价,换来了极高的速度和极低的内存消耗。
布隆过滤器的优势
- 极度节省空间:存储约10亿个用户名的指纹,仅需约1.2GB内存(误报率1%时)。
- 查询速度极快:仅需几次内存位操作,速度远超访问缓存或数据库。
布隆过滤器如何工作?
- 初始化:创建一个所有位都置为0的大型位数组。
- 添加用户名:当用户
new_user 注册时,系统会用多个(如3-10个)不同的哈希函数处理该用户名,每个函数会计算出位数组中的一个位置,并将该位置置为1。
- 检查用户名:当检查
new_user 时,再次用同样的哈希函数计算位置。只要有一个位置的值为0,就肯定没添加过 → 用户名可用。如果所有位置的值都为1,则用户名可能已被占用(存在误报可能)。
- 处理误报:布隆过滤器显示“可能存在”时,系统会转而查询缓存或数据库进行最终确认。由于绝大多数用户名是唯一的(会被布隆过滤器判定为“绝对不存在”),只有少量请求会进入下一层。
整合全链路:一个请求的旅程
当你输入 my_cool_username 并按下回车,一个成熟的 分布式系统 内部会发生以下一系列协同工作:
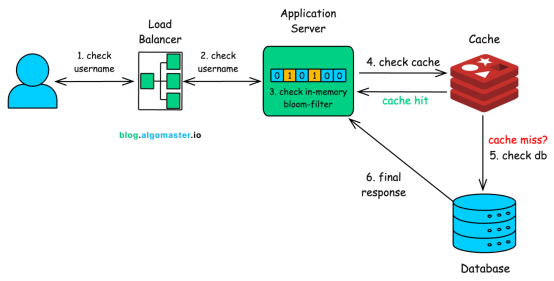
- 负载均衡器:你的请求首先被分发到最合适的应用服务器。
- 布隆过滤器(首轮筛选):服务器首先查询内存中的布隆过滤器。如果返回“绝对不存在”,系统立即返回“用户名可用”。绝大多数唯一性用户名请求在此结束,对后端零压力。
- 缓存 检查(二次核查):若布隆过滤器返回“可能存在”,则查询分布式缓存(如 Redis)。若缓存命中,返回结果。
- 数据库检查(终极裁决):若缓存也未命中,请求才会到达主数据库。这不是单台机器,而是一个可能基于 Cassandra、DynamoDB 或 Spanner 的分布式数据库集群。底层索引(如 B+ 树)确保了即使在庞大数据集下,查询复杂度仍能维持在 O(log n) 级别。
- 响应与更新:数据库返回最终结果。在返回给用户的路径上,该结果会被写回缓存,以供后续快速查询。
这种分层漏斗式设计,确保每一层都过滤掉大量请求,最终只有极小比例的请求需要触及耗时、昂贵的数据库查询。
第四级:不止于查重——用户名推荐
真实的平台如 Instagram 做得更多:当首选用户名不可用时,它们会智能地推荐替代用户名。
例如,当 daniel 被占用时,它可能推荐 daniel_123、daniel_dev 或 daniel2025。
实现这类功能,需要比缓存或布隆过滤器更智能的数据结构:前缀树(Trie,又称字典树)。
什么是前缀树?
它是一种树形数据结构,按字符串的公共前缀来组织。例如,daniel 和 danny 会共享 d-a-n 这个路径。
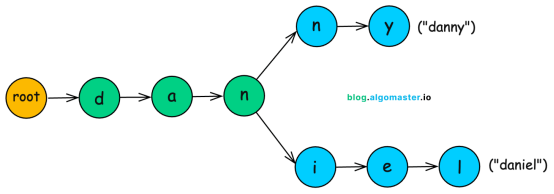
前缀树解锁了数据库和缓存难以高效实现的功能:
- 极速查找与前缀匹配:检查
daniel 是否存在,只需经过6个节点(字符串长度),与系统总用户名数量无关。同时,它能轻松找出所有以 dan 开头的用户名。
- 智能推荐:基于共享的前缀路径,生成
daniel_dev、daniel2025 等变体推荐变得非常高效。
当然,前缀树也有其代价:
- 内存消耗可能较大:如果用户名间公共前缀很少,树会变得非常稀疏,占用大量内存。
- 更新开销:在分布式环境中实时增删用户名需要复杂的同步机制。
为了优化内存,业界常使用其变体——压缩前缀树(Radix Tree),它将单子节点链合并,显著节省空间并减少查找步骤。
从直接查询数据库,到引入缓存,再到使用布隆过滤器进行海量数据的一级拦截,最后利用前缀树提供增值服务,这背后体现的是 系统架构设计 中经典的分层与权衡思想。每一层都针对特定问题进行了优化,共同构建出一个既能应对十亿级数据量,又能保持毫秒级响应的高可用服务。如果你对这类高并发、数据结构 与系统设计话题感兴趣,欢迎在云栈社区与我们继续深入探讨。
 发表于 2026-1-10 00:34:57
|
查看: 196|
回复: 0
发表于 2026-1-10 00:34:57
|
查看: 196|
回复: 0
