你是否想过,一个基于单线程的 Redis 如何能够支撑起每秒百万级的请求?这背后并非魔法,而是其精妙的事件驱动架构、极致的内存操作以及对操作系统底层IO复用机制的深度运用。本文将深入解析 Redis 实现超高并发的几个核心技术支柱。
事件驱动设计
Redis 的核心在于其单线程的事件驱动模型。它使用一个主线程来处理所有网络 I/O 和命令执行,避免了多线程环境下频繁的上下文切换和锁竞争带来的巨大开销。通过结合 epoll(Linux)或 kqueue(BSD)等系统提供的非阻塞 I/O 接口,Redis 构建了一个高效的事件循环(Event Loop)。
在这个循环中,Redis 可以监听成千上万个客户端套接字上的事件(可读、可写),并将就绪的事件分发给对应的处理器。这种设计保证了即使在海量连接下,每个请求都能得到极低延迟的响应。
内存操作:速度的本质
Redis 速度快的根本原因在于其纯内存操作。让我们对比一下不同存储介质的访问速度:
- 内存访问:约 100 纳秒 (ns)。
- 固态硬盘 (SSD) 随机读写:约 100,000 纳秒 (100 µs)。
- 机械硬盘 (HDD) 寻道:约 10,000,000 纳秒 (10 ms)。
从数据可以看出,内存的读写速度比 SSD 快约 1000 倍,比机械硬盘快约 10 万倍。Redis 将所有数据存放在内存中,直接绕过了最耗时的磁盘 I/O 瓶颈,这是其能够实现超高吞吐量的物理基础。

非阻塞 I/O 机制
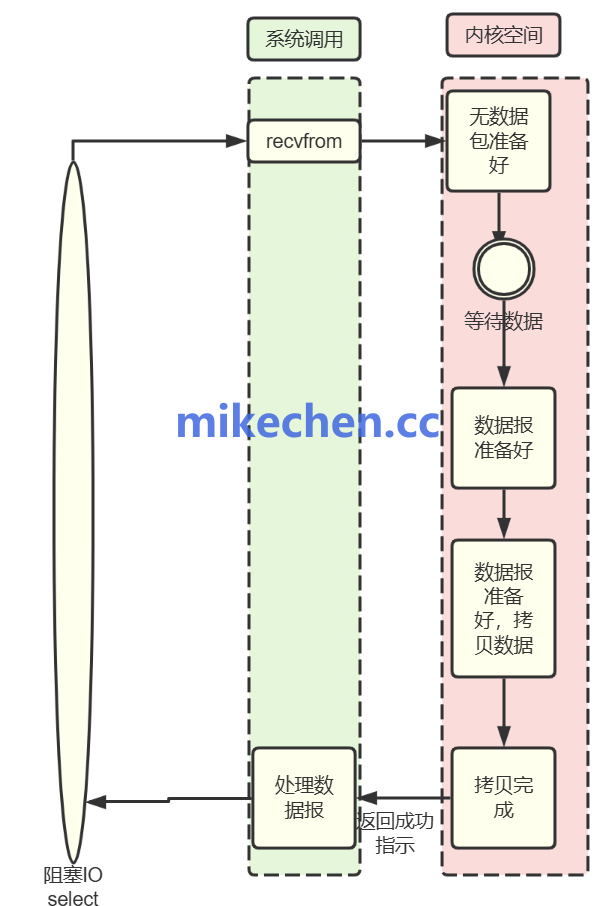
传统阻塞 I/O 模型中,当线程执行 read() 或 write() 系统调用时,如果数据未就绪,线程会被挂起,直到数据准备好。这在面对大量慢客户端或网络抖动时,会严重拖累整个服务的吞吐能力。
Redis 在处理网络 I/O 时,使用了非阻塞套接字。当一个 read() 操作没有数据可读时,函数会立即返回一个错误码(如 EAGAIN),而不是让线程傻等。线程可以立即转去处理其他已经就绪的连接。
这种机制的核心价值在于:
- 慢客户端不会拖垮快客户端:某个连接的网络速度慢,不会阻塞其他连接的处理。
- 单线程服务海量连接:即使只有一个线程,也能同时管理与处理数万乃至数十万的连接。
- 提升系统健壮性:网络抖动不会演变为整个系统的服务阻塞。
I/O 多路复用:海量连接的管理员
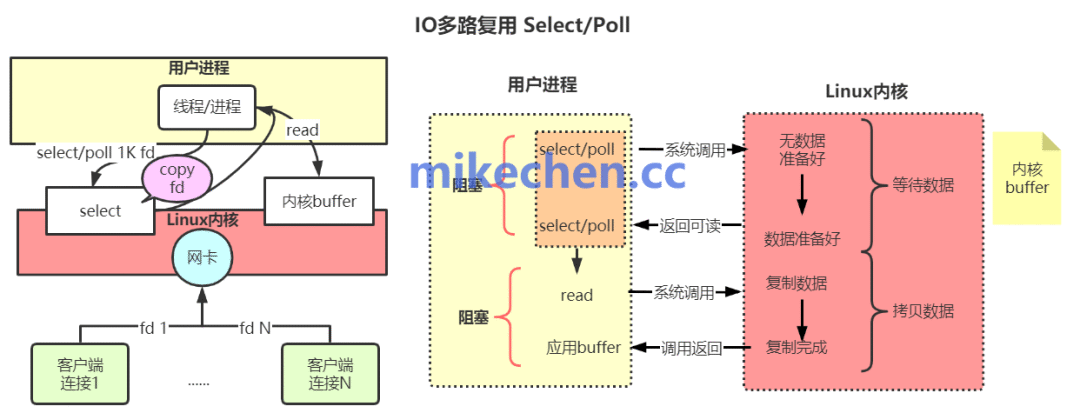
非阻塞 I/O 解决了单连接上的阻塞问题,但如何高效地监控成千上万个连接的状态呢?这就是 I/O 多路复用技术登场的时候。Redis 正是利用操作系统提供的 epoll、kqueue 或 select 等系统调用,实现了对海量连接的高效管理。
简单来说,I/O 多路复用允许一个线程监听多个文件描述符(即客户端连接)上的事件。当任何一个被监听的描述符上发生了感兴趣的事件(如数据可读),内核就会通知应用程序。Redis 的事件循环收到通知后,就知道哪些连接已经准备好了,然后只对这些就绪的连接进行实际的读写操作,避免了无效的轮询。
正是 “单线程事件循环 + 非阻塞 I/O + I/O 多路复用” 这套组合拳,使得 Redis 能够用最少的线程资源,优雅地承载极高的并发连接数,同时保持亚毫秒级的响应速度。这不仅是 Redis 的设计哲学,也是构建现代 高并发 系统值得借鉴的核心思想。
希望本文对你理解 Redis 的高性能原理有所帮助。更多关于系统架构、分布式技术的深度讨论,欢迎在 云栈社区 交流分享。 |  发表于 2026-1-11 00:47:37
|
查看: 166|
回复: 0
发表于 2026-1-11 00:47:37
|
查看: 166|
回复: 0
