在分布式搜索领域,Elasticsearch 几乎是高性能查询的代名词。
你是否想过这样的场景:在日志系统中查询刚刚报错的堆栈信息,面对亿级数据量,为什么 ES 依然能在毫秒级返回结果?更令人惊讶的是,数据刚刚写入,仅仅过了不到一秒,就能被检索到。
这并非真正的“实时”,而是 ES 一直宣称的 “近实时”(NRT,Near Real-Time) 特性。这一个“近”字背后,隐藏着 Elasticsearch 为实现超高速搜索与高吞吐写入而做出的精妙架构权衡。
01 超快查询的基石:Lucene 与倒排索引
在深入探讨“近实时”之前,我们必须先理解 ES 为什么能“快”。如果底层存储结构不支持极速查找,任何上层优化都将是徒劳。
ES 查询速度的核心,源于其底层的 Lucene 引擎,以及一种被称为 倒排索引(Inverted Index) 的数据结构。
Apache Lucene
Lucene 是 Apache 软件基金会维护的一个开源的 Java 库,专门用于全文检索和信息检索。 它提供了强大的底层索引和搜索功能,例如文本分词、倒排索引创建、相关性计算等。
Lucene 的核心功能包括:
- 文本分词和分析:将文本切分成词条,便于索引和搜索。
- 倒排索引:创建倒排索引结构,便于快速检索包含特定词条的文档。
- 查询解析:支持多种查询(布尔查询、短语查询、范围查询等),并计算文档与查询的相关性分数。
- 排序和打分:根据查询与文档的匹配程度对结果进行排序。
- 全文检索:高效实现了全文搜索的复杂算法。
需要注意的是,Lucene 是一个库,并非一个独立的搜索服务。它需要开发者编写代码来交互并构建索引和查询。而 Elasticsearch 正是构建在 Lucene 之上的分布式搜索引擎,它封装了 Lucene 的功能,提供了更多特性和用户友好的 REST API。可以说,Lucene 是 Elasticsearch 的核心引擎,负责最核心的搜索、索引和分析功能。
倒排索引
传统的关系型数据库(如 MySQL)通常采用正向索引,即通过文档 ID(行 ID)去查找该行的内容。这种方式用ID查询速度很快,但对于全文检索(如 LIKE ‘%keyword%’)则效率低下,往往需要全表扫描。
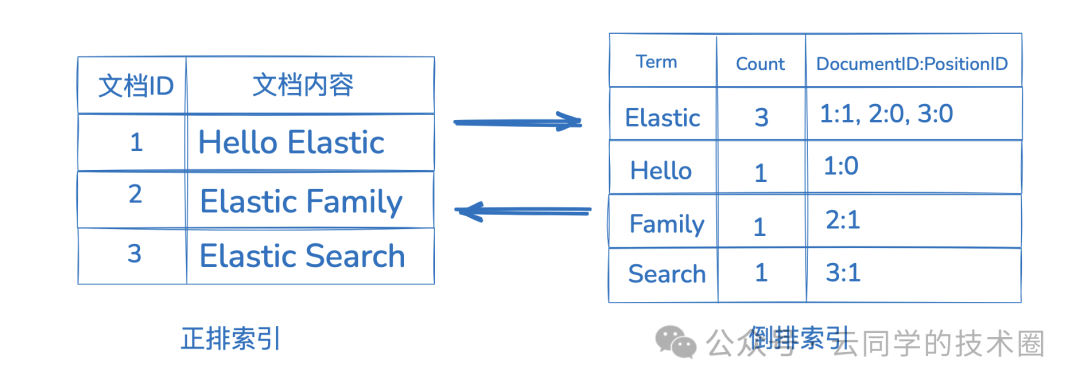
倒排索引则完全颠倒了这种关系。如上图所示,它的核心结构是一个 从词项(Term)到包含该词项的文档列表(Posting List)的映射。
当用户搜索一个词时,ES/Lucene 直接在词典中定位该词,然后立即获取包含该词的文档 ID 列表,无需扫描任何文档。这使得全文本匹配查询的速度接近常数时间复杂度 O(1),是全文检索快的根本原因。如果你对这类高效数据结构的应用感兴趣,可以深入探索我们的数据库/中间件/技术栈板块。
02 从写入到可查:近实时(NRT)的诞生
Elasticsearch 的近实时特性,是其数据持久化机制与可搜索性之间巧妙平衡的结果。
例如,当我们向 ES 发送一条写入文档的请求时,数据并不会立刻存入磁盘,也不会立刻被搜索到,它会经历以下几个关键阶段:
POST /logs/_doc
{
"level": "INFO",
"message": "order created",
"timestamp": "2025-12-12T10:00:00"
}
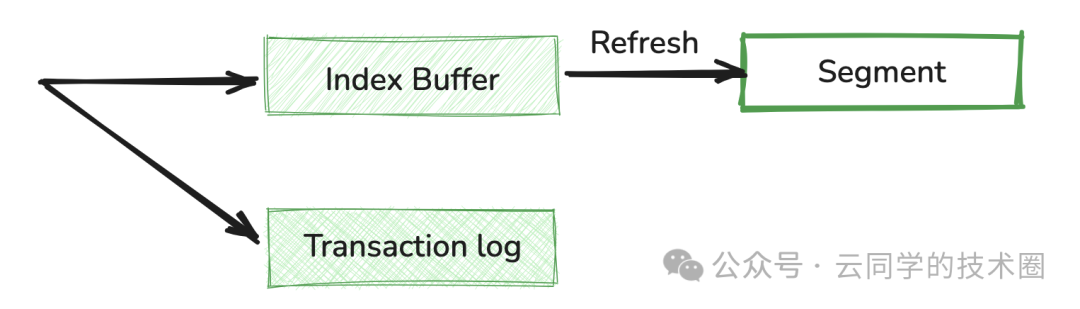
1、写入 Index Buffer
当写入请求到达 ES 节点后,数据首先会被写入 Indexing Buffer(索引缓冲区),这是一个按分片(shard)维度维护的内存区域。此时,数据暂存于内存中,还不可被搜索。
2、同时写入 Transaction log
为了保证数据的持久性和可靠性,ES 采用了预写日志(Write-Ahead Log, WAL)机制,即 Translog(事务日志)。
- 作用:确保即使发生硬件故障、进程崩溃,已接收但尚未提交到永久索引的文档也不会丢失。
- 工作方式:每个索引操作(增删改)在写入内存缓冲区的同时,会追加写入到分片所在的磁盘 Translog 文件中。默认情况下,Translog 在每次操作后都会同步刷新到磁盘。
- 持久性保证:只要文档写入了 Translog 并同步到磁盘,即使 Lucene 索引本身还未落盘,它也被认为是持久的。
3、Refresh:变为可查的关键一步
要让内存中的文档变得可搜索,必须执行 Refresh(刷新) 操作。这是实现“近实时”最核心的一步。
- 刷新机制:Refresh 操作会清空 Index Buffer,并将其中的文档转换为一个新的、内部的 Lucene 段 (Segment) 文件。
- 段的打开:这个新创建的段会被“打开”,并立即对搜索可见。
- 关键点在于,此时的 Segment 仍然驻留在操作系统的文件系统缓存(OS Cache)中,尚未写入物理磁盘。
- 延迟的来源:默认情况下,
index.refresh_interval 设置为 1 秒。这意味着从文档被索引到它能被搜索到,通常会有 0 到 1 秒的延迟。这就是“近”实时的来源。
理解 NRT 的核心:
- Segment 是 Lucene 的最小、可搜索的索引单元。一旦数据变成 Segment,它就拥有了倒排索引结构。
- 数据被写入操作系统的 FileSystem Cache 即可被搜索,避免了缓慢的磁盘 I/O(尤其是随机写)。这种用内存速度换延迟的策略,是 ES 实现“秒级”可见性的关键。
4、Flush:真正的数据落盘
随着时间推移,Translog 会不断增长。ES 需要定期执行 Flush 操作来确保数据最终持久化并清理 Translog。
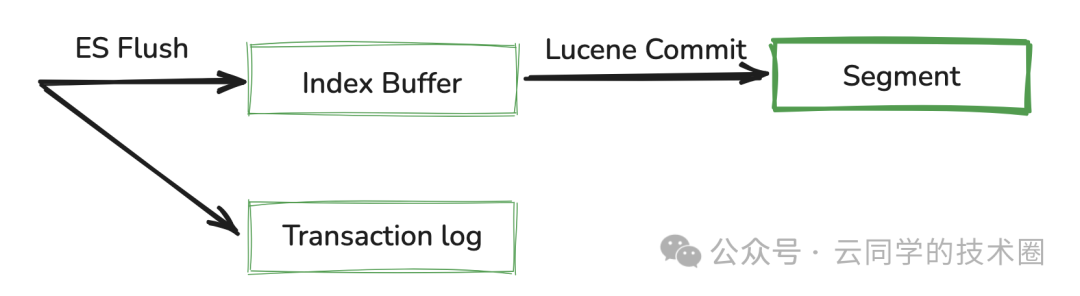
一次 Flush 操作通常包含:
- 执行一次 Refresh:确保所有内存中的文档都变成可搜索的段。
- 强制同步 (fsync):调用 Lucene 的 commit 操作,将所有内存中的段数据同步到磁盘的永久存储中。此时 Segment 才真正写入物理磁盘。
- 清空 Translog:在所有段文件安全写入磁盘后,当前的 Translog 文件会被清空(或归档),并开始新的记录。
Flush 的频率远低于 Refresh,通常每 30 分钟自动执行一次,或在 Translog 文件达到一定大小时触发。
正是通过 内存缓冲(Index Buffer/Translog) -> Refresh(可见) -> Flush(持久化) 的精巧三步走策略,ES 在吞吐量、可靠性和查询延迟之间取得了最佳平衡。
03 Segment 的不可变性与合并
ES 能保持高效查询,还有一个重要前提:Segment 的特性。
Segment 特性
Segment 是:
- 不可变(Immutable) 的索引文件。
- 包含完整的倒排索引结构。
- 一旦生成,便只读不写。
这些特性带来了巨大优势:
- 无需加锁:查询线程在读取段时,完全不用担心数据被写入线程修改,因此无需复杂的锁机制,极大提升了并发查询效率。
- 高效缓存:操作系统可以将这些不可变的文件完美地缓存在文件系统缓存中,后续的读取几乎全是内存操作。
Segment 合并(Merge)
由于默认每秒一次 Refresh,索引会产生大量小 Segment。长期积累会导致文件句柄耗尽,查询时也需要合并扫描过多段,性能下降。
为此,ES 后台有一个独立的 Merge 线程执行合并操作:
- 选取一些小的 Segments。
- 将它们合并成一个更大的 Segment。
- 在合并过程中,真正剔除那些被标记为“已删除”的文档(Lucene 删除是标记删除)。
- 合并完成后,删除旧的小 Segments。
Merge 是必要的后台 I/O 密集型操作,它会占用一定的磁盘和CPU资源,但能保证索引结构保持最优状态,从而维持前端查询的高性能。这类后台优化任务是构建稳定后端 & 架构的重要考量。
04 分布式架构带来的查询加速
作为一个分布式系统,Elasticsearch 的架构本身也为其查询性能提供了巨大助力。
1、分片与副本
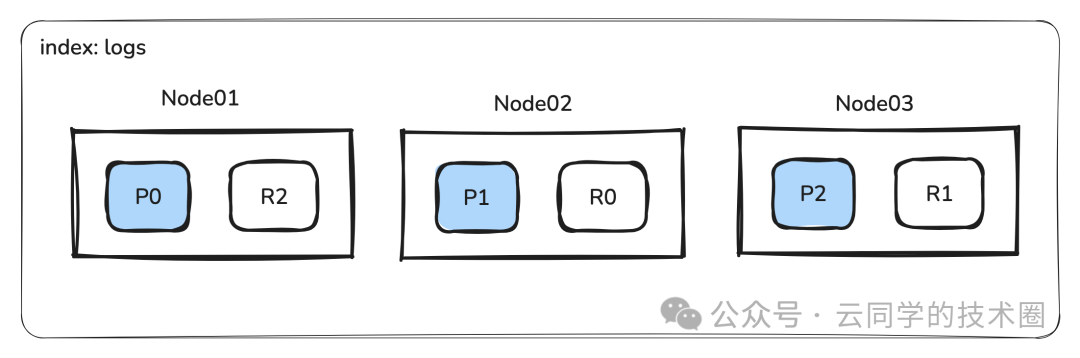
- 分片:ES 将一个索引分解成多个独立的 Lucene 索引(主分片),分布在不同节点上。
- 并行查询:当一个搜索请求到达时,查询会被分发到所有相关的主分片或副本分片上,并行执行。
- 横向扩展:通过增加节点和分片数量,系统可以线性扩展其处理能力,以应对大规模数据和高并发查询。
2、两阶段查询过程
阶段一:查询阶段 (Query Phase)
- 接收请求:任何节点都可接收请求,成为协调节点。
- 分发查询:协调节点将请求发送给索引的所有相关分片。
- 本地执行:每个分片在本地执行查询,找出匹配的文档。
- 返回局部结果:每个分片只返回文档 ID 和相关性得分给协调节点。此阶段不获取完整文档内容。
阶段二:取回阶段 (Fetch Phase)
- 收集与排序:协调节点收集所有分片的结果,进行全局排序,确定最终要返回的 Top N 文档。
- 批量取回:协调节点向持有这些文档 ID 的分片发起批量 Multi-Get 请求。
- 返回结果:分片将完整的文档内容返回给协调节点,由协调节点组装后返回给用户。
这种 “先并行定位,再集中取数” 的两阶段设计,将计算密集型的搜索和评分工作分散到各个节点,协调节点只负责轻量的聚合排序,从而在分布式环境下实现了极高的查询效率。这种设计模式是分布式系统中的经典实践。
05 写在最后
通过以上原理分析,我们可以清楚地看到,Elasticsearch 非常适合日志分析、搜索系统、可观测性平台等对搜索性能要求高、允许毫秒级延迟的场景。但它并不适用于需要强一致事务或严格实时读写的业务。
“从写入到可查”的整个过程,深刻体现了 Elasticsearch 架构设计的精妙之处:它通过巧妙地牺牲严格的“实时”性,换取了惊人的索引吞吐量和查询速度。借助 Lucene 强大的底层能力与自身卓越的分布式协调机制,Elasticsearch 当之无愧地成为构建现代高性能搜索与分析平台的首选工具。希望本文的解析能帮助你更好地理解其内部工作机制,如果你想就相关技术进行更深入的交流与探讨,欢迎来云栈社区与更多开发者一起学习成长。
 发表于 2026-1-12 02:34:47
|
查看: 120|
回复: 0
发表于 2026-1-12 02:34:47
|
查看: 120|
回复: 0
