今天要分享的是腾讯最新开源的项目:WeKnora 。这是一个源自微信对话开放平台的企业级RAG(检索增强生成)框架,核心能力在于文档理解与语义检索。
其GitHub仓库的热度增长迅猛,项目开源不到10天,就已收获超过 3,377 个星标,总星标数目前达到了 11.2k ,显示了开发者社区对其的高度关注。

WeKnora官网 :https://weknora.weixin.qq.com
GitHub仓库 :https://github.com/Tencent/WeKnora
这并非一个简单的工具,而是一个完整、基于大语言模型的文档理解与检索框架,旨在处理各种复杂的非结构化文档,包括PDF、Word、图片、合同和报告等。无论企业内部文档的结构多么混乱,它都能进行有效解析,并构建成一个可以进行智能对话的“知识大脑”。目前项目已迭代至 v0.2.0 版本。
01 v0.2.0 版本核心更新
🤖 Agent模式:新增ReACT Agent模式,支持调用内置工具、MCP工具和网络搜索
📚 多类型知识库:支持FAQ和文档两种类型知识库,新增文件夹导入、URL导入、标签管理和在线录入功能
⚙️ 对话策略:支持配置Agent模型、普通模式模型、检索阈值和Prompt
🌐 网络搜索:支持可扩展的网络搜索引擎,内置DuckDuckGo搜索引擎
🔌 MCP工具集成:支持通过MCP扩展Agent能力,内置uvx、npx启动工具,支持多种传输方式
🎨 全新UI:优化对话界面,支持Agent模式/普通模式切换
⚡ 底层升级:引入MQ异步任务管理,支持数据库自动迁移
02 三大核心亮点
第一,多格式通吃。框架支持处理PDF、Word、TXT、Markdown以及包含文字的图片(支持OCR识别)。即使是图文混排的复杂文档,也能精准提取出结构化的内容。这对于拥有大量历史遗留、格式混乱文档的企业而言,无疑是一个高效的解决方案。
第二,混合检索,精准命中。WeKnora采用了混合检索策略,同时支持关键词检索(如BM25算法)、向量语义检索以及知识图谱增强检索。用户可以根据需求自由组合这些策略。例如,可以先用关键词进行快速筛选,再利用向量检索把握语义相似度,最后通过知识图谱理解概念间的深层关联,从而在保证查全率的同时,极大提升查准率。
第三,开箱即用,自由定制。项目提供了完整的Docker化部署方案和直观的Web管理界面,降低了使用门槛。最关键的是,它采用了 MIT开源协议 ,这意味着开发者可以 自由修改、使用,甚至用于商业产品,几乎没有任何限制 。
有开发者在社区讨论时询问:“可以自己二次开发,商业化吗?”答案非常明确:完全可以,MIT协议赋予了极大的自由度。
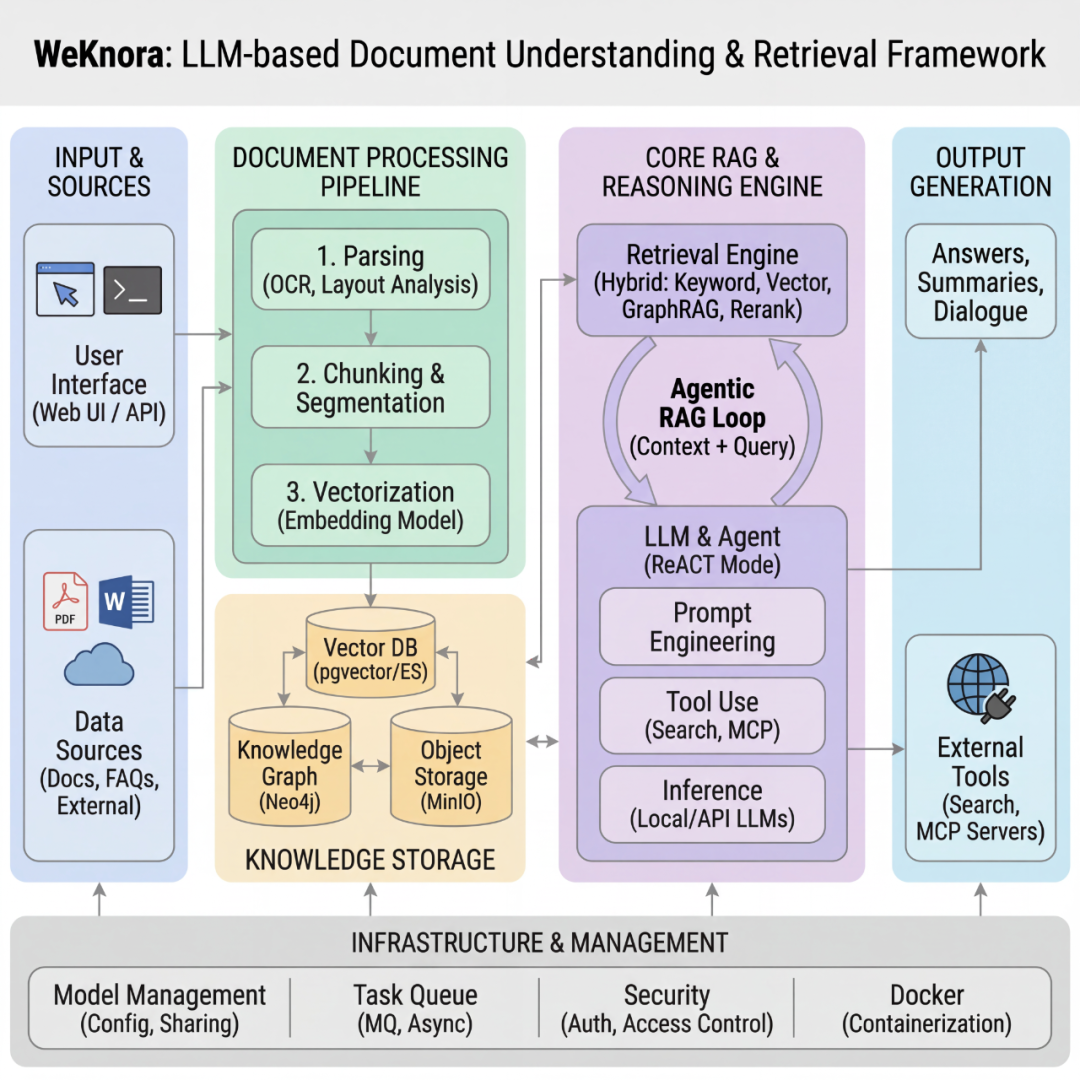
WeKnora 采用现代化模块化设计,构建了一条完整的文档理解与检索流水线。系统主要包括文档解析、向量化处理、检索引擎和大模型推理等核心模块,每个组件均可灵活配置与扩展。
03 真实对比:它适合谁?
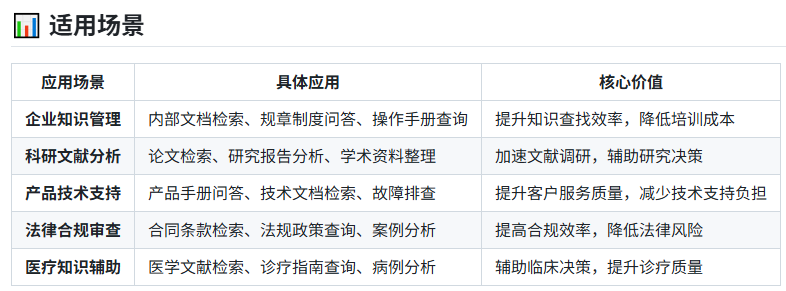
看到这里,你可能会产生疑问:市面上已经有不少RAG工具,WeKnora的差异点在哪里?从开发者和用户的反馈来看,WeKnora的定位非常清晰:它并非追求大而全的全能平台,而是一个“专注、可深度定制”的RAG开发框架。
有用户评论道:“和RAGFlow比起来效果如何?没对比过,不过部署没RAGFlow麻烦,这个比较纯粹。” 确实,与Dify、RAGFlow等提供低代码或无代码体验的平台相比,WeKnora更像一把 锋利的手术刀 ,为开发者提供了代码级的控制能力:
| 对比项 |
WeKnora |
Dify/RAGFlow等平台 |
| 核心定位 |
RAG应用开发框架 |
低代码AI应用平台 |
| 特点 |
轻量、模块化、代码级控制 |
功能集成度高、开箱即用 |
| 灵活性 |
极高,各环节可深度定制 |
相对较低,受限于平台预设功能 |
| 适合谁 |
开发者、需要深度定制的技术团队 |
追求快速上线、非技术背景的团队 |
另一位用户提出:“都是企业做RAG知识库,还在跑Dify要换阵营吗?” 其实没必要。如果企业已经采购了Dify企业版并且运行良好,完全可以继续使用。但如果你对现有方案的灵活性不满意,需要更轻量、更自主的控制权,或者技术团队希望基于一个坚实的框架进行深度二次开发,那么WeKnora就是更合适的选择。
也有用户将其与Obsidian + Copilot插件进行比较,但这实际上是两个不同维度的产品。Obsidian + Copilot是增强个人知识管理的效率工具,而WeKnora是企业级、可集中部署的知识库问答系统。前者是你的智能个人笔记本,后者则是公司内部的智能公共图书馆管理员。
04 关于本地部署与“幻觉”问题
许多人关心:“它支持本地部署模型吗?效果如何?”
答案是肯定的,并且对本地部署相当友好。WeKnora支持集成Ollama,可以方便地在本地运行各种开源大模型。有用户明确指出:“支持ollama部署本地模型,本质就是个调用大模型的客户端。和你部署不部署大模型没有关系。”
如果不想在本地承担大模型推理的硬件成本(毕竟对算力要求较高),完全可以采用混合架构:将WeKnora的核心服务部署在本地或私有云,确保文档数据的处理与检索安全可控;然后通过API接入云端的大模型服务(如DeepSeek、硅基流动等)进行复杂的推理生成。这样既保障了数据安全,又利用了云端模型的强大能力。
至于资源占用,有用户反馈:“不用本地模型的话,能跑win10的电脑就行。” 这说明仅运行框架本身的资源需求并不苛刻。
关于大模型常见的“幻觉”(即生成不准确或虚构信息)问题,有用户提到:“ima自己本身幻觉就很严重,这个可自定义大模型,应该可以调。” 这恰恰是WeKnora的一个优势——模型无关性。如果某个模型幻觉严重,你可以随时切换成效果更好的模型。更重要的是,RAG机制本身通过“先检索,后生成”的流程,将大模型的回答牢牢锚定在检索到的文档依据上,能够从原理上大幅减少幻觉的产生。
05 快速上手体验
想要立即体验?只需准备好Docker环境,按照以下步骤操作即可:
# 1. 克隆代码仓库
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora
# 2. 配置环境变量(按需修改)
cp .env.example .env
# 3. 一键启动所有服务
./scripts/start_all.sh
启动成功后,在浏览器中打开 http://localhost 即可访问初始化页面。系统会引导你完成基础配置,包括选择使用本地Ollama模型还是接入云端大模型API。
Mac用户请注意:有用户询问苹果电脑如何安装。答案是,只要使用Docker,部署流程在各个操作系统上都是一致的,Docker有效屏蔽了底层系统的差异。
启动后,你可以通过其Web UI进行知识库管理和对话测试。

更详细的安装步骤和配置说明,请参阅项目的中文README文档:
https://github.com/Tencent/WeKnora/blob/main/README_CN.md
06 总结
腾讯此次采用MIT协议开源WeKnora,延续了其在基础设施层面积极回馈开源社区的风格。对于开发者生态而言,这意味着你可以基于一个经过腾讯微信平台大规模实践验证的开源框架,快速构建自己的智能知识库、客服系统或内部助手,无需从零开始造轮子。
对于企业用户,这提供了一个更可控、可深度定制、且成本更优的技术选项。尤其对于金融、政务、医疗等对数据安全有严苛要求的行业,能够在内部网络中完整部署这套系统,同时灵活选择推理引擎,具有重要的实践价值。
如果你对RAG技术、企业级知识库搭建或大模型应用开发感兴趣,不妨前往 云栈社区 的相关板块,与更多开发者交流实战经验和见解。
WeKnora官网 :https://weknora.weixin.qq.com
GitHub仓库 :https://github.com/Tencent/WeKnora
 发表于 2026-1-12 07:45:57
|
查看: 270|
回复: 0
发表于 2026-1-12 07:45:57
|
查看: 270|
回复: 0
