在设计和实现RAG(检索增强生成)系统时,开发者往往会同时接触到Bi-Encoder、Cross-Encoder、SPLADE和ColBERT这几种检索模型。它们表面上都在处理文本相似度计算,但为什么需要这么多种类?难道一个模型不足以应对所有场景吗?
本文将深入剖析每种模型的工作原理、适用场景及其边界,并探讨如何在实际系统中将它们组合使用。核心议题在于:我们该如何在高召回率和高精准率之间取得最佳平衡。
精准率与召回率:检索系统的基石
在深入模型之前,有必要先厘清两个基础评估指标:精准率(Precision)和召回率(Recall)。
- 精准率衡量的是模型判定为“相关”的结果中,真正相关的比例。高精准率意味着模型非常“谨慎”,只有确信无误时才做出判断,但代价是可能遗漏一些真正的正样本(假阴性)。典型应用如垃圾邮件过滤,被标记的邮件必须确为垃圾。
- 召回率衡量的是所有真正相关的样本中,被模型成功找出的比例。高召回率策略则更为“激进”,力求捕获所有正样本,宁可误报也不漏报,但会引入较多无关结果(假阳性)。
对于RAG检索而言,我们通常需要两阶段的配合:第一阶段追求高召回,尽可能广泛地召回潜在相关的文档块;第二阶段则通过重排序来提升精准率,过滤噪声并将最相关的结果排在前面。因此,单一模型很难同时优化速度和精度,多阶段、多模型协作的架构便应运而生。
Bi-Encoder:大规模语义检索的引擎
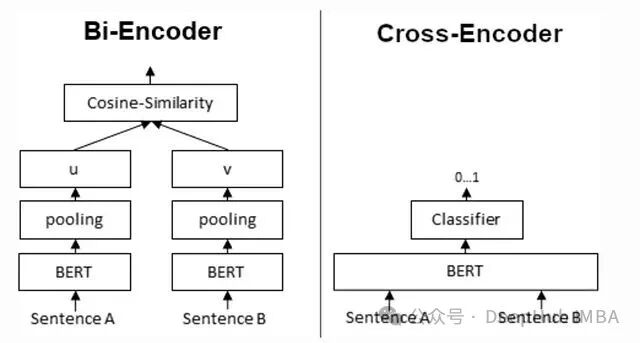
Bi-Encoder(双编码器)的核心思想非常直观:使用同一个预训练模型(如BERT)分别编码查询语句和文档,生成两个独立的稠密向量,然后计算它们之间的余弦相似度。
句子A → 编码器 → 向量A
句子B → 编码器 → 向量B
相似度 = cosine(向量A, 向量B)
虽然名为“双”编码器,但实际是共享权重的单一编码器对两段文本进行独立编码。
它的最大优势在于文档向量可以离线预计算。所有文档被编码为固定长度的向量后,可以存入如FAISS、Milvus这类向量数据库进行索引。查询时,只需实时编码一次查询语句,然后通过近似最近邻(ANN)搜索快速找到相似向量。
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
model = SentenceTransformer(“all-MiniLM-L6-v2”)
# 离线预处理文档嵌入
doc_embeddings = model.encode(documents, normalize_embeddings=True)
index = faiss.IndexFlatIP(doc_embeddings.shape[1])
index.add(doc_embeddings)
# 在线查询
query_vec = model.encode([“Only project owner can publish event”], normalize_embeddings=True)
scores, indices = index.search(query_vec, k=10)
因此,Bi-Encoder具有极强的扩展性、极快的检索速度,且嵌入可复用。但其缺点同样明显:由于查询和文档在编码时没有进行任何交互,其相关性判断是近似和独立的。对于需要复杂逻辑推理、否定表达或特定约束的查询,其表现可能会大打折扣。
Cross-Encoder:精度至上的重排序专家
当检索器为了速度从海量文档中快速召回一批候选后,其中难免混入一些不相关的结果。Cross-Encoder(交叉编码器)正是为此而生的“精排专家”。
它的工作方式与Bi-Encoder截然不同:将查询和候选文档直接拼接成一个序列,然后送入同一个Transformer模型进行联合编码,最终输出一个0到1之间的相关性分数。
[CLS] Query [SEP] Document [SEP] → 分类器 → 相关性分数 (0~1)
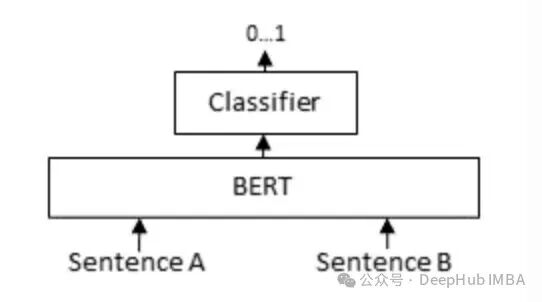
代码实现同样简洁:
from sentence_transformers import CrossEncoder
model = CrossEncoder(“cross-encoder/ms-marco-MiniLM-L-6-v2”)
# 假设已有来自Bi-Encoder的候选文档索引
pairs = [(query, documents[i]) for i in candidate_indices]
scores = model.predict(pairs)
Cross-Encoder能够进行深度的token级交互,因此通常能提供最高的相关性判断精度。然而,这种能力的代价是无法进行预计算。每次查询都必须与每个候选文档进行单独的前向传播,计算成本极高,故只适用于对少量候选集(如Top-100)进行重排序。
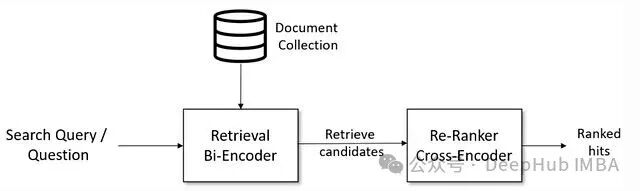
为了直观对比两者差异,可以看下面这张结构图:
一个形象的例子是:如果需要为一万个句子做聚类,使用Cross-Encoder计算所有两两相似度(约5000万对)可能需要65小时;而使用Bi-Encoder,编码所有句子只需5秒,后续的聚类操作基于向量进行,效率极高。
结论很清晰:Cross-Encoder精度更高,Bi-Encoder扩展性更好。 实践中,最佳的方案是结合使用:先用Bi-Encoder快速召回大量候选(追求高召回),再用Cross-Encoder对少量顶级候选进行精细重排序(追求高精准)。
SPLADE:可学习的稀疏检索模型
SPLADE代表了一种不同的思路:基于Transformer的稀疏检索。它不像Bi-Encoder那样输出稠密向量,而是为整个词汇表上的每个词项学习一个权重,输出一个高维稀疏向量。
你可以将它理解为一个“学会了”的BM25。传统BM25基于词频等统计特征,而SPLADE通过训练,能学习到特定词项在语义上的重要性。
它的优势在于保留了精确的词项匹配能力。对于包含特定ID、错误码、领域术语或合规性短语的查询,稀疏检索往往比纯语义的稠密检索更可靠。同时,由于权重由模型学习,它又具备了一定的语义理解能力,可解释性也优于黑盒的稠密向量。
当然,代价是索引体积会比传统的BM25更大,语义建模能力也不如纯粹的稠密模型。它非常适合那些需要同时兼顾关键词匹配和基础语义召回的场景。
ColBERT:延迟交互的折中方案
ColBERT在Bi-Encoder的“效率”和Cross-Encoder的“精度”之间找到了一个巧妙的平衡点。它不再为整个文档生成单个向量,而是为文档中的每个token都生成一个向量。
在查询时,ColBERT采用“延迟交互”机制:先分别编码查询和文档的所有token,然后通过一个高效的“MaxSim”操作计算相似度。
score(query, doc) = Σ over query tokens [ max over doc tokens ( cosine_sim(q_token, d_token) ) ]
这种细粒度的、token级别的匹配,使得ColBERT能够捕捉更丰富的语义信息,其精度显著高于Bi-Encoder,同时又比必须成对输入的Cross-Encoder更具可扩展性。它对长文档的检索尤其有效。
然而,存储每个token的向量会导致索引体积急剧膨胀,对内存和计算延迟提出了更高要求。因此,它适用于基础设施较强、且对检索精度有严苛要求的场景。
多阶段混合架构:实战中的最佳组合
在实际的工业级RAG系统中,单一模型很难满足所有需求,因此多阶段混合架构成为主流。一个典型的流程如下:
Query
│
├─ 稀疏检索(BM25 / SPLADE)→ 保障词汇召回,捕捉精确匹配
│
├─ 稠密检索(Bi-Encoder) → 保障语义召回,理解深层含义
│
├─ 合并候选集
│
├─ Cross-Encoder重排序 → 提升最终结果的精准率
│
└─ LLM生成答案
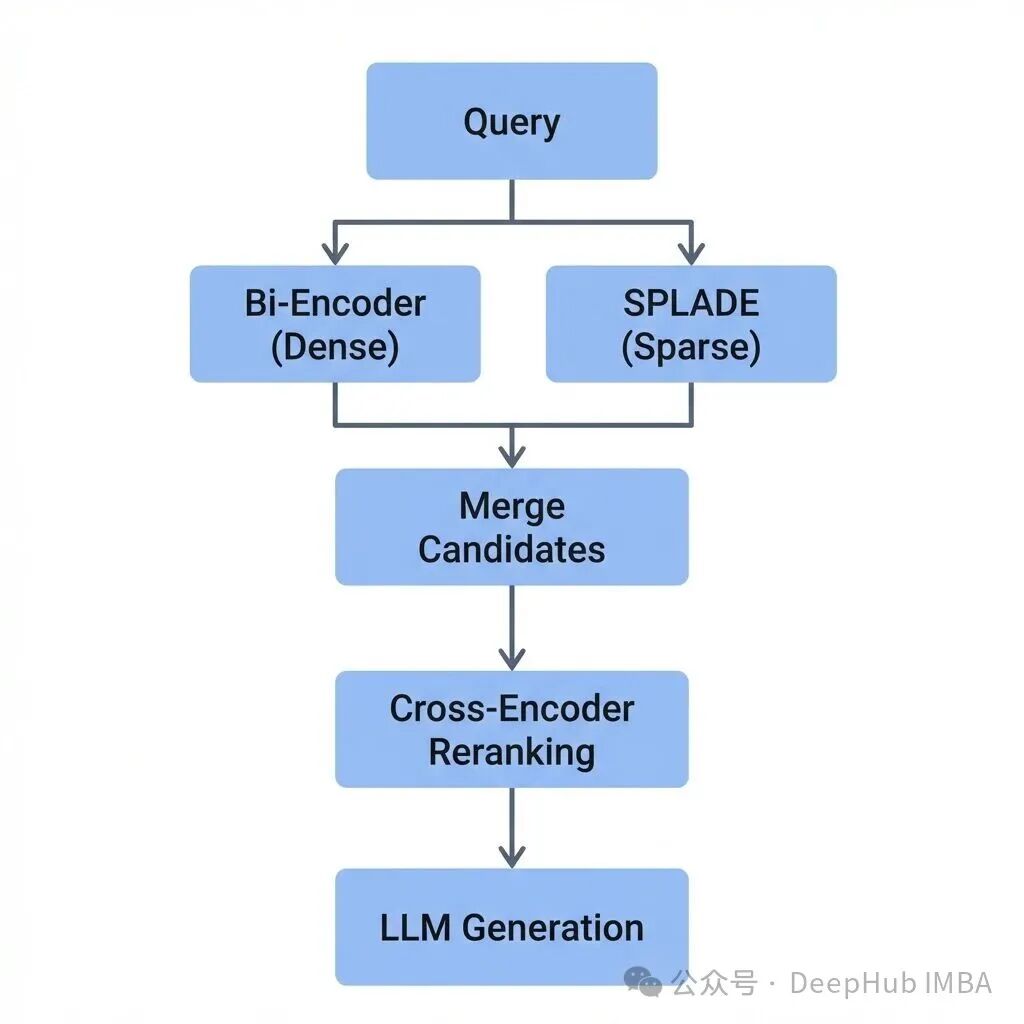
这套组合拳同时兼顾了召回率、精准率和系统扩展性。针对不同的业务场景,我们可以参考以下选型建议:
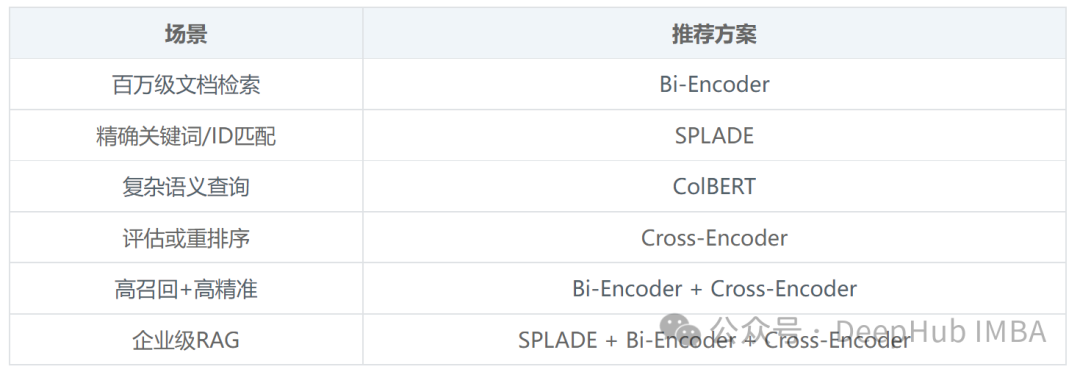
为了更直观地了解各模型特性,以下是它们的核心性能对比:
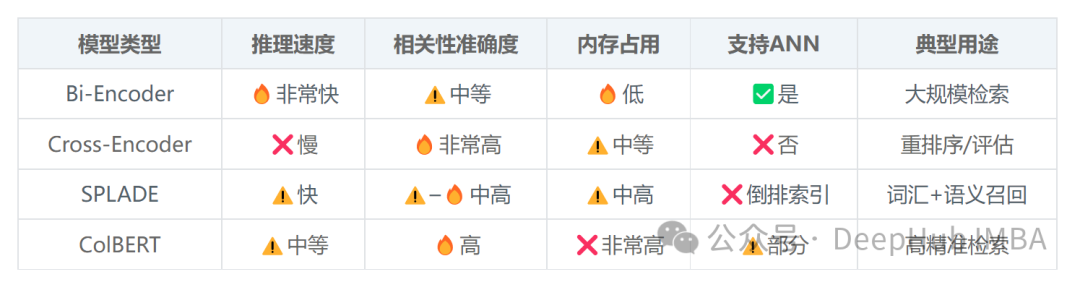
一个具体的执行流水线示例如下:
- 编码查询:使用Bi-Encoder编码一次查询(1次Transformer前向传播)。
- 向量检索:在向量数据库中执行ANN搜索,快速召回Top-10000个候选(快速向量运算)。
- 初筛:保留得分最高的Top-20个候选。
- 精排:使用Cross-Encoder对Top-20候选进行重排序(20次Transformer前向传播)。
- 输出:返回排序后的Top-3至Top-5个最佳文档块,送入LLM生成最终答案。
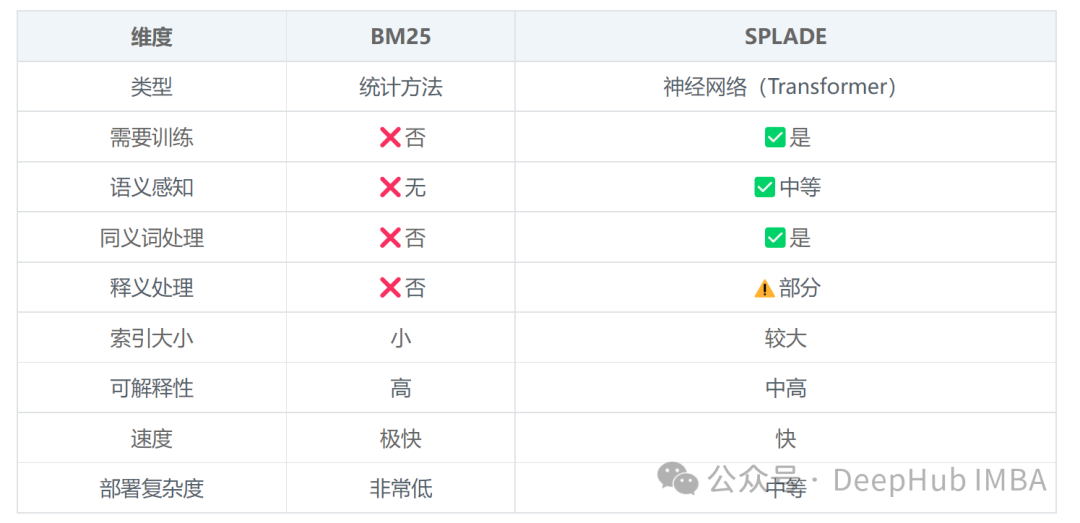
附:传统BM25与SPLADE对比
为了帮助理解SPLADE相对于传统稀疏检索方法的进步,这里提供一个简要的对比:
总而言之,在RAG系统的检索层,没有“银弹”。理解Bi-Encoder、Cross-Encoder、SPLADE和ColBERT各自的特长与短板,并根据具体场景(数据规模、精度要求、查询类型、基础设施)进行灵活选型与组合,是构建高效、可靠检索系统的关键。
希望这篇深度对比能为你提供清晰的选型思路。想与更多开发者交流人工智能与检索技术的最新实践?欢迎访问云栈社区参与讨论。
 发表于 2026-1-15 00:57:15
|
查看: 316|
回复: 0
发表于 2026-1-15 00:57:15
|
查看: 316|
回复: 0
