在Linux系统中,磁盘与主存之间的数据传输效率,直接决定了整个系统的I/O性能与整体响应速度。你可能没有意识到,当你执行一个文件读取操作时,背后正运行着一套精密的传输机制。今天,我们就来深入探讨支撑这一切的三种核心I/O传输方式:轮询(Polling)、I/O中断(Interrupt) 和 DMA传输(Direct Memory Access)。看看它们是如何一步步演进,最终让CPU得以从繁重的I/O调度中解放出来。
先搞懂核心:三种传输机制的核心差异
磁盘与主存的数据传输,本质是“把数据从磁盘搬运到内存”的过程。而不同机制的核心区别,就在于CPU在这个过程中需要介入和付出精力的程度:
- 轮询方式:这是最原始的方式。CPU会陷入一个死循环,持续不断地检测I/O端口的状态,反复询问“数据准备好了吗?”,全程无法处理其他任务。这种方式CPU利用率极低,浪费严重。
- I/O中断方式:CPU不需要再持续“盯梢”。当数据到达时,磁盘设备会主动发起一个中断信号来“叫醒”CPU,随后由CPU亲自负责数据的搬运工作。这比轮询进步,但每次传输都要打断CPU的当前工作,涉及频繁的上下文切换。
- DMA传输方式:系统引入了“专属搬运工”——DMA控制器。它直接负责在设备和内存之间搬运数据,CPU仅在传输开始前下发指令,在传输结束后处理中断即可。在此过程中,CPU可以专注执行其他计算任务,实现了计算与I/O的并行,效率得到质的提升。
过渡阶段:I/O中断机制如何工作?
在DMA技术普及之前,I/O中断是主流的传输方式。你可以将其简单理解为“磁盘喊话,CPU干活”。整个过程CPU全程参与,步骤清晰但效率仍有瓶颈。
当用户进程需要读取磁盘数据时,必须通过系统调用请求操作系统与计算机架构内核介入,这必然会涉及“用户态”和“内核态”的切换。通俗地讲,这就像普通员工(用户进程)需要仓库里的物品(磁盘数据),必须向管理层(内核)提交申请,在审批和搬运期间,员工只能等待。
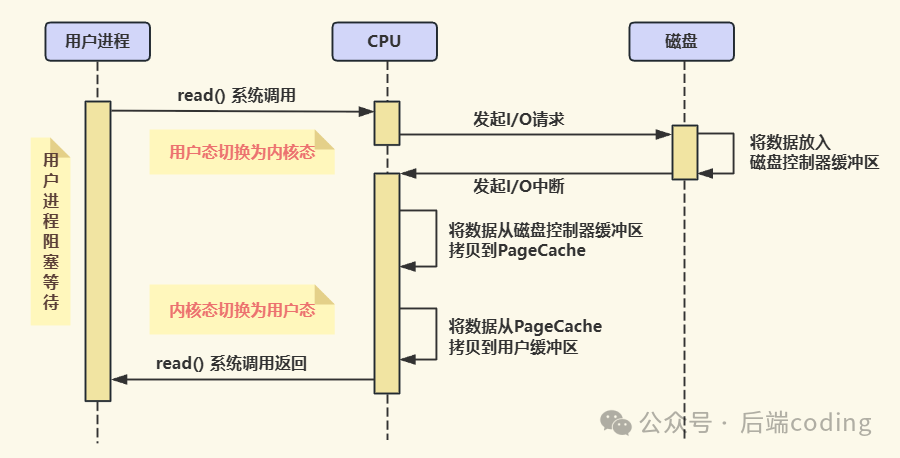
具体的流程如下:
- 用户进程发起
read() 系统调用,主动从“用户态”切换到“内核态”,随后进程进入阻塞状态,等待数据返回。
- CPU(内核)收到请求后,向磁盘发起I/O请求。磁盘开始工作,将所需数据读取到其自带的磁盘控制器缓冲区中。
- 磁盘数据准备就绪后,会向CPU发送一个“中断请求”(IRQ),相当于发出通知:“CPU,数据好了,请来处理!”
- CPU响应中断,暂停当前执行的任务,将数据从磁盘控制器缓冲区拷贝到内核空间的主存缓冲区(如PageCache),然后再从内核缓冲区拷贝到用户进程指定的用户缓冲区。
- 数据拷贝完成后,进程从“内核态”切换回“用户态”,解除阻塞状态,等待被CPU重新调度执行。
这里的关键问题在于:每次I/O操作都需要中断CPU,并且涉及两次数据拷贝(磁盘→内核→用户),同时伴随着多次耗时的上下文切换。如果系统并发大量I/O请求,CPU的宝贵时间就会被这些“搬运杂活”所占据,严重影响其处理核心计算任务的能力。
效率革命:DMA传输如何解放CPU?
为了解决I/O中断的痛点,DMA(直接内存存取)技术应运而生。其核心思路非常直观:设置一个“专职搬运工”(DMA控制器),让它来负责数据传输,CPU只负责“交代任务”和“验收成果”。
如今,绝大多数硬件设备(如磁盘控制器、网卡、声卡等)都支持DMA技术。这个“搬运工”使得数据传输可以绕过CPU的全程调度,让CPU计算与I/O操作真正实现并行,系统吞吐量因此大幅提升。
同样以用户进程读取磁盘数据为例,DMA传输的流程演变如下:
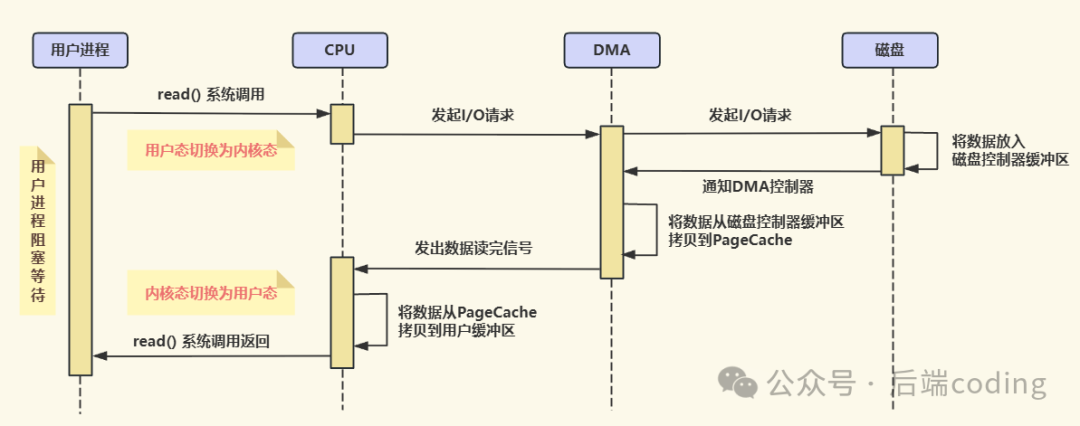
- 用户进程发起
read() 系统调用,从用户态切换到内核态,然后进入阻塞状态等待数据。这一步与I/O中断方式起始相同。
- CPU(内核)收到请求后,不再直接对接磁盘,而是向DMA控制器下发指令,包括源地址(磁盘)、目标地址(内存缓冲区)和数据长度。这相当于告诉“搬运工”:“去把这些数据从仓库搬到指定位置,搬完了通知我”。
- DMA控制器领受任务后,便替代CPU向磁盘发起I/O请求。磁盘将数据放入其控制器缓冲区。在这个过程中,CPU已被释放,可以立即返回去执行其他进程的指令,实现了计算与I/O的重叠。
- 待数据准备就绪,磁盘会通知DMA控制器。随后,DMA控制器独立地发起总线控制,将数据从磁盘控制器缓冲区直接搬运到内核的主存缓冲区(如PageCache)。整个过程无需CPU参与。
- 当DMA控制器完成整块数据的传输后,它会向CPU发送一个“传输完成”中断信号。
- CPU响应此中断,执行收尾工作:将数据从内核缓冲区拷贝到用户缓冲区(这通常很快,因为数据已在主存中)。
- 最后,用户进程从内核态切回用户态,解除阻塞。
核心总结:三种机制的演进逻辑
从轮询到I/O中断,再到DMA传输,本质上是一场持续“解放CPU”的进化史:
- 轮询:CPU全程“盯梢”,效率最低,是纯粹的忙等待。
- I/O中断:CPU“随叫随到”,摆脱了无意义的循环等待,但仍需亲力亲为进行数据搬运,频繁中断影响整体吞吐。
- DMA传输:CPU“只做指挥”,将繁琐的搬运工作委托给专用硬件控制器,实现了CPU计算与I/O操作的高效并行,是当前主流的高性能I/O基础。
理解这三种机制的演进,不仅能帮助我们洞悉Linux乃至现代操作系统的I/O底层逻辑,也能明白为何在进行大量磁盘读写时,系统的CPU占用率可能依然保持低位——这正是DMA技术在幕后默默发挥效力的结果。
当然,DMA传输虽然解放了CPU,但数据从磁盘到用户空间仍需经过两次拷贝(磁盘→内核缓冲区→用户缓冲区),这依然存在优化空间。后续的「零拷贝」技术正是为了彻底消除这些冗余拷贝,让数据传输效率再上一个台阶。如果你对Linux系统底层原理感兴趣,可以到 云栈社区 的计算机基础板块,找到更多关于操作系统、内存管理和性能优化的深度内容。 |  发表于 2026-1-15 08:42:54
|
查看: 261|
回复: 0
发表于 2026-1-15 08:42:54
|
查看: 261|
回复: 0
