分布式系统的缓存一致性一直是后台架构师必须面对的核心问题。在实际应用中,缓存与数据库不同步导致的业务异常屡见不鲜。本文将深入解析分布式环境下MySQL与Redis双写一致性的实现方案,涵盖从基础原理到企业级解决方案的完整技术路径。
数据不一致的根源分析
在典型架构中,MySQL作为持久化存储层,Redis承担缓存加速角色。数据写入时需同时更新这两个存储节点,但同步过程存在多种异常情况:
- MySQL写入成功,Redis更新失败,导致缓存中留存过期数据
- Redis更新成功,MySQL写入失败,产生数据库不存在的"脏数据"
- 高并发场景下,读写操作时序错乱引发数据不一致
这些问题的本质在于多步骤写操作无法保证原子性。
主流一致性策略深度解析
1. Cache-Aside模式(旁路缓存)
这是最常用的缓存模式,应用程序直接管理数据库和缓存交互。
读取流程:
- 优先查询Redis缓存,命中则直接返回
- 未命中时查询MySQL,将结果写入缓存后返回
写入流程:
- 更新MySQL数据库
- 删除Redis中对应的缓存键
关键设计决策:为什么选择删除而非更新缓存?
- 性能优化:避免频繁写入很少读取的数据
- 并发安全:删除操作具有幂等性,能有效避免并发写导致的数据错乱
这种"先更新数据库,再删除缓存"的策略在大多数场景下表现良好,但在极端并发情况下仍可能出现短暂不一致:
- 线程A更新数据库
- 线程B读取数据,缓存未命中,从数据库读取旧值
- 线程B将旧数据写入缓存
- 线程A删除缓存
虽然发生概率较低,但这种理论风险确实存在。
2. Write-Through/Read-Through模式
缓存层负责数据同步,对应用透明:
- 写入时缓存层同步更新数据库
- 读取时缓存自动加载数据库数据
优势: 一致性保障更好,应用逻辑简化
劣势: 写入性能受影响,需要专业缓存中间件支持
3. Write-Behind模式(异步写回)
应用写入缓存后立即返回,缓存层异步批量同步到数据库。
适用场景: 对一致性要求不高的计数类业务
风险: 缓存故障可能导致数据丢失
进阶解决方案:确保最终一致性
1. 延迟双删策略
在Cache-Aside基础上增加二次删除机制:
- 更新MySQL数据库
- 首次删除缓存
- 休眠特定时间(500ms-1s)
- 二次删除缓存
这种方法能有效清理并发操作可能引入的旧数据,但会降低写入吞吐量,且休眠时间需要根据业务特点精确设定。
2. 消息队列异步删除
通过消息队列保证删除操作的可靠性:
- 更新数据库
- 发送删除缓存消息到消息队列
- 消费者执行Redis删除操作,失败时重试
3. Binlog同步方案(推荐)
这是目前最成熟、对业务侵入性最小的解决方案,基于MySQL二进制日志实现数据同步。
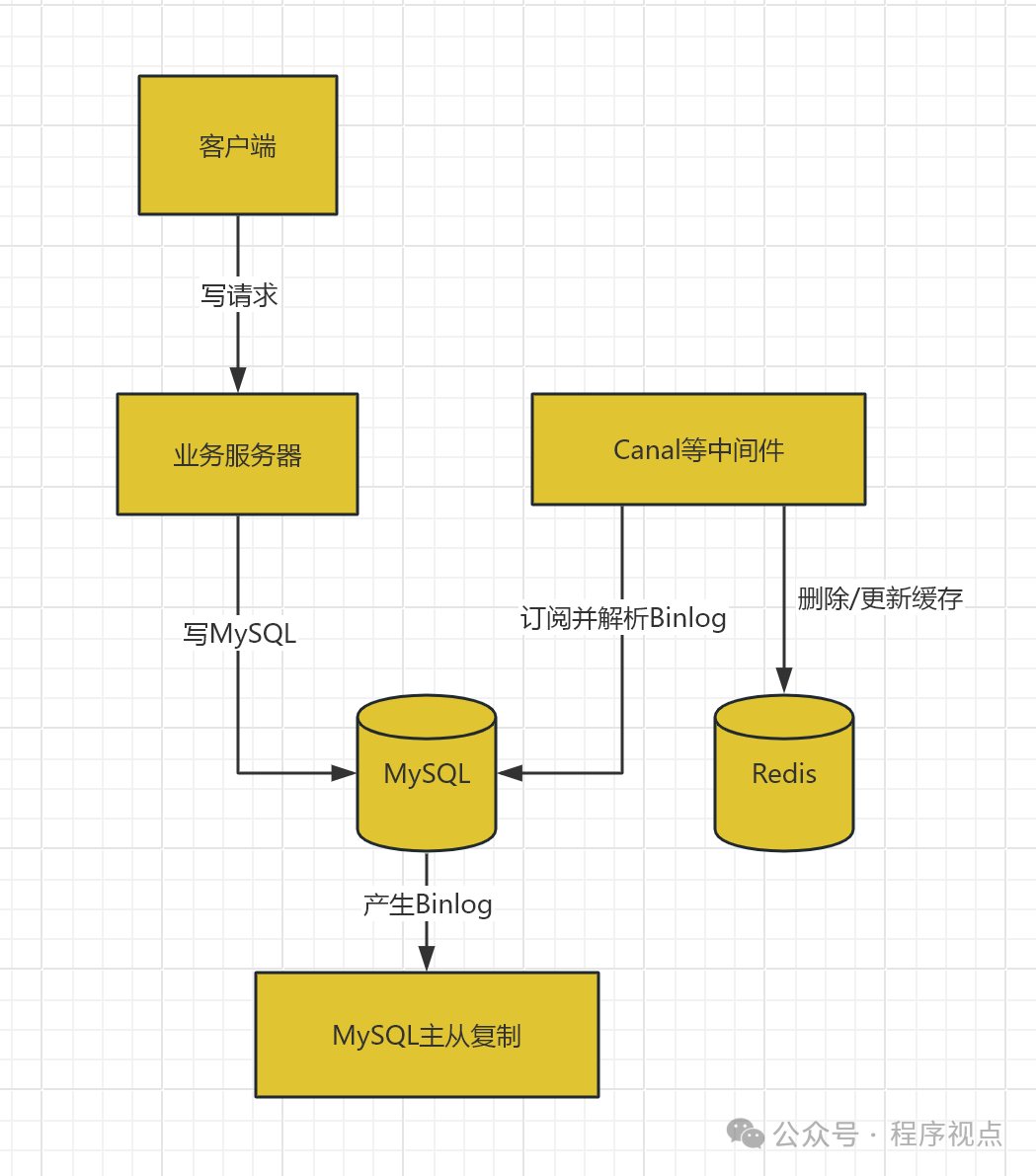
实现原理:
- 业务系统正常写入MySQL
- 中间件(Canal、Debezium)订阅Binlog
- 解析数据变更事件
- 自动同步到Redis缓存
核心优势:
- 业务代码零侵入
- 异步同步不影响主链路性能
- 基于数据库日志保证数据最终一致性
实施复杂度: 需要维护额外的同步组件,存在毫秒级同步延迟
策略选型与最佳实践
| 策略 |
一致性保障 |
性能影响 |
复杂度 |
适用场景 |
| Cache-Aside + 删除 |
最终一致性 |
高 |
低 |
读多写少常规场景 |
| 延迟双删 |
更好一致性 |
中 |
低 |
对一致性要求较高的业务 |
| Write-Through |
强一致性 |
中 |
中 |
写多读少关键业务 |
| Binlog同步 |
最终一致性 |
高 |
高 |
大型分布式系统 |
实践建议:
- 大多数场景首选Cache-Aside模式
- 严格一致性要求时引入延迟双删或消息队列方案
- 大型项目推荐采用Binlog同步架构
- 为Redis设置合理的TTL,确保旧数据自动失效
- 根据业务需求平衡一致性与性能要求
在分布式系统架构设计中,缓存一致性方案的选择需要综合考虑业务特征、性能要求和团队技术储备。通过合理的架构设计,能够在保证数据准确性的同时最大化系统性能。 |  发表于 2025-11-29 01:21:07
|
查看: 166|
回复: 0
发表于 2025-11-29 01:21:07
|
查看: 166|
回复: 0
