一个帮助个人开发者从社交媒体自动发现用户核心痛点的 Web 应用,支持智能聚类分析和 AI 产品方案生成。

功能特性
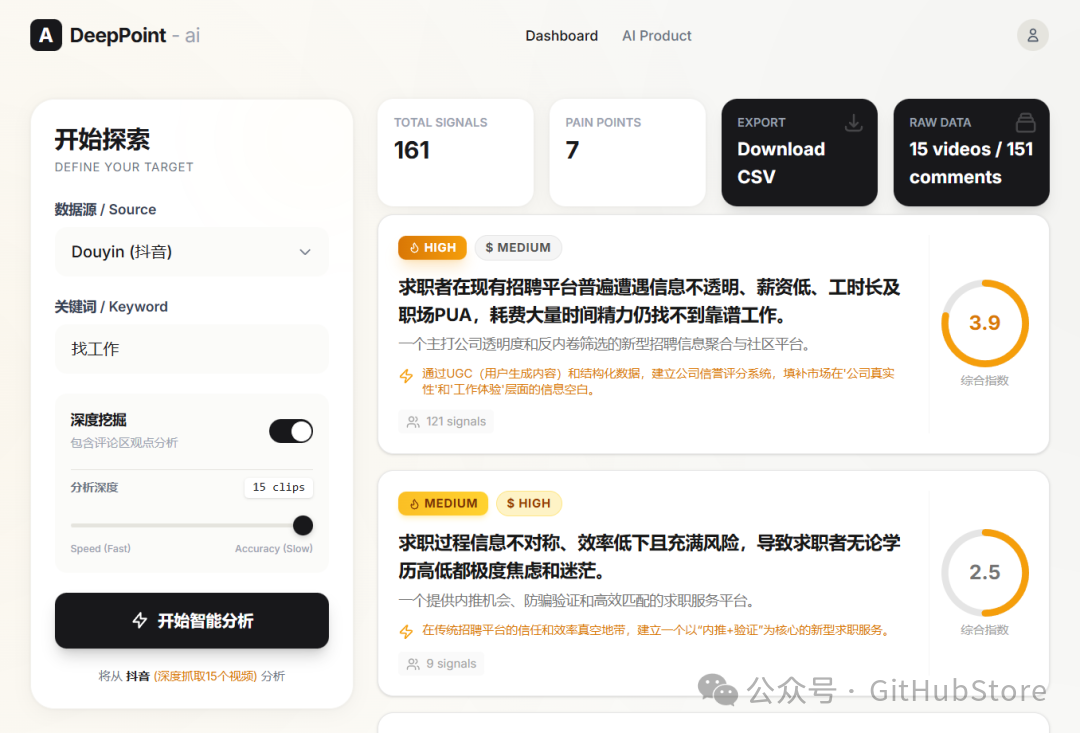
痛点分析模块
- 输入关键词自动抓取抖音相关视频和评论。
- 基于 embedding + DBSCAN 的语义聚类算法,对海量用户反馈进行智能分组。
- 调用 GLM-4.6 思考模型,对聚类结果进行深度分析与归纳。
- 深度分析维度:
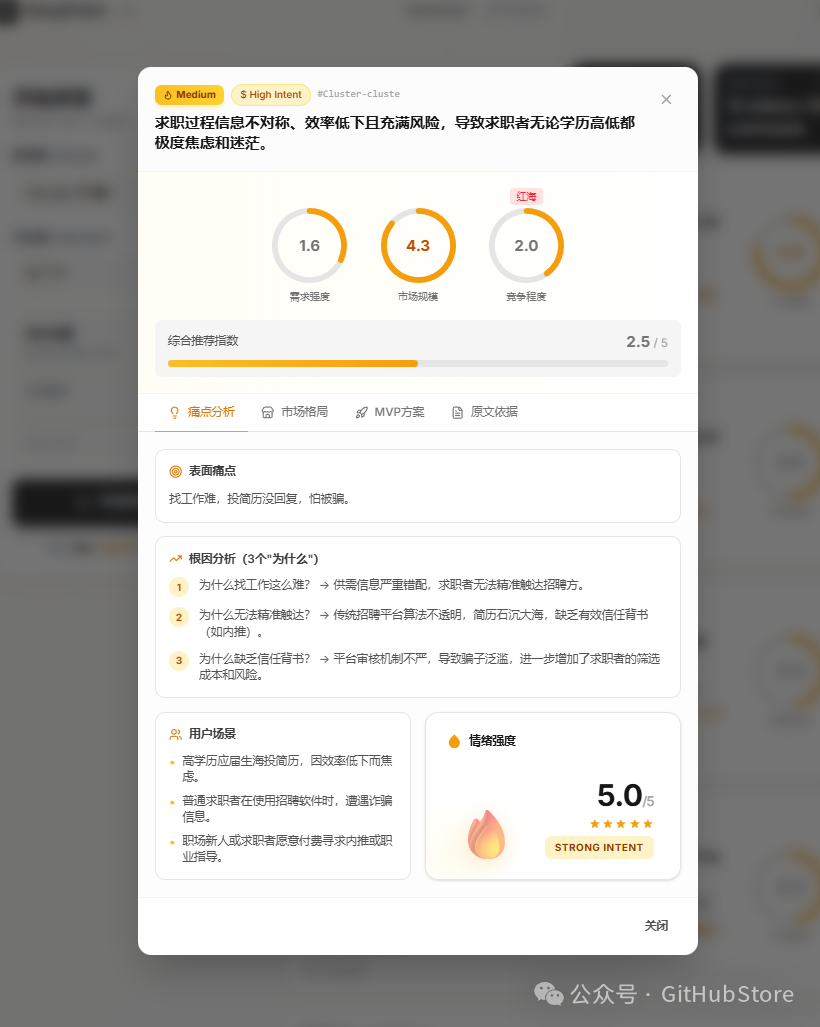
- 痛点深度:从表面痛点挖掘到根本原因,结合用户场景和情感强度。
- 市场格局:分析现有解决方案、未被满足的需求以及潜在的市场机会。
- MVP计划:生成包含核心功能、验证假设、首批用户获取及成本估算的最小可行产品路线图。
- 优先级评分系统:综合需求强度、市场规模和竞争程度,为每个痛点进行量化评估。
- 数据质量分级:根据分析样本量,将结果分为 exploratory (<50条)、preliminary (50-200条)、reliable (≥200条) 三个可信度等级。
- 以清晰的可视化表格展示分析结果。
- 支持一键导出 CSV 格式的详细报告。
- 原始数据导出:可导出爬虫获取的原始数据以及经过聚类处理的分组数据。
AI 产品建议模块
- 模拟 AI 产品经理角色,根据分析出的用户痛点自动生成完整的产品方案。
- 方案内容包括产品核心功能、推荐技术栈、分阶段开发路线图等。
- 对产品的实现难度和市场潜力进行评估,为决策提供参考。
数据源说明
| 数据源 |
状态 |
说明 |
| 抖音 - 旧版 |
可用 |
基于 DrissionPage 浏览器自动化,支持视频搜索和评论采集。 |
| 抖音 - 新版 |
可用 |
基于 Playwright + CDP,反检测能力更强,首次使用需扫码登录。 |
| 小红书 |
暂停 |
测试发现此数据源易导致账号被封,暂不建议使用。 |
运行预览
更多界面截图与资源文件,请浏览 assets 文件夹。
快速开始
环境要求
- Node.js >= 18
- Python >= 3.10
- npm 或 pnpm
- Google Chrome
1. 安装依赖
# 克隆项目
git clone https://github.com/your-username/deeppoint-ai.git
cd deeppoint-ai
# 安装 Node.js 依赖
npm install
# 安装 Python 依赖
pip install -r requirements.txt
# 如果使用新版抖音数据源,还需安装浏览器
playwright install chromium
# 或手动安装核心依赖
pip install DrissionPage beautifulsoup4 lxml scikit-learn numpy python-dotenv
2. 配置环境变量
cp .env.example .env.local
编辑 .env.local 文件:
# 智谱AI GLM API配置 (必需)
# 注册地址: https://open.bigmodel.cn/
GLM_API_KEY=your_glm_api_key_here
GLM_MODEL_NAME=glm-4.6
GLM_EMBEDDING_MODEL=embedding-3
# 浏览器配置 (服务器环境设为 true)
HEADLESS=false
3. 运行项目
# 开发模式
npm run dev
# 生产构建
npm run build
npm run start
访问 http://localhost:3000 即可开始使用。
使用指南
痛点分析(主页)
- 选择数据源(推荐使用新版抖音)。
- 输入关键词,多个用逗号分隔,例如:
露营, 新手, 装备。
- 可选开启“包含评论区观点分析”(更耗时但数据更丰富)。
- 点击“开始智能分析”,耐心等待结果。
- 在结果表格中,点击任意行可查看详细分析原文,或点击导出按钮下载 CSV 报告。
新版抖音说明:首次使用时系统会弹出一个浏览器窗口,需要你扫码登录抖音。登录状态会自动保存,后续分析无需重复登录。
AI 产品建议(/ai-product 页面)
- 输入你感兴趣的目标领域关键词。
- AI 将自动分析该领域的用户反馈,并生成一份完整的产品方案。
- 查看方案详情,包括产品名称、核心功能、技术栈建议、开发计划等。
技术栈
| 类别 |
技术 |
| 前端框架 |
Next.js 15 + React 19 |
| 样式 |
Tailwind CSS 4 |
| 数据请求 |
SWR(用于轮询任务状态) |
| 后端 |
Next.js API Routes |
| 数据采集 |
Python + DrissionPage / Playwright |
| AI 分析 |
智谱 GLM-4.6(思考模型) + embedding-3 |
| 聚类算法 |
基于 embedding + DBSCAN 的语义聚类 |
API 配置
智谱 AI (必需)
- 注册账号:https://open.bigmodel.cn/
- 在控制台创建 API Key。
- 将获取到的 Key 配置到
GLM_API_KEY 环境变量中。
常见问题
Q: 抖音数据采集很慢?
A: 这是正常现象。工具使用浏览器自动化模拟真实用户操作以避免被封,速度相对较慢。“深度抓取”模式会采集更多数据,因此耗时也更长。
Q: 如何在服务器部署?
A: 在服务器环境变量中设置 HEADLESS=true 以启用无头浏览器模式。
Q: 聚类结果太少?
A: 可以尝试输入更多或更相关的关键词来扩大数据样本。此外,你也可以调整 clustering-service.ts 文件中的 minClusterSize(最小聚类尺寸)参数来获得不同粒度的聚类结果。
Q: 小红书数据源能用吗?
A: 目前暂不建议使用。在测试阶段发现,使用该数据源进行采集有较高的账号被封禁风险。
项目地址
该项目的完整源码和最新文档可以在 GitHub 上找到:https://github.com/weiyf2/deeppoint-ai
如果你对使用 AI 进行用户研究或构建类似的 Next.js 全栈应用感兴趣,欢迎在云栈社区 与更多开发者交流心得。 |  发表于 2026-1-15 12:28:49
|
查看: 257|
回复: 0
发表于 2026-1-15 12:28:49
|
查看: 257|
回复: 0
