先说背景,我目前在腾讯IMWeb团队,负责在线教育平台腾讯课堂的前端研发。
都说疫情期间在线教育是风口,但我想说,扛得住也许是机遇,扛不住就完全是炮灰。这不仅仅是业务增长的问题,更是一场对技术架构、团队协作和个人能力的极限压力测试。
1. 流量冲击下的六大前端考验
从春节假期到现在,我们遭遇了前所未有的流量峰值。虽然具体数字不便透露,但可以想象,全国那么多所学校在此期间强制网络上课,学生和老师的访问量是多么庞大。
如果说双十一是所有具有消费能力和冲动的人群的集中冲击,那么这一次则是所有学生和老师的强制访问。访问者几乎没有选择权,这是最可怕的一点。比双十一更可怕的是,我们没有时间准备。双十一可以提前数月甚至半年开始谋划,而这次的流量完全是毫无预兆的突发性事件,要求我们在极短时间内必须做出快速决策和响应。

截止目前,流量高峰已经冲击了三波,每一次都是数倍的增长。如今流量逐渐平稳,也让我能够稍作喘息。
1.1 考验一:HTML主域稳定性
对于前端而言,最大的影响莫过于承载 HTML 入口的主域。一旦主域扛不住,网页都打不开,整个系统就瘫痪了。
在我们团队,主域的 Nginx 配置主要由前端负责管理。在腾讯的运维体系下,STGW(安全流量网关)之下的层面通常交由业务团队自行维护。因此,从某种程度上说,我们扮演了真正的 DevOps 角色。运维同学与我们的协作,可能更多地集中在机器申领与容量规划上。
除了承载核心的 HTML 入口,主域还承接了 CDN 的降级策略。这是为了防止因某处运营商问题直接导致 CDN 无响应,之前的教训让我们做了这层容灾。因此,主域的稳定性至关重要。
所幸这里主要进行静态资源服务和简单的页面渲染,扛住高并发相对可控。不过,这无疑对前端的 Nginx 配置和管理能力提出了更高要求,任何改动都必须经过严格的流程把控和充分验证。
1.2 考验二:音视频直播链路
音视频链路对于在线课堂而言是重中之重。 老师和学生的核心目的就是通过直播来上课,一旦音视频服务出现故障,腾讯课堂的所有其他功能都将形同虚设。这是前端面临的第二项重大考验。
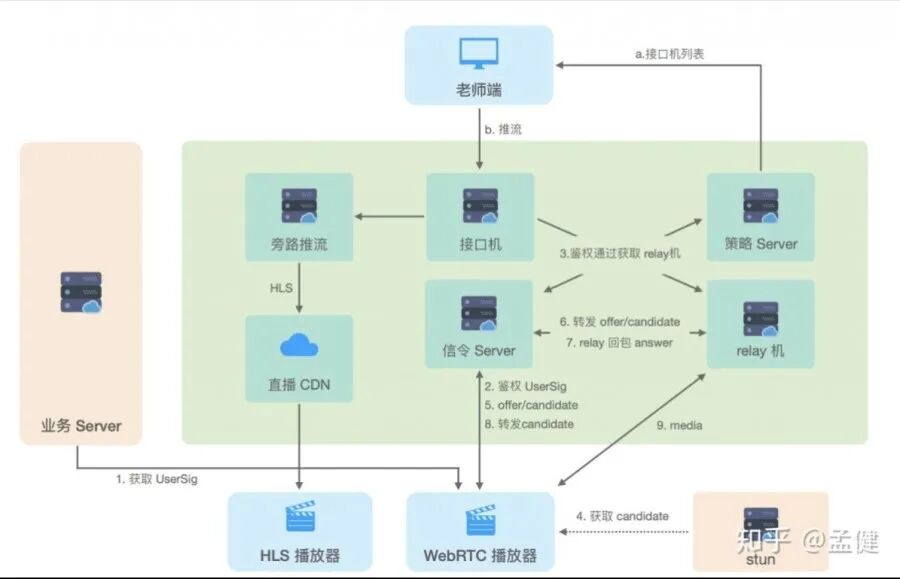
课堂前端团队在音视频领域做了大量优化。疫情期间,音视频作为核心模块被重点关注,我们快速上线了快直播、简化 WebRTC 信令、分摊更大流量、HLS 降级 WebRTC、混流开关等一系列措施。
实际上,音视频团队所做的工作远远不止于此。我们组负责音视频的同事已经不知道通宵了多少个夜晚,十分辛苦。
1.3 考验三:SAS 数据管理配置平台

这个平台(IMWeb Schema as Service)承接了所有运营、类目和产品配置。它对接 CKV 与 CDB 平台进行数据存储,对接云 COS 进行文件存储,并通过 JSON Schema 配置出数据服务,同时同步 ZK 节点供后台服务查询。
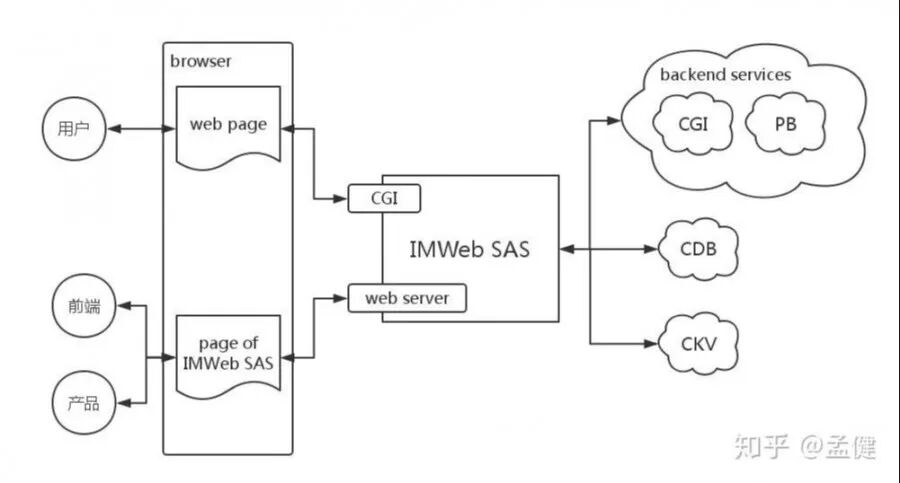
目前,成百上千张业务数据表都托管在这个平台上。一旦它挂了,后果不堪设想。该平台整体运用了 GraphQL 技术作为访问查询层,属于前端团队需要保障的第二大核心系统。
得益于 SAS 平台最初设计的简洁性和高内聚性,其监控非常完善,扩容也较为容易,因此较为平稳地挺过了流量高峰。
1.4 考验四:IMPush 消息通道
IMPush 是前端团队自研的消息推送通道,承接了所有 Socket 消息的实时转发。这个系统承载了聊天区所有的消息服务,与客户端保持全双工长连接,并利用 Redis 进行数据缓存。整个系统的 agent(代理)与 center(中心)节点都面临着巨大的压力挑战。
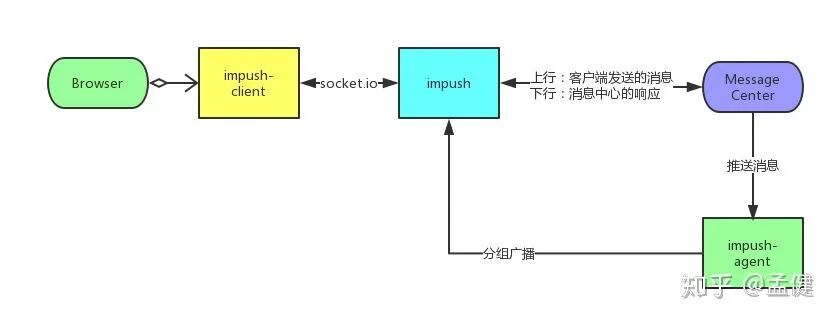
这个服务如果出现故障,所有的聊天区、弹幕等功能都将瘫痪,影响面非常大。我们同样借助现有的负载均衡 L5 体系和充足的资源储备,来抗住巨大的并发连接量。
1.5 考验五:监控、日志与灰度发布
我习惯将监控、日志和灰度发布称为前端稳定性的“三板斧”,这也是衡量一个前端团队是否专业的重要指标。很多团队可能只关注脚本错误监控,而忽略了最基本的测速、返回码等监控。
单论前端脚本错误监控,我们就准备了三套降级方案:BadJS + Sentry + 全链路日志。在超高访问量下,可以预见任何单一监控平台都可能出现瓶颈或故障。三套系统互为备份,确保了即使在外网出现问题时,我们也能第一时间定位问题根源,快速响应。
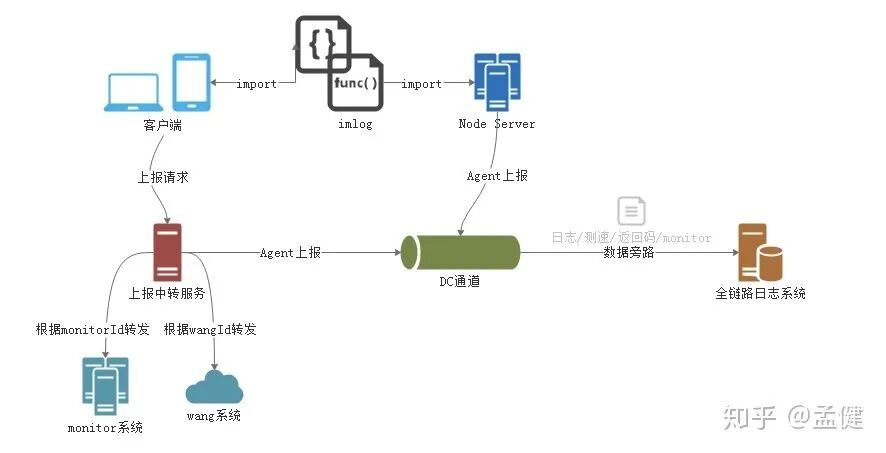
日志上报是前端最容易忽略的环节。当用户量达到一定规模,你会发现很多问题并没有伴随脚本报错。如果只依赖错误监控,很多线上问题会让人“两眼一抹黑”,无从下手。因此,专业的团队需要全链路的日志追踪能力。

前端团队在这里借用了开源的 ELK Stack(Elasticsearch, Logstash, Kibana)方案,与后台的全链路系统打通。在基础上通过 DC 通道上报日志,由 Agent 代理分发至不同监控系统,做成了统一的上报中台,最终在 Kibana 系统上进行统一的查询和定制化报表分析。想要了解更多关于日志和监控的最佳实践,可以参考 云栈社区 上运维和DevOps相关的讨论。
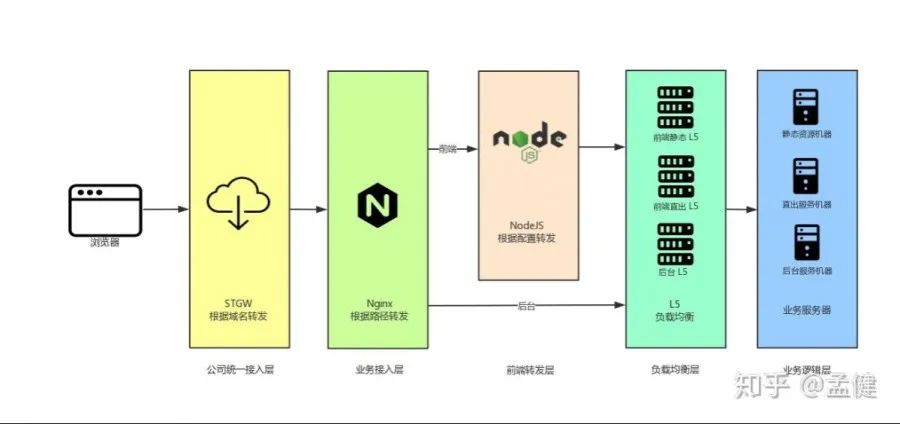
灰度发布方案的实施相对复杂。最简单的按机器灰度在实际业务中基本不可用,因为如果需求同时修改了新旧页面,会导致用户访问不一致甚至出现 404。更好的方式是按照登录态进行灰度,这就需要统一的接入层,Nginx、TSW 等都是可选的方案,对白名单内的用户开启新功能。
但对于 CDN 上的静态资源,我们无法架设统一的 Node 服务来接入。这时就需要考虑离线方案,例如制作离线包以及 PWA 管理平台,利用离线包的版本来进行登录态灰度,与 Node 服务的灰度策略保持一致。
有了监控、日志和灰度这“三板斧”的保障,我们才能做到心中有数,让数据指导我们的行动,从而稳健地扛住高并发流量。
1.6 考验六:为后台系统提供“柔性保护”
在这场战役中,前端不能独善其身。我们不仅要做好自己的分内事,更要主动帮助后台团队共渡难关。
首先,在核心场景下,按需屏蔽非关键的接口调用,帮助后台减轻压力。这可以根据后台服务的实时负载情况动态调整。

其次,前端自身要保持足够的“柔性”。除了核心 CGI 接口外,其他接口无论是超时还是返回错误,都不应影响页面核心功能的正常运行。这对前端的代码健壮性和异常处理机制提出了很高的要求。所幸团队平时的 Code Review 习惯良好,对接口的异常处理也相对完善,只是模拟各种接口异常状态进行测试验证花费了一些时间。
2. 海量业务需求下的效率突围
你以为应对流量冲击就是全部了?远远不止!上述工作往往是在挤出的时间内完成的调整,真正的重头戏还在于那极度紧张、源源不断的业务需求本身。
腾讯课堂之前的 toB 部分主要面向开课机构和个人老师,而疫情期间紧急接入了学校教务、老师、领导乃至教育局。老板们直接重点关注,可想而知产品、开发和测试的压力有多大。
我们在两天内就紧急推出了“腾讯课堂极速版”(https://ke.qq.com/s),支持老师 10 秒快速开课。目前该版本已经快速迭代到了第 4 版。
众所周知,对于一个成熟的系统,由简入繁易,由繁入简难。腾讯课堂本身有一套复杂的 B 侧(机构端)管理体系,而极速版要化繁为简,让老师和学生都能极速开课、上课,其难度可想而知。课堂团队能在如此短的时间内完成极速版的开发和发布,体现了极强的开发战斗力与协作效率。

在此期间,开发承接的工作量大约是平时的五倍左右。不仅需要通宵达旦,更需要快速响应。课堂前端每日平均发布版本超过 10 次。如何在高频次的发布中保证质量,同样是巨大的考验。
要保持高强度的战斗力,离不开团队扎实的基础设施和效率工具建设。
2.1 效率工具:Nohost 多环境并行开发方案
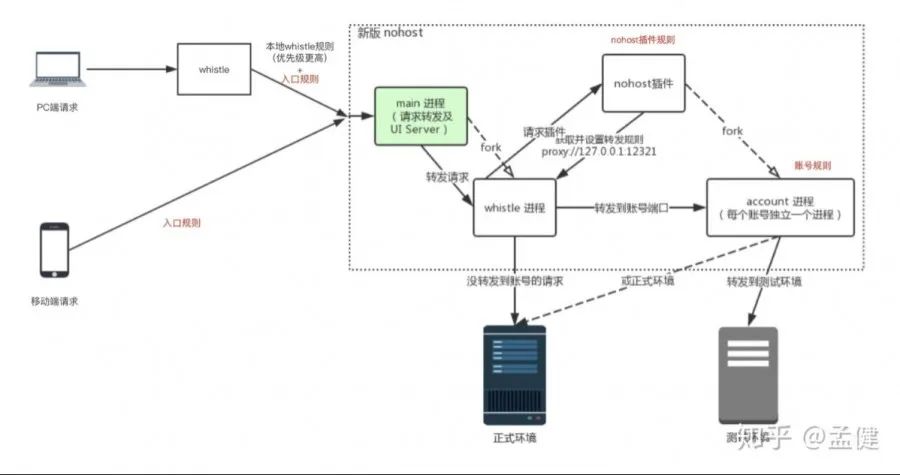
Nohost 方案为测试环境的多需求并行开发提供了强大支持。它不仅支持前端代码的分发,还利用 Docker 打通了后台环境。
开发人员可以便捷地使用分支进行独立部署,产品经理在家就能切换不同的需求环境进行体验,测试同学也能远程访问特定环境进行测试,大大提升了疫情期间的远程协作效率。
2.2 效率工具:Tolstoy 接口管理方案
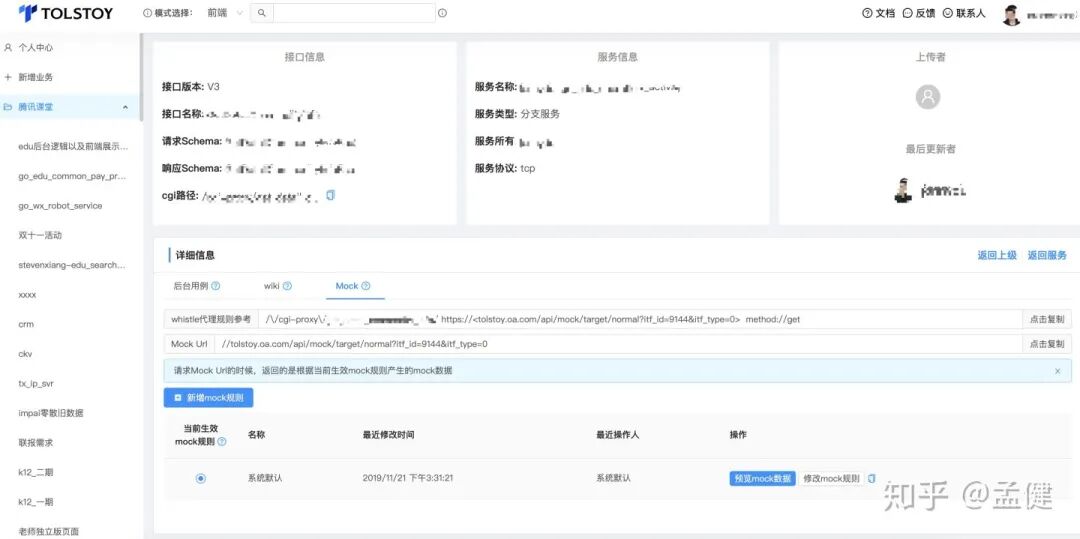
Tolstoy 方案打通了后台的 PB、CGI 等协议定义。它能让后台定义的接口协议自动生成 API 文档、Mock 数据、TypeScript 声明文件、测试用例等等。尤其是 TypeScript 类型文件的自动生成,为前端开发提供了极大的便利,让我们的 TypeScript 项目开发得更快、更稳健。对于如何在前端工程中更好地集成 TypeScript 和现代构建工具,前端框架与工程化板块有许多深入的探讨。
2.3 效率工具:Thanos 发布流程治理方案
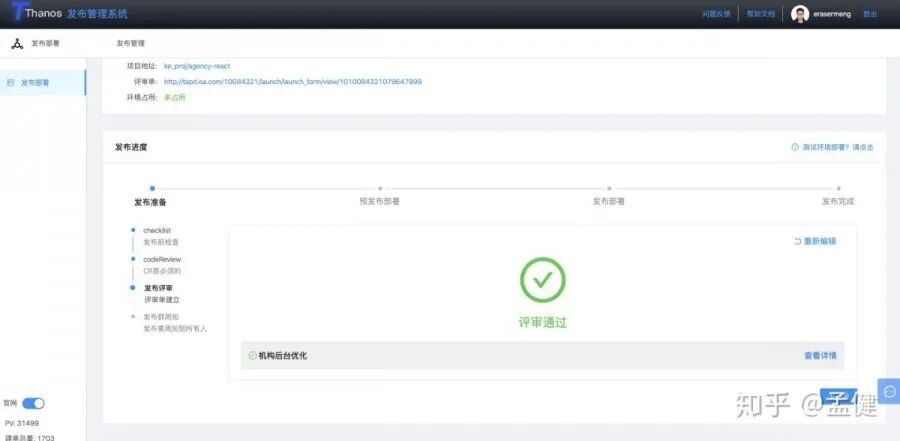
Thanos 方案是我核心主导的项目,它解决的是复杂发布链路的管理问题。对于大型公司而言,发布除了 CI/CD 流水线,往往还涉及评审、清单检查、多环境部署、灰度观察等一系列额外流程,需要形成一个完整的发布闭环。
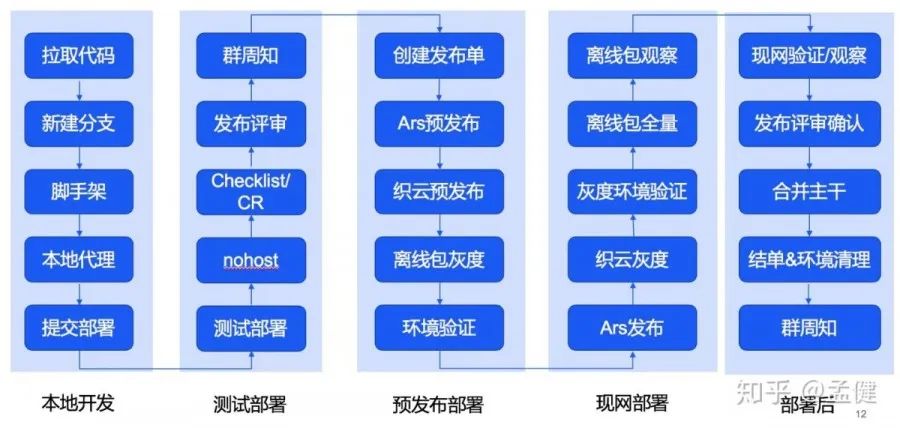
如果没有一个系统来承载和串联这些流程,这些杂乱无章的步骤很可能成为发布事故的根源。

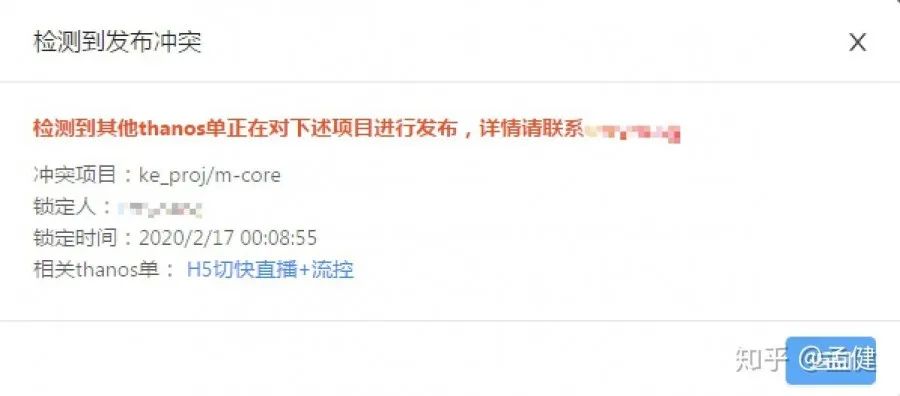
另一方面,采用分支发布策略(而非主干发布)好处很多,但也带来了普遍性的挑战,例如分支准入管控和发布冲突(覆盖)问题。这两个关键问题在 Thanos 方案中得到了系统化的保障。
2.4 个人与团队的快速适应能力
在高需求量、紧 deadline 的情况下,对每个人的技术能力和学习速度要求极高。腾讯课堂前端业务的复杂度还体现在“端”的多样性上:老师端、学生端、机构端、App 端、PC 端、小程序、微信公众号、QQ 公众号、题库、直播间等等,项目繁多,技术栈各异。
许多历史项目包含了多样化的技术栈,从古老的 FIS、QQ 客户端内嵌页、jQuery,到现代的 React、TypeScript、RN、音视频等。切换一个项目,有时感觉像换了一家公司,需要快速适应全新的技术栈。
在人力紧张的情况下,每个人都可能被派去应对自己不熟悉的领域。可能还没搞清楚什么是 HLS 就被拉去做音视频优化,或者完全没接触过 FIS 却需要去熟悉整个旧项目的构建打包流程。这对于个人的快速学习、上手能力和编码质量都提出了极高要求。
另一方面,文档在这一刻发挥了不可替代的价值。许多团队不注重文档建设,觉得费时费力且对个人成长帮助不大。但实际上,完善的文档是巨大的“互利”资产。团队的文档完善程度,往往能从侧面反映出其技术管理水平和技术沉淀意识。
3. 付出之后的微小回报
在所有人的共同努力下,腾讯课堂获得了更高的社会曝光度和认可度,这算是对我们辛勤付出的最好肯定。
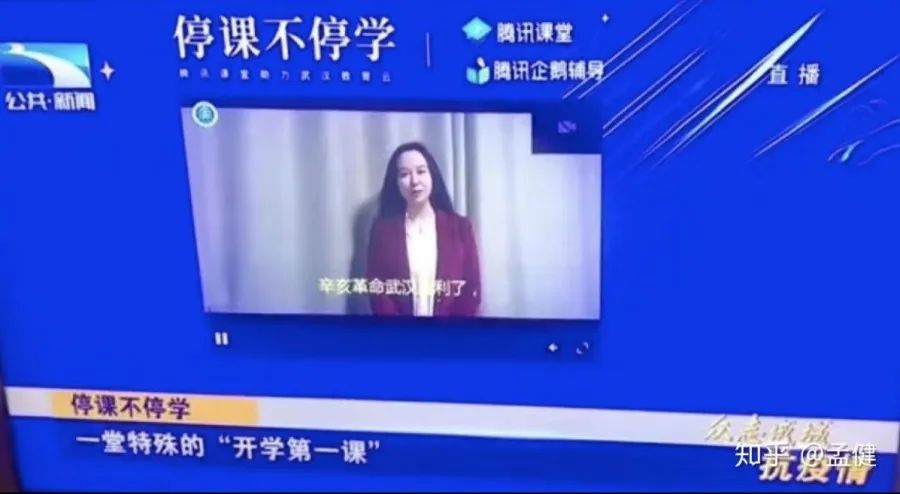
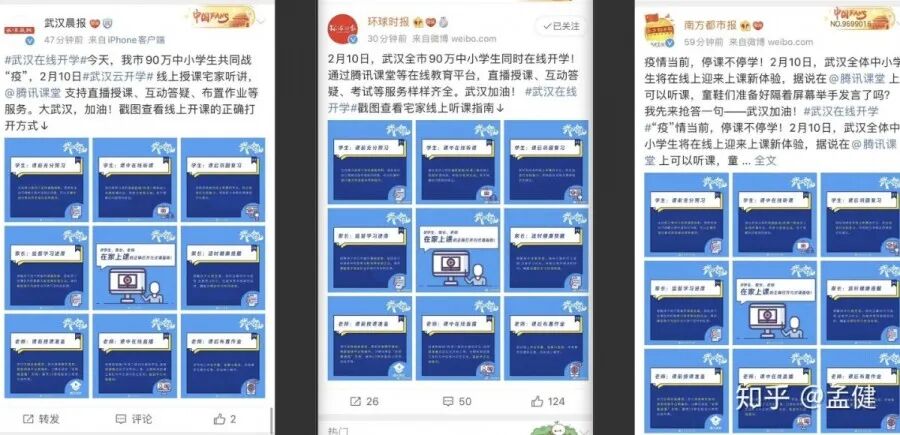
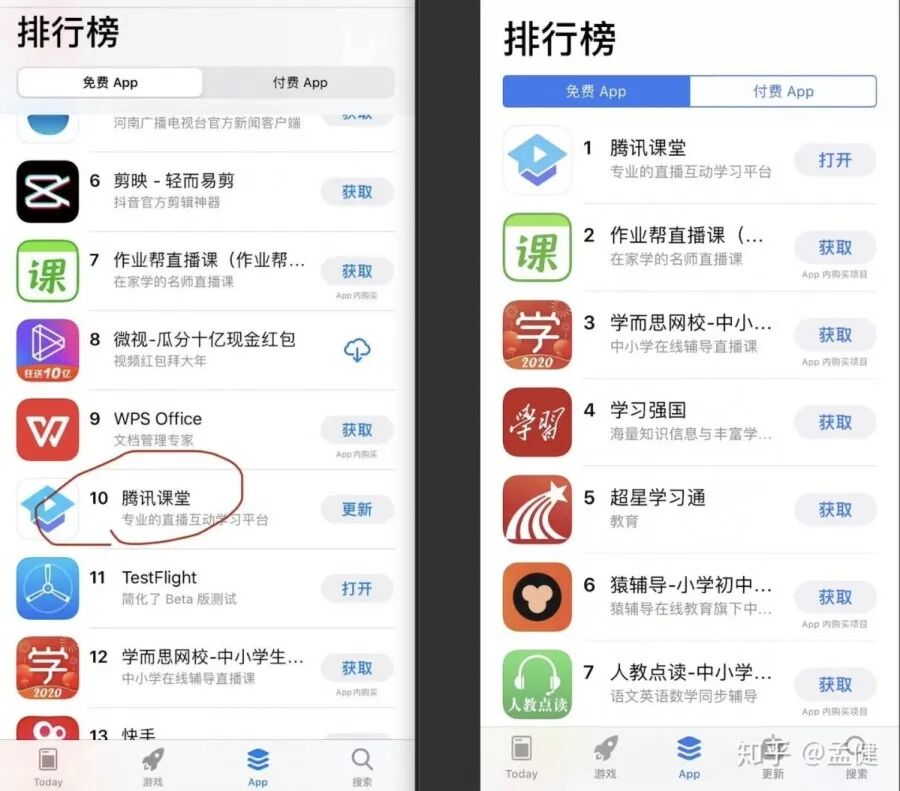
最后,回归正题。前端的复杂度体现在方方面面,可能是排查一个由冷门正则表达式引发的 CPU 负载过高问题,也可能是应对突如其来的流量洪峰和业务压力。今天我提到的“复杂度”更偏向于后者,它比较普适,任何有一定规模的团队都可能面临类似的场景挑战。对于每个身临其境的团队而言,应对起来绝不会轻松。这更多需要公司资源的有效调度、团队长期的技术积累与个人过硬能力的默契配合。
成长最高效的方式,不是一个人单枪匹马地孤军奋斗,而是和大家并肩作战,享受解决难题后的技术狂欢。
真正复杂的系统级需求,个人的力量是有限的。如何协调、激发并整合整个团队的力量,往往是更艰难的课题。 当团队在技术视野和基础建设上有前瞻性和深厚沉淀时,个人就不仅仅是埋头写业务。团队会在后方推着个人前进,在这种高手云集的环境中保持核心竞争力并持续成长,才是个人发展最理想的方向。
本文原载于知乎,经编辑优化。更多关于高并发架构、前端工程化及 DevOps 的实战讨论,欢迎访问 云栈社区 进行交流。
 发表于 2026-1-16 01:02:05
|
查看: 304|
回复: 0
发表于 2026-1-16 01:02:05
|
查看: 304|
回复: 0
