你有没有过这样的经历:明明是千兆网卡,传个几G的文件却慢吞吞;服务器并发量一上来,文件下载就频繁卡顿。其实,这背后藏着计算机I/O传输的核心痛点——磁盘,作为系统里出了名的“慢硬件”,读写速度比内存差10倍以上。
为了解决这个问题,工程师们发明了各种优化技术:零拷贝、直接I/O、异步I/O等等。今天,我们就以“文件传输”为切入点,从根源讲清I/O工作的底层逻辑,以及零拷贝技术是如何让传输性能实现质的飞跃的。
CPU累到罢工?DMA技术的“救场”之路
要理解零拷贝,首先得搞懂一个关键技术——DMA。在没有DMA的年代,计算机处理I/O传输简直是“浪费人才”。
比如应用程序要从磁盘读数据,整个过程是这样的:
- 应用程序发起读请求,CPU暂停当前工作;
- CPU亲自把数据从磁盘控制器缓冲区搬到内核空间缓冲区;
- 再把数据从内核空间缓冲区搬到用户空间缓冲区;
- 数据传输完成后,CPU才能回到之前的工作。
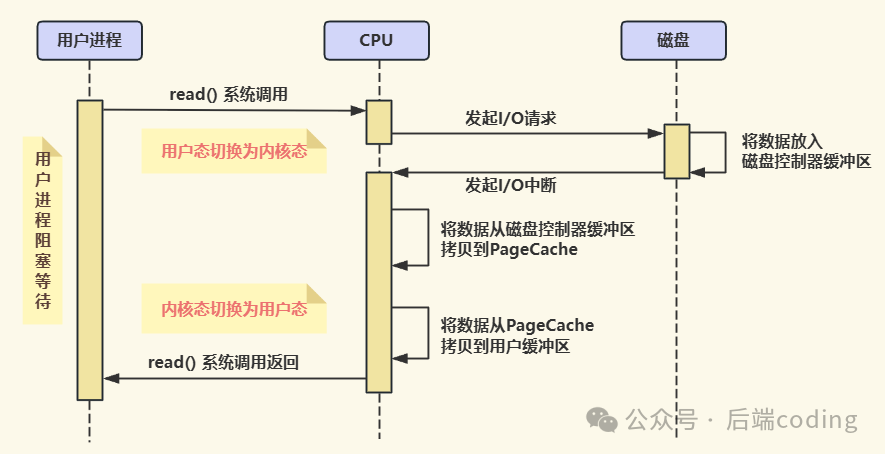
简单说,CPU在这个过程中就是个“专职搬运工”,期间啥也干不了。如果只是传几个小文件还好,要是用千兆网卡或硬盘传输大量数据,CPU直接忙不过来,整个系统都会陷入卡顿。
工程师们发现这个问题后,DMA技术(直接内存访问)应运而生。它的核心逻辑很简单:数据搬运的活儿交给专门的DMA控制器,CPU只负责“发指令”,不用亲自参与搬运。
有了DMA之后,I/O传输流程变成了这样:
- 应用程序发起请求,CPU告诉DMA控制器:“把XX磁盘的XX数据,传到内存的XX地址”;
- CPU转身去处理其他任务;
- DMA控制器自行完成数据从磁盘到内核空间的搬运;
- 搬运完成后,DMA向CPU发中断信号,CPU再做后续处理。
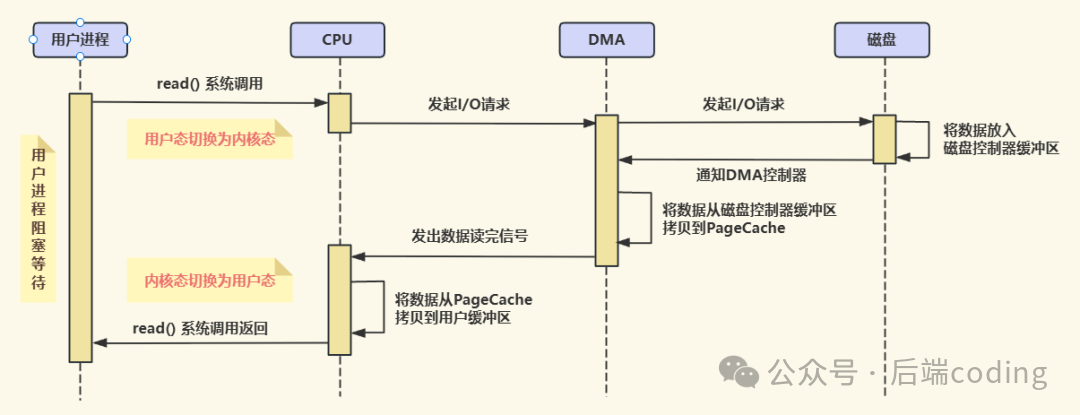
这里要注意:早期DMA只在主板上有,现在因为I/O设备越来越多(网卡、硬盘、U盘等),每个设备都自带了DMA控制器,分工更明确。
传统文件传输:两行代码背后的“4次切换+4次拷贝”
了解了DMA,我们再看最基础的文件传输方式。如果服务端要提供文件下载功能,最直观的代码就两行:
read(file, tmp_buf, len); // 从磁盘读数据到临时缓冲区
write(socket, tmp_buf, len); // 从缓冲区把数据发往客户端
看似简单的两行代码,背后却藏着大量冗余开销,核心问题出在“上下文切换”和“数据拷贝”上。
先解释两个关键概念:
- 用户态与内核态:用户态是应用程序运行的空间(比如我们写的业务代码),内核态是操作系统核心功能运行的空间(比如操作磁盘、网卡)。从用户态切换到内核态,需要经过权限校验、保存上下文等流程,耗时不短。
- 数据拷贝:数据在不同缓冲区之间的搬运,要么靠CPU,要么靠DMA,其中CPU拷贝的开销远大于DMA。
传统文件传输的完整流程(结合图片理解更清晰):
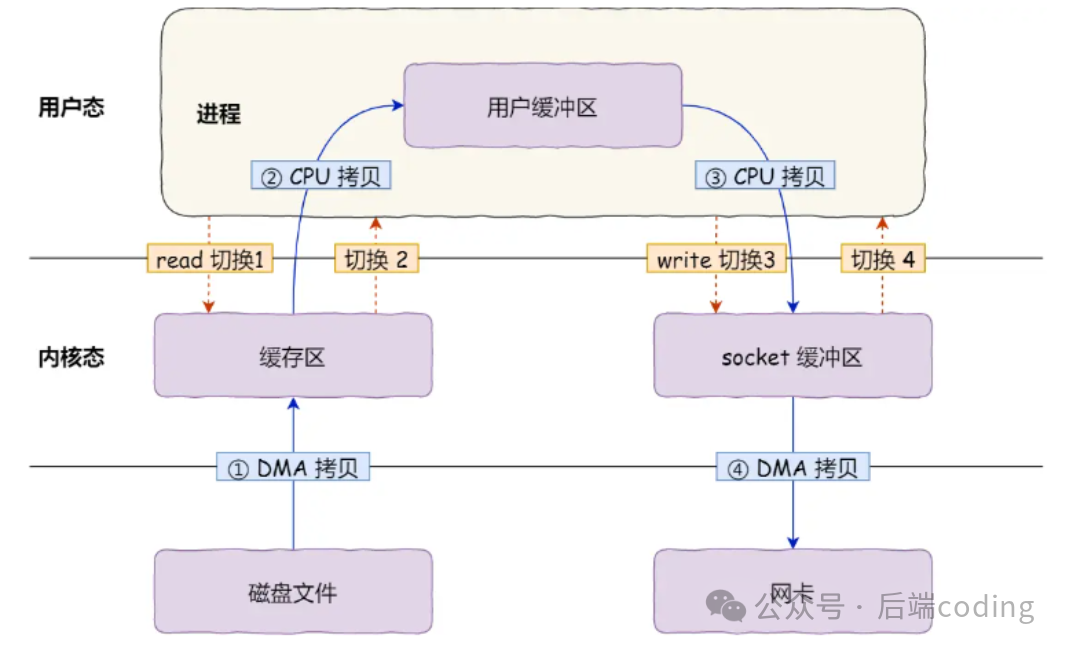
- 执行
read():用户态→内核态(1次切换),DMA把磁盘数据拷贝到内核缓冲区(1次DMA拷贝),CPU再把内核缓冲区数据拷贝到用户缓冲区(1次CPU拷贝),然后内核态→用户态(2次切换);
- 执行
write():用户态→内核态(3次切换),CPU把用户缓冲区数据拷贝到socket缓冲区(2次CPU拷贝),DMA把socket缓冲区数据拷贝到网卡(2次DMA拷贝),然后内核态→用户态(4次切换)。
总结一下:4次上下文切换 + 4次数据拷贝。明明只是传一份数据,却要反复搬运,CPU资源被大量浪费。在高并发场景下,这些冗余开销会被无限放大,直接导致系统性能崩溃。
所以,优化文件传输性能的核心方向很明确:减少上下文切换次数 + 减少数据拷贝次数。而零拷贝技术,就是为此而生的最优解之一。
零拷贝技术:如何做到“少拷贝、少切换”?
零拷贝的核心思路是:让数据只在内核空间和硬件之间传输,避免在用户态和内核态之间来回拷贝。常见的实现方式有两种:mmap+write 和 sendfile,我们逐一拆解。
1. 第一种:mmap + write(减少1次CPU拷贝)
传统 read() 的问题是会把内核缓冲区的数据拷贝到用户缓冲区,mmap(内存映射)就是为了解决这个问题。它的核心逻辑是:把内核缓冲区直接“映射”到用户空间,这样用户程序就能直接操作内核缓冲区的数据,不用再拷贝一次。优化后的代码:
buf = mmap(file, len); // 内核缓冲区映射到用户空间
write(sockfd, buf, len); // 直接操作映射后的缓冲区
对应的传输流程:
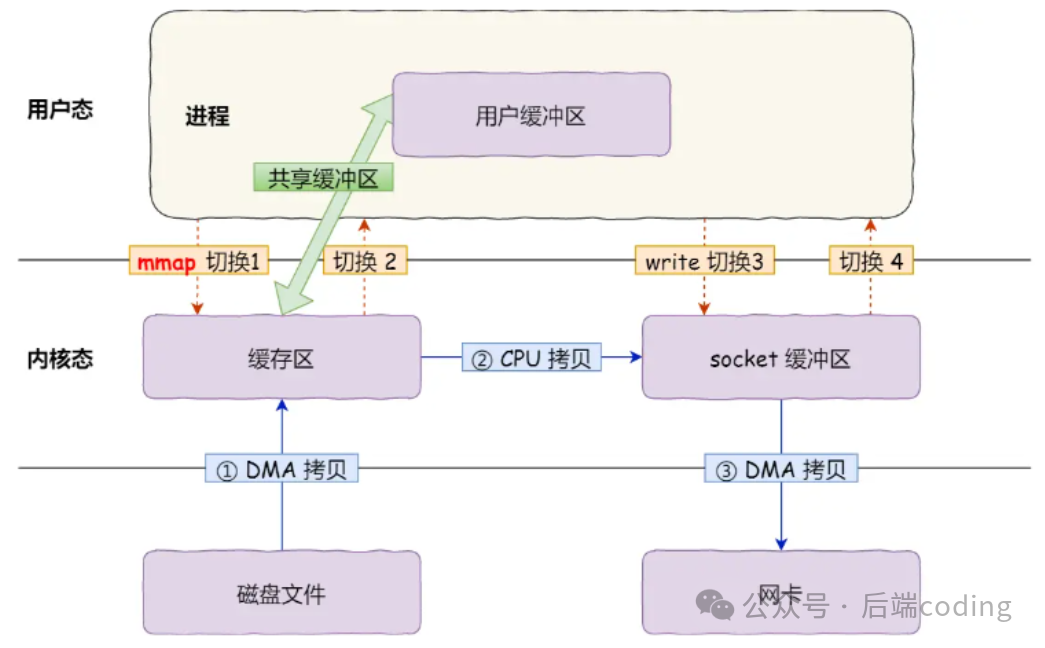
可以看到:数据拷贝次数从4次减少到3次(去掉了“内核→用户”的CPU拷贝),但上下文切换还是4次(因为还是两次系统调用)。所以这只是“部分优化”,不是真正的零拷贝。它深入涉及到操作系统的内存管理和进程地址空间映射原理。
2. 第二种:sendfile(真正的零拷贝,靠SG-DMA加持)
Linux内核2.1版本推出了 sendfile 系统调用,专门用于文件传输。它的核心优势是:把 read 和 write 两个系统调用合并成一个,减少上下文切换;同时让数据全程在内核空间传输,彻底避免CPU拷贝。
sendfile 的函数定义:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
// out_fd:目标文件描述符(比如socket)
// in_fd:源文件描述符(比如磁盘文件)
// offset:源文件偏移量
// count:要传输的字节数
第一步优化(无SG-DMA):
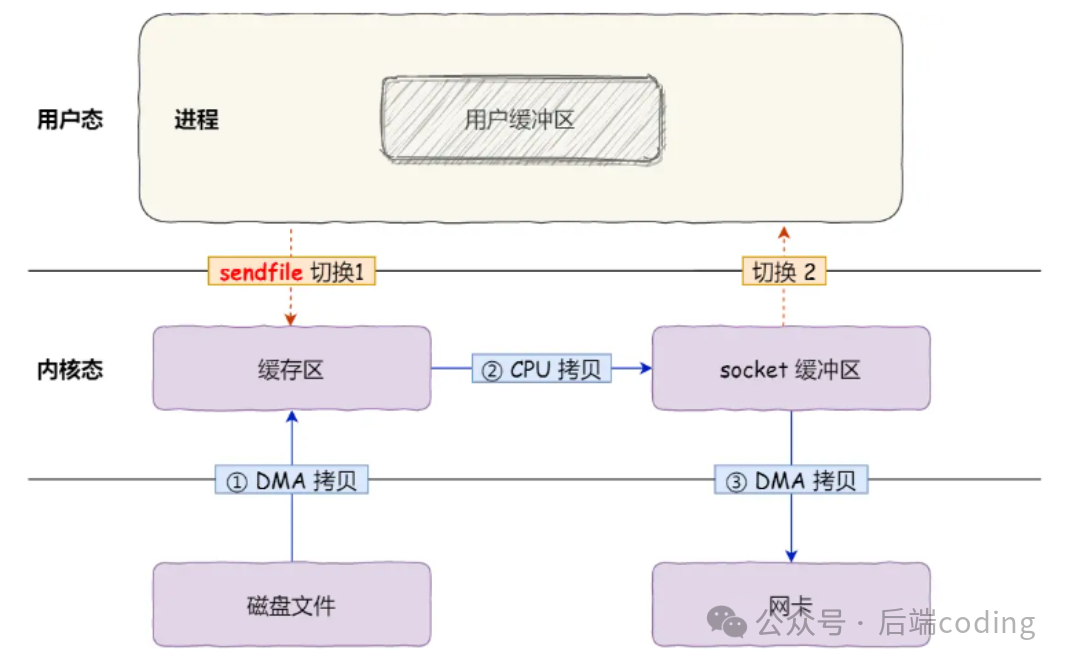
此时:上下文切换从4次减少到2次(一次系统调用),数据拷贝从4次减少到3次(还有一次“内核缓冲区→socket缓冲区”的CPU拷贝)。
第二步优化(开启SG-DMA):
如果网卡支持SG-DMA(分散-聚集DMA)技术,还能去掉最后一次CPU拷贝。SG-DMA的能力是:可以直接读取内核缓冲区的分散数据,不用先汇总到socket缓冲区。
最终的零拷贝流程:
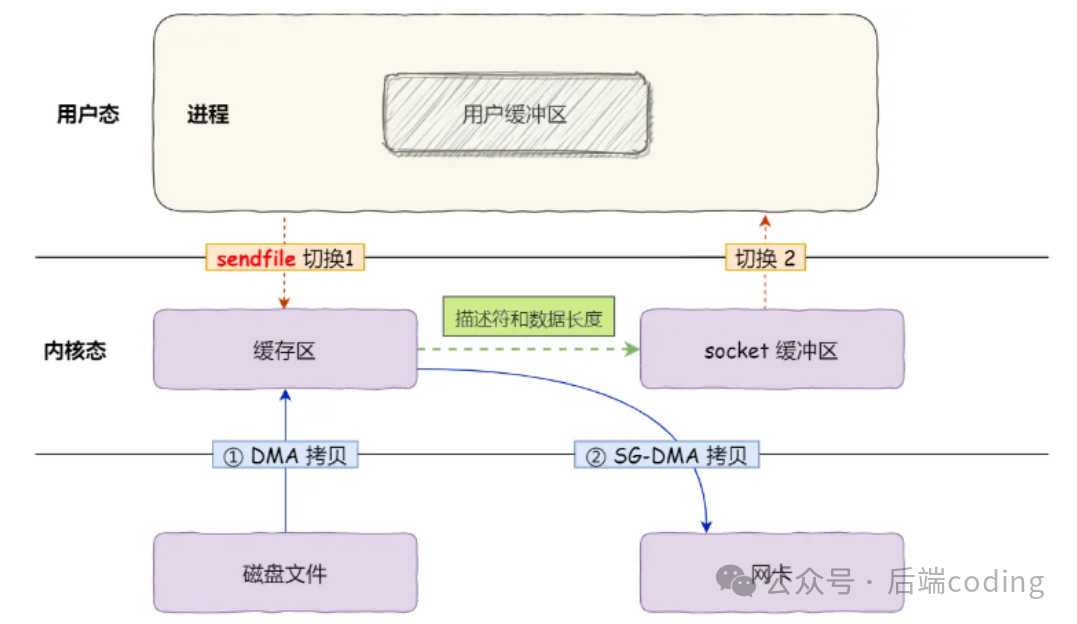
此时:2次上下文切换 + 2次DMA拷贝,全程没有CPU参与数据搬运——这就是真正的“零拷贝”(这里的“零”指的是“零CPU拷贝”,不是零数据移动)。这种优化对于提升高并发网络服务的吞吐量至关重要。
测试数据显示:零拷贝技术能让文件传输性能提升至少一倍,在大文件传输场景下,提升效果更明显。
实战场景:零拷贝在哪些知名项目中应用?
零拷贝不是纸上谈兵,而是被广泛应用在高并发、大数据传输的核心项目中,最典型的就是Kafka和Nginx。
1. Kafka:靠零拷贝实现海量数据高吞吐
Kafka作为分布式消息队列,能轻松处理每秒几十万条消息,核心原因之一就是用到了零拷贝。如果你查看Kafka的源码,会发现它最终调用了Java NIO的 transferTo 方法:
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
这个方法的底层逻辑是:如果操作系统支持 sendfile(比如Linux),就直接调用 sendfile 系统调用,实现零拷贝;如果不支持,就降级使用其他方式。这是Kafka实现高吞吐的核心技术之一。
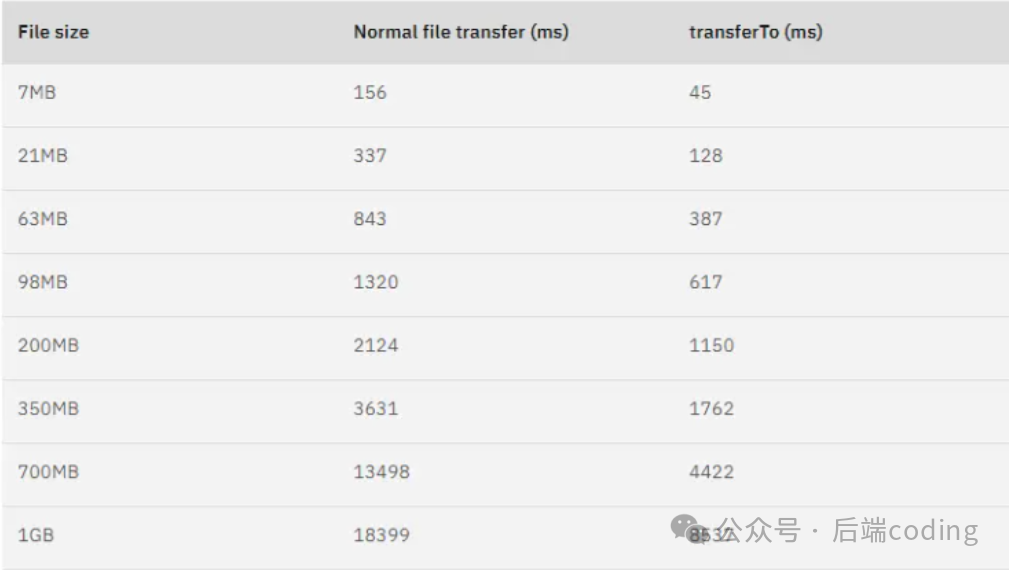
有工程师做过测试:在相同硬件条件下,用零拷贝传输文件,能比传统方式缩短65%的时间,吞吐量直接翻倍。
2. Nginx:默认开启零拷贝,优化静态文件传输
Nginx作为高性能Web服务器,处理静态文件(图片、视频、文档)的能力极强,秘诀也在于零拷贝。它的零拷贝功能通过 sendfile 配置控制,默认是开启的:
http {
...
sendfile on; # 开启零拷贝
...
}
配置说明:
sendfile on:使用 sendfile 零拷贝技术,2次上下文切换+2次DMA拷贝;sendfile off:使用传统 read+write,4次上下文切换+4次数据拷贝;- 注意:需要Linux内核2.1及以上版本支持。
总结:零拷贝的优势、局限与最佳实践
我们用一张表快速回顾核心知识点:
| 传输方式 |
上下文切换次数 |
数据拷贝次数(CPU/DMA) |
核心优势 |
| 传统read+write |
4次 |
2次CPU+2次DMA |
实现简单,适配所有场景 |
| mmap+write |
4次 |
1次CPU+2次DMA |
减少1次CPU拷贝,适合需操作文件内容的场景 |
| sendfile(零拷贝) |
2次 |
0次CPU+2次DMA |
性能最优,适合纯文件传输场景 |
1. 零拷贝的核心优势
基于操作系统的PageCache(页缓存)实现:PageCache会缓存最近访问的数据,提升缓存命中率;同时协助I/O调度算法实现“IO合并”和“预读”,让顺序读性能远超随机读——这进一步放大了零拷贝的优势。
2. 零拷贝的局限(别用错场景!)
零拷贝不是万能的,有两个关键局限:
- 不能修改文件内容:如果需要对数据进行压缩、加密等加工再传输,零拷贝不适用(因为数据全程在内核空间,用户程序无法操作);
- 不适合大文件传输:大文件会占据大量PageCache,导致热点小文件无法利用缓存(缓存命中率低),反而降低性能。
3. 最佳实践建议
在实际项目中,建议根据文件大小动态选择传输方式:
- 小文件(比如100MB以下):用零拷贝,充分利用PageCache提升性能;
- 大文件(比如100MB以上):用“异步IO + 直接IO”,绕开PageCache,避免占用缓存资源。
比如Nginx中,可以通过配置文件大小阈值,实现这种动态切换,兼顾小文件和大文件的传输性能。
最后:一句话看懂零拷贝
零拷贝的本质,是让数据“少走弯路”——避免在用户态和内核态之间来回搬运,全程在内核空间完成传输,从而最大化释放CPU资源,提升系统吞吐量。
深入理解I/O模型和零拷贝技术,是构建高性能服务的基础。如果你想了解更多关于网络协议、系统设计或技术原理的深度解析,欢迎访问云栈社区与其他开发者交流学习。
 发表于 2026-1-16 01:20:46
|
查看: 191|
回复: 0
发表于 2026-1-16 01:20:46
|
查看: 191|
回复: 0
