一、 概述
1. 什么是SPI
SPI 即 Service Provider Interface,中文可译为“服务提供者接口”。
其核心思想在于将服务接口和具体的服务实现进行分离,从而实现服务调用方和服务实现者之间的解耦。这一机制能显著提升程序的扩展性和可维护性。最直接的益处是,当需要修改或替换服务的具体实现时,调用方的代码无需任何改动。
在 Java 的生态体系中,SPI机制有着广泛的应用,例如数据库驱动加载(JDBC)、Spring框架的自动装配,以及Dubbo等分布式系统框架的扩展实现。
2. 对比API有什么区别
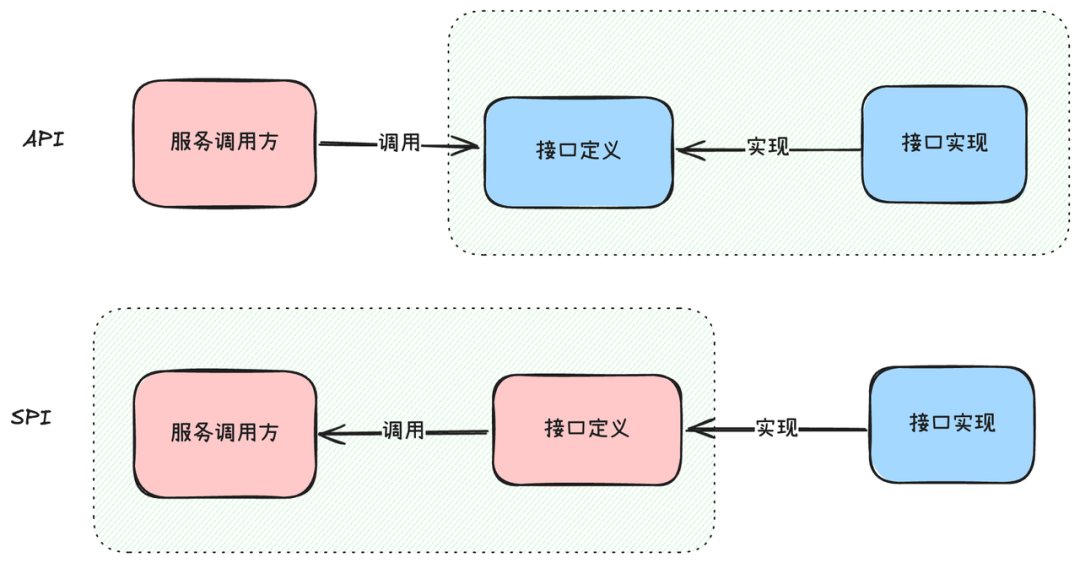
- API (Application Programming Interface):接口的定义和实现通常由服务提供方一手包办。这意味着接口的控制权掌握在服务提供方手中,调用方根据接口定义进行调用。
- SPI (Service Provider Interface):接口的定义由服务调用方(通常是框架或平台)来制定,而具体的实现则由不同的服务提供方根据接口契约来完成。SPI机制能够在运行时动态地发现和加载不同的实现类,因此接口的控制权转移到了服务调用方。
简单来说,API是“你给我什么,我用什么”,而SPI是“我定规则,你们来适配”。
3. SPI有什么用
解耦
在框架或库的开发中,我们常常需要依赖一些可插拔的功能组件,但又不想在代码中硬编码具体的实现类,以保持架构的灵活性。SPI机制通过定义标准接口和动态加载实现类,完美地实现了框架核心与服务实现之间的解耦。
场景举例:
- 一个数据库连接池库需要支持多种数据库(如 MySQL、PostgreSQL),可以通过SPI动态加载对应的数据库驱动。
- 日志门面框架(如SLF4J)可以通过SPI机制加载具体的日志库实现(如Log4j、Logback)。
可扩展
SPI提供了动态发现和加载服务的能力,这使得应用程序能够极其方便地实现功能扩展,而无需修改现有的核心代码。
场景举例:
- 一个文件处理系统需要支持不同的文件格式(如JSON、XML、CSV)。通过SPI机制,它可以动态发现不同的文件解析器插件,无需在代码中预先枚举所有支持的格式。
动态加载
SPI是实现插件化架构的利器。它允许系统通过动态加载具体的服务实现来增加或减少功能模块,整个过程无需重新发布或重启整个应用。
场景举例:
- Web服务器(如Tomcat)可以通过SPI机制动态加载不同的HTTP处理器或过滤器。
- 一个数据分析平台可以通过SPI机制动态加载新的数据分析算法插件。
4. SPI工作机制
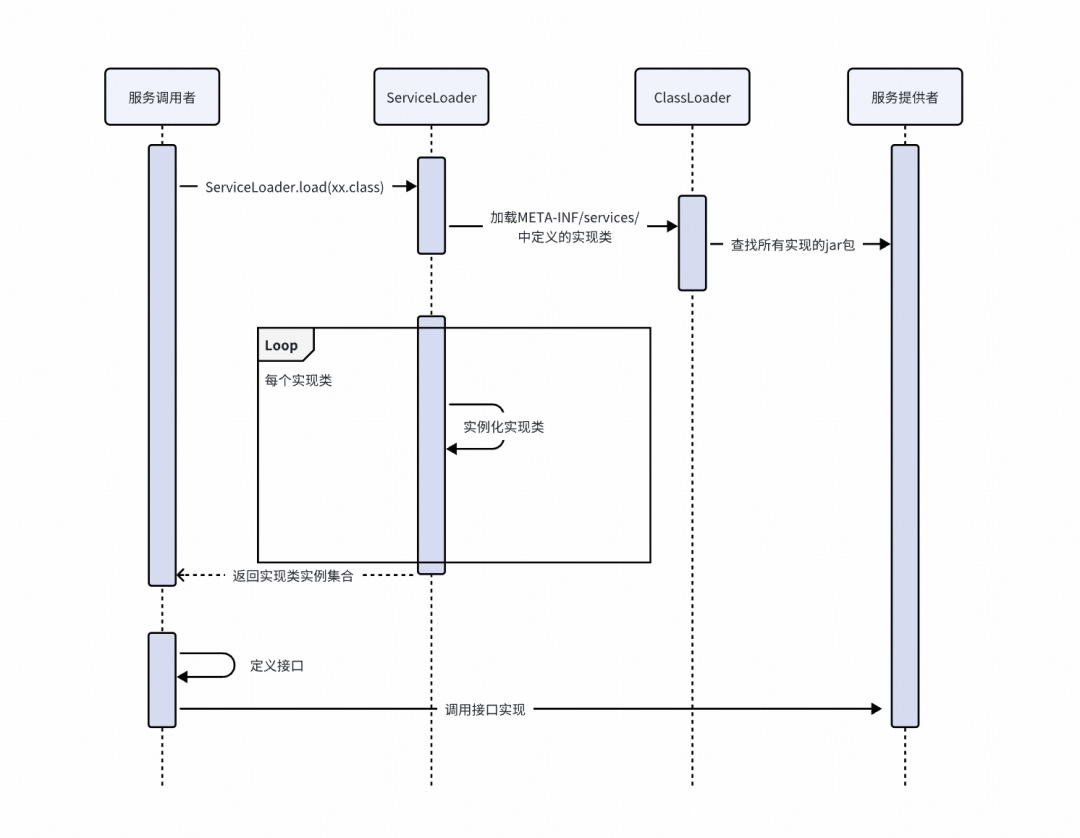
其核心工作流程可以概括为以下几个步骤:
- 服务提供者 在
META-INF/services/ 目录下,创建一个以接口全限定名命名的文件。
- 文件内容是该接口具体实现类的全限定名,每行一个。
- 服务调用方通过
java.util.ServiceLoader 工具类,加载并实例化文件中配置的所有实现类。
- 调用方即可使用这些实例。
这个机制的本质是一种“约定优于配置”的思想,将类与类之间的依赖关系,从代码转移到了配置文件之中。
二、 ServiceLoader
ServiceLoader 是JDK中提供的服务加载器,位于 java.util 包下。它是一个final类,不可被继承,是实现SPI机制的核心工具。
1. 源码解析
首先,我们看一下 ServiceLoader 的核心成员变量:
public final class ServiceLoader<S>
implements Iterable<S>
{
// 默认加载路径前缀
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
// 被加载的服务接口Class对象
private final Class<S> service;
// The class loader used to locate, load, and instantiate providers
// 用于定位、加载和实例化提供者的类加载器
private final ClassLoader loader;
// Cached providers, in instantiation order
// 本地缓存,key: 实现类全限定名 value:实现类实例
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// The current lazy-lookup iterator
// 懒加载迭代器
private LazyIterator lookupIterator;
}
※ load方法
这是暴露给外部使用的静态工厂方法。
// 暴露给外部使用的加载方法
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
// 构造方法私有化
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
// 如果指定了classLoader,则使用该classLoader,如果没有指定,则使用默认classLoader
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
ClassLoader cl = Thread.currentThread().getContextClassLoader(); 这行代码通过获取线程上下文类加载器(Thread Context ClassLoader) 来保证在复杂的类加载环境下(如Web容器、OSGi)也能正确加载到服务实现类。
※ reload方法
用于清空缓存,重新加载服务。
public void reload() {
// 清空缓存
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
※ 迭代与懒加载
ServiceLoader 实现了 Iterable 接口。当调用 iterator() 方法时,会优先从缓存 providers 中查找,若未命中,则交给内部的 LazyIterator 进行懒加载。
public Iterator<S> iterator() {
return new Iterator<S>() {
// 本地缓存providers
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
// 优先查本地缓存
if (knownProviders.hasNext())
return true;
// 没有则在LazyInterator中进行查找
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
LazyIterator 是实现懒加载的关键。只有在真正调用 hasNext() 或 next() 方法遍历时,它才会去加载并实例化对应的实现类。其核心逻辑如下(简化示意):
hasNextService(): 在 META-INF/services/ 目录下寻找以接口全限定名命名的配置文件,逐行读取实现类的类名。nextService(): 使用 Class.forName() 加载上一步读取到的类,并通过反射 newInstance() 创建对象,然后将其放入缓存 providers 中,最后返回该实例。
正是通过 LazyIterator,ServiceLoader 实现了“用时方加载”,避免了启动时一次性加载所有实现类可能带来的性能开销。
2. 小结
ServiceLoader 的本质,就是按照约定,读取 META-INF/services/ 目录下特定文件,然后通过反射机制加载文件中声明的所有接口实现类,从而达成接口与实现的解耦。
※ 优点
- 解耦:接口与实现分离,无需在代码中硬编码实现类。
- 扩展性:新增实现只需添加配置文件,无需修改调用方代码。
※ 缺点
- 线程不安全:
ServiceLoader 非线程安全,且每次加载都会返回新的实例,不能保证单例。
- 性能开销:每次迭代都会重新解析配置文件,并且会实例化配置文件中指定的所有实现类,无论是否用到。
- 无健壮性:配置错误(如类未找到)会直接抛出异常,缺乏优雅降级机制。
- 功能简单:仅支持按类型加载,无法按名称(key)获取指定实现,也不支持依赖注入等高级特性。
正因为有这些局限性,像Spring、Dubbo这样的框架都在其基础上进行了强化和扩展。
三、 SPI实际应用场景
1. JDBC
JDK中定义了 java.sql.Driver 接口,不同数据库厂商(如MySQL、PostgreSQL)负责实现这个接口。当我们使用JDBC时,经典的代码如下:
// 获取数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123");
// 创建statement
Statement statement = connection.createStatement();
// 执行sql
ResultSet resultSet = statement.executeQuery("select * from student");
关键在于第一行 DriverManager.getConnection()。DriverManager 在类加载时会执行静态代码块,其核心是 loadInitialDrivers() 方法,其中就用到了 ServiceLoader:
private static void loadInitialDrivers() {
...
// 这里就使用ServiceLoader去加载接口实现类
// 以mysql-connector-java为例,加载的是 com.mysql.cj.jdbc.Driver
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
...
}
遍历 ServiceLoader 的过程,会触发 com.mysql.cj.jdbc.Driver 类的加载和初始化。在该驱动类的静态代码块中,会向 DriverManager 注册自己:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}
随后,DriverManager.getConnection() 方法会遍历所有已注册的 Driver 实例,尝试连接,直到成功为止。这样,我们只需在项目的数据库驱动依赖,无需修改任何代码,就能切换不同的数据库。
2. Spring
Spring 并没有直接使用 Java 原生的 SPI 机制,但其 spring.factories 机制在思想和实现上都非常类似,并且功能更为强大。它通过读取 META-INF/spring.factories 文件来实现自动装配、应用上下文初始化器等扩展功能。
SpringFactoriesLoader 是其核心加载类,逻辑与 ServiceLoader 相似,但支持更灵活的配置格式(key-value形式)和缓存机制。
一个典型的 spring.factories 文件内容如下:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.MyAutoConfiguration
等号左边是接口或抽象类的全限定名,右边是实现类的全限定名,多个实现类用逗号分隔。Spring Boot 的自动装配正是基于此机制实现。
3. Dubbo
Dubbo 的扩展点机制也使用了 SPI 思想,但它对 JDK 原生 SPI 进行了全面的优化和增强,形成了自己的一套 ExtensionLoader 体系。
原生 SPI 会加载并实例化配置文件中所有的实现类,可能造成资源浪费;同时,配置文件中只是简单列出类名,无法按名(key)获取。Dubbo 的扩展点机制解决了这些问题。
Demo
- 定义扩展点接口,使用
@SPI 注解标注。
@SPI
public interface DemoSpi {
void say();
}
- 编写实现类。
public class DemoSpiImpl implements DemoSpi {
public void say() {
System.out.println("Hello Dubbo SPI");
}
}
- 添加配置文件。在
META-INF/dubbo/ 目录下创建以接口全限定名命名的文件(如 com.example.DemoSpi),内容为 key=实现类全限定名。
demoSpiImpl=com.xxx.xxx.DemoSpiImpl
- 使用
ExtensionLoader 获取扩展实例。
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<DemoSpi> extensionLoader =
ExtensionLoader.getExtensionLoader(DemoSpi.class);
DemoSpi dmeoSpi = extensionLoader.getExtension("demoSpiImpl");
dmeoSpi.sayHello();
}
}
源码解析与优化
ExtensionLoader 的 getExtension 方法是主要入口,其核心流程 createExtension 包含了以下优化步骤:
- 按名加载:通过
getExtensionClasses() 加载所有扩展类配置,缓存为一个 Map<name, Class>,这样就可以根据 name(如"demoSpiImpl")精准获取对应的实现类,而不是加载全部。
- 单例缓存:对已实例化的扩展对象进行缓存,保证同名的扩展点是单例。
- 依赖注入 (IOC):通过
injectExtension 方法,自动为扩展实例注入其依赖的其他扩展点。这是原生SPI不具备的高级功能。
- 包装类 (AOP):支持
Wrapper 类对扩展点进行包装,实现类似AOP的拦截增强功能。例如,Dubbo的 Protocol 扩展点有 ProtocolFilterWrapper, ProtocolListenerWrapper 等包装类,为其添加过滤器和监听器链。
- 自适应扩展:通过
@Adaptive 注解和动态编译,实现运行时根据URL参数动态选择扩展实现,这是Dubbo非常核心的灵活性设计。
Dubbo SPI应用场景
- 协议扩展 (
Protocol):支持 dubbo, http, grpc, rest 等。
- 集群容错策略 (
Cluster):支持 failover, failfast, failsafe 等。
- 过滤器 (
Filter):提供调用链的拦截和扩展能力。
四、 总结
SPI机制是一种强大的解耦和扩展模式,其核心在于通过配置文件动态绑定接口与实现。然而,在实际使用原生 ServiceLoader 时,也需要注意一些问题:
※ 资源浪费与性能问题
ServiceLoader 会实例化配置文件中所有的实现类。如果某些实现类初始化成本高或不常用,会造成资源浪费。Dubbo的按需加载(按name获取)对此进行了优化。
※ 多个实现类加载顺序问题
ServiceLoader 加载实现类的顺序由ClassPath中jar包的顺序决定。如果业务逻辑依赖于获取到的第一个实现,在不同环境(如开发、测试、生产)下可能会因加载顺序不一致而导致问题。应尽量避免对加载顺序有强依赖。
※ 类重复加载问题
如果ClassPath中存在多个jar包声明了同一个接口的相同实现类,可能导致该类被多次加载和实例化,可能引发单例失效或资源冲突。
尽管有这些注意事项,SPI机制在构建可插拔、高扩展性的系统架构方面,其价值是毋庸置疑的。从JDBC到Spring,再到Dubbo,我们都能看到这一思想的身影和演化。理解SPI,不仅能帮助我们更好地使用这些框架,也能为设计自己的可扩展系统提供宝贵的思路。
本文由云栈社区进行技术优化和分享,更多关于Java、分布式系统等深度技术文章,欢迎访问云栈社区进行交流学习。
 发表于 2026-1-16 16:25:52
|
查看: 175|
回复: 0
发表于 2026-1-16 16:25:52
|
查看: 175|
回复: 0
