在深度学习,尤其是计算机视觉和时序预测任务中,卷积神经网络(CNN)几乎是标配。但随着模型越来越深、参数越来越多,计算量和推理效率逐渐成为瓶颈。
为了解决“性能强但太重”的问题,深度可分离卷积(Depthwise Separable Convolution) 应运而生,并成为 MobileNet、Xception 等轻量化模型的核心技术。
本期我们将通过通俗易懂的案例和代码,详解其工作原理,并与标准卷积进行对比。
什么是深度可分离卷积?
传统卷积把空间特征提取和通道特征融合一次性完成,而深度可分离卷积将这一步拆分成了两步:
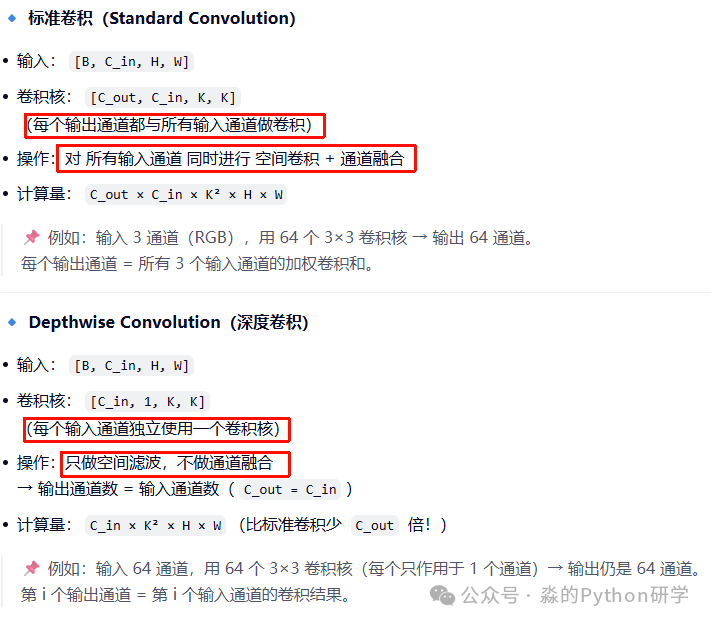
1️⃣ Depthwise Convolution(逐通道卷积)
- 每个输入通道 单独使用一个卷积核
- 只负责提取空间特征
- 不做通道之间的信息混合
2️⃣ Pointwise Convolution(逐点卷积)
- 使用 1×1 卷积
- 负责在不同通道之间进行特征融合
- 决定输出通道数
简单来说,深度可分离卷积的策略是“先看清每个通道的细节,再统一做决策”。
为什么它计算高效?

注意:上图的公式中未考虑 bias(偏置项)参数。
深度可分离卷积用更聪明的方式做卷积,在几乎不牺牲性能的前提下,大幅降低了计算成本。它通过解耦空间滤波与通道融合,避免了标准卷积中大量的冗余计算。
与标准卷积对比
可视化理解
我们可以通过一个简单的例子来直观理解:
输入: [C_in=3, H, W] (如 RGB 图像)
标准卷积:
卷积核1: 跨 R+G+B → 输出通道1
卷积核2: 跨 R+G+B → 输出通道2
...
Depthwise Conv:
卷积核R: 只作用于 R 通道 → 输出通道R
卷积核G: 只作用于 G 通道 → 输出通道G
卷积核B: 只作用于 B 通道 → 输出通道B
Depthwise Conv 不混合通道信息! 它只在每个通道内部做空间滤波(如边缘检测、模糊等)。正因为如此,它需要一个后续步骤来整合信息。
# Depthwise Separable Conv = Depthwise Conv + Pointwise Conv
x = depthwise_conv(x) # [B, C_in, H, W] → [B, C_in, H, W]
x = pointwise_conv(x) # [B, C_in, H, W] → [B, C_out, H, W] (1x1 conv)
因为 Depthwise Conv 无法跨通道交互,所以实际应用中总会接一个 1×1 卷积(Pointwise Conv) 来融合通道:
- 总计算量:C_in × K² × H × W + C_in × C_out × H × W
- 相比标准卷积,计算量减少约 1/C_out + 1/K² 倍(通常可节省 8~9 倍 的计算量)。
代码案例
相同输入和输出下,我们通过 PyTorch 代码来直观对比标准卷积和深度可分离卷积的实现与参数量。
import torch
import torch.nn as nn
# ----------------------------
# 1. 构造输入数据
# 假设: batch=2, 输入通道=3, 高=32, 宽=32
# ----------------------------
B, C_in, H, W = 2, 3, 32, 32
C_out = 4
kernel_size = 3
padding = 1 # 保持空间尺寸不变
x = torch.randn(B, C_in, H, W)
print(f"Input shape: {x.shape}") # [2, 3, 32, 32]
# ----------------------------
# 2. 标准卷积 (Standard Convolution)
# ----------------------------
standard_conv = nn.Conv2d(
in_channels=C_in,
out_channels=C_out,
kernel_size=kernel_size,
padding=padding,
bias=False # 不加偏置,便于对比参数量
)
y_standard = standard_conv(x)
print(f"Standard Conv output shape: {y_standard.shape}") # [2, 4, 32, 32]
# 计算参数量
num_params_standard = sum(p.numel() for p in standard_conv.parameters())
print(f"Standard Conv parameters: {num_params_standard}") # 应为 4 * 3 * 3 * 3 = 108
# ----------------------------
# 3. 深度可分离卷积 (Depthwise Separable Convolution)
# 由两部分组成:
# (a) Depthwise Conv: groups = C_in
# (b) Pointwise Conv: 1x1 conv to change channel number
# ----------------------------
# (a) Depthwise Convolution
depthwise_conv = nn.Conv2d(
in_channels=C_in,
out_channels=C_in, # 输出通道 = 输入通道
kernel_size=kernel_size,
padding=padding,
groups=C_in, # 关键!每个通道独立卷积
bias=False
)
# (b) Pointwise Convolution (1x1)
pointwise_conv = nn.Conv2d(
in_channels=C_in,
out_channels=C_out,
kernel_size=1, # 1x1 卷积
bias=False
)
# 组合
y_depthwise = depthwise_conv(x) # [2, 3, 32, 32]
y_separable = pointwise_conv(y_depthwise) # [2, 4, 32, 32]
print(f"Depthwise output shape: {y_depthwise.shape}") # [2, 3, 32, 32]
print(f"Separable Conv output shape: {y_separable.shape}") # [2, 4, 32, 32]
# 计算总参数量
num_params_dw = sum(p.numel() for p in depthwise_conv.parameters())
num_params_pw = sum(p.numel() for p in pointwise_conv.parameters())
num_params_separable = num_params_dw + num_params_pw
print(f"Depthwise Conv parameters: {num_params_dw}") # 3 * 1 * 3 * 3 = 27
print(f"Pointwise Conv parameters: {num_params_pw}") # 4 * 3 * 1 * 1 = 12
print(f"Total Separable Conv parameters: {num_params_separable}") # 27 + 12 = 39
# ----------------------------
# 4. 验证输出维度一致(但数值不同)
# ----------------------------
print("\n✅ Both outputs have same shape:", y_standard.shape == y_separable.shape)

从运行结果可以清晰看到,在输入输出尺寸完全相同的设定下,深度可分离卷积的参数量 (39) 远小于标准卷积 (108),这直观印证了其高效的特性。这种设计对于移动端和边缘设备的模型训练与部署意义重大。

总结
深度可分离卷积的核心思想是解耦:将标准卷积同时完成的“空间特征提取”和“通道特征融合”两步拆分开,先独立处理每个通道,再统一整合。这种设计哲学使其在计算效率和参数数量上取得了巨大优势,成为构建高效深度学习模型的基石技术之一。
理解了这一原理,你就能更好地运用 MobileNet、Xception 等经典轻量化网络,也为设计自己的高效模型提供了思路。如果你想了解更多前沿的AIGC与模型优化技术,欢迎在 云栈社区 交流探讨。

 发表于 2026-1-17 01:33:21
|
查看: 238|
回复: 0
发表于 2026-1-17 01:33:21
|
查看: 238|
回复: 0
