高并发是构建大型系统架构的核心挑战之一。一个非常普遍的技术认知误区是:遇到高并发压力时,简单调大数据库连接池就能解决问题。但现实情况往往相反:连接池配置得越大,数据库可能崩溃得越快。
那么,为什么数据库连接池会“撑不住”高并发呢?其核心矛盾并非在于连接数量本身,而在于底层硬件资源的瓶颈与连接管理带来的额外软件开销。
连接池的核心职责是重用连接与限制最大连接数,从而避免为每个请求都创建和销毁数据库连接所带来的巨大性能损耗。
在高并发场景下,所有业务线程都会竞争连接池中有限的连接资源。当线程抢不到连接时,就只能在池外排队等待,导致应用响应时间变慢,从表面上看就像是连接池“撑不住了”。如果此时盲目调大连接池的 Maximum Pool Size,短期内可能让更多请求获得连接,访问速度变快。但副作用是数据库端的连接数会急剧飙升,导致其 CPU、内存、线程等核心资源竞争更加激烈,最终可能使数据库整体性能急剧下降,系统反而变得更不稳定。
一个直观的比喻是:数据库连接池就像餐厅里有限的餐桌。高并发时段出现排队是正常现象。如果你为了解决排队而无限增加餐桌,直到塞满整条街,这并不会加快厨房的出菜速度,反而会把厨师和整个后厨系统压垮。
如何系统性应对高并发挑战?
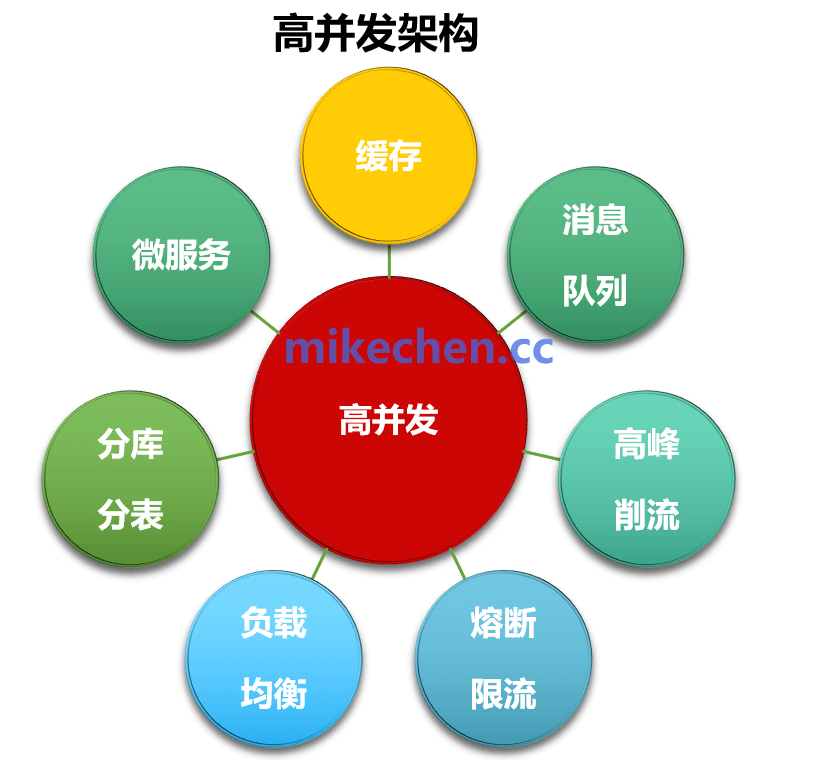
既然单纯扩大连接池不是万能解药,那么面对百万级并发请求时,我们应该采取哪些更有效的架构方案呢?
-
异步化与消息队列削峰
并非所有请求都需要实时同步写入数据库。利用 Kafka、RocketMQ 等消息队列,可以将瞬时高峰流量平滑掉,实现“削峰填谷”,让数据库按照自身可持续的处理能力来消费消息,避免被突发流量冲垮。
-
读写分离
在典型的互联网应用中,读请求往往占据总流量的80%以上。通过增加数据库从库(Slave),将大量的查询请求分摊到多个读节点上,可以显著减轻主库的压力,从而为主库腾出更多连接和资源来处理写操作。
-
缓存拦截
在请求到达数据库之前,使用 Redis 等缓存中间件拦截掉绝大部分的重复查询(如热点数据)。这是减轻数据库压力、提升系统吞吐量最有效的手段之一。
-
分库分表
单个数据库实例的连接数、CPU、I/O等硬件资源存在物理上限。当数据量和访问量达到单机瓶颈时,必须通过分库分表进行物理拆分,将数据和访问压力分散到多个数据库节点上,这是实现水平扩展的必经之路。
-
连接池精细化调优
- 设置固定大小的连接池:可以考虑将
Minimum Idle(最小空闲连接)设置为与 Maximum Pool Size(最大连接数)相等,避免连接在空闲时被回收后又频繁创建,减少不必要的开销。
- 配置合理的超时时间:为连接获取、SQL执行设置严格的超时。遵循“快速失败”(Fail Fast)原则,宁可让请求立即失败并明确报错,也不要让它们长时间等待、占用宝贵的线程和连接资源,从而避免雪崩效应。
希望以上关于高并发下数据库连接池的常见误区与核心架构方案的探讨,能对你有所启发。关于数据库调优、高并发架构设计等更多深度话题,欢迎在云栈社区与广大开发者一同交流学习。 |  发表于 2026-1-17 04:15:25
|
查看: 135|
回复: 0
发表于 2026-1-17 04:15:25
|
查看: 135|
回复: 0
