在MySQL数据库的运行体系中,数据的持久性和一致性是核心诉求,而Checkpoint机制正是支撑这一诉求的关键技术。无论是日常业务中的数据读写,还是系统故障后的恢复,Checkpoint都在背后默默发挥着重要作用。本文将全面拆解MySQL Checkpoint机制,帮助您搞懂它的工作原理、影响及优化方式。
Checkpoint机制:数据持久化的“定海神针”
MySQL的InnoDB存储引擎采用缓冲池(Buffer Pool)机制来优化读写性能,所有数据的修改操作都会先在内存缓冲池中进行,被修改后尚未写入磁盘的数据页被称为“脏页”。如果仅依赖内存存储,一旦系统崩溃,这些未持久化的脏页数据将全部丢失。
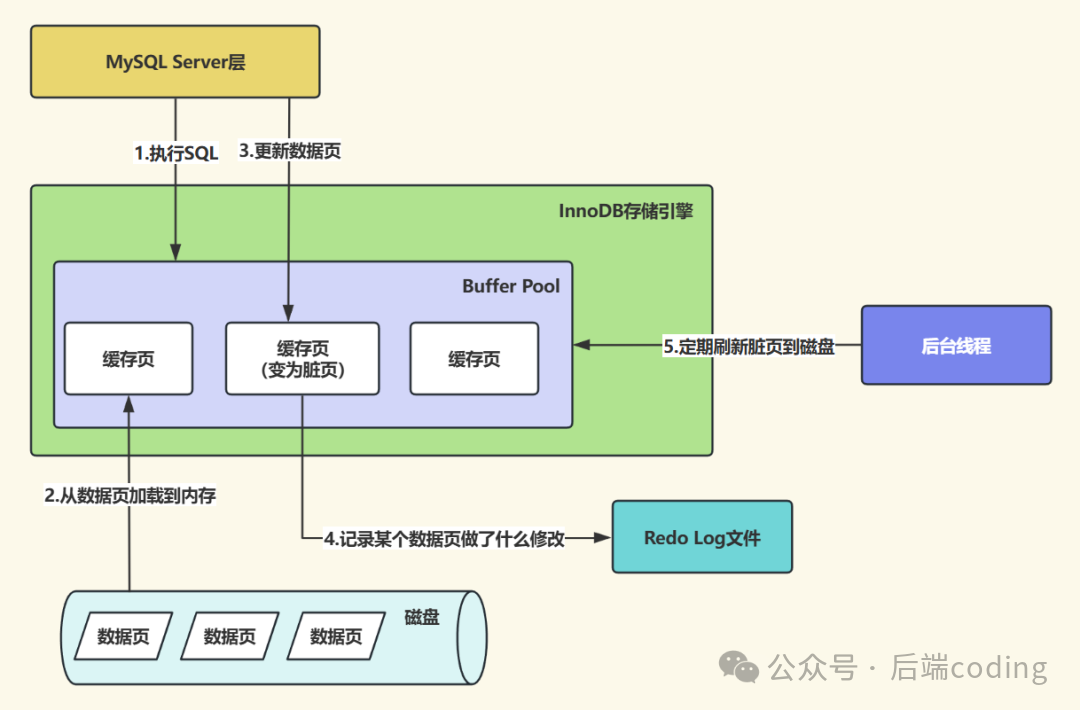
Checkpoint机制的核心目标,就是在特定时间点将内存缓冲池中的脏页批量刷新到磁盘数据文件中,同时记录当前的恢复点信息。这样一来,即便系统发生故障,也无需重放全部重做日志(Redo Log),只需从最近的Checkpoint点开始恢复,大幅提升恢复效率,同时保障数据持久化。
Checkpoint的触发条件:何时会执行刷新操作?
Checkpoint并非随机执行,而是由特定条件触发,主要分为以下四类场景,覆盖定期、阈值、主动关闭及日志切换等场景:
-
定期触发:MySQL通过配置参数控制定期刷新逻辑,核心参数为 innodb_io_capacity(定义InnoDB的I/O吞吐量上限,InnoDB后台I/O任务全局共享的总预算,避免后台任务过多占用I/O资源导致业务SQL卡顿)和 innodb_checkpoint_timeout(默认5分钟,控制定期Checkpoint的时间间隔)。系统会根据这些参数,周期性地执行Checkpoint,平衡脏页积累量与I/O压力。
-
脏页比例达阈值:当缓冲池中脏页占比达到预设阈值时,会触发Checkpoint以避免脏页过度积累。核心控制参数为 innodb_max_dirty_pages_pct(默认75%,表示脏页占比达到75%时触发)和 innodb_max_dirty_pages_pct_lwm(低水位线,默认30%,达到后开始缓慢刷新脏页)。
-
系统关闭时触发:当执行 SHUTDOWN 命令正常关闭数据库时,MySQL会执行一次“完整Checkpoint”,将缓冲池中所有脏页全部刷新到磁盘,确保数据无丢失,此时数据库重启后无需执行复杂恢复操作。
-
重做日志切换时触发:InnoDB的重做日志以循环写入的方式工作,当当前重做日志文件写满需要切换到下一个文件时,会触发Checkpoint。这是因为重做日志文件被覆盖前,必须确保该日志对应的脏页已刷新到磁盘,否则会导致日志记录丢失,无法完成数据恢复。
Checkpoint的执行过程:三步完成脏页刷新
Checkpoint的执行是一个有序的过程,核心分为“选页-写盘-更新元数据”三步,确保数据一致性和可追溯性:
-
选择脏页:并非所有脏页都会被一次性刷新,InnoDB采用“LRU(最近最少使用)+ 脏页优先级”的混合算法选择待刷新脏页。优先刷新最近最少使用的脏页,同时兼顾脏页的老化程度,选择LSN最小的旧脏页(优先刷旧脏页,避免redo log日志链过长)。避免频繁刷新热点数据页,平衡I/O效率与业务访问性能。
-
写入磁盘:将选中的脏页批量写入磁盘的数据文件(.ibd文件)。为了减少对业务的影响,InnoDB会采用“批量写入+后台线程”的方式执行,避免单线程同步写入导致的阻塞。此外,按配额划分批次,避免单次刷盘占用过多I/O资源,影响前台业务。
-
更新元数据:刷新完成后,主要进行两步操作:一是更新LSN元数据,包括同步更新.ibd文件中数据页头部的FIL_PAGE_LSN(与内存脏页LSN保持一致),计算本次刷盘所有脏页的最大LSN,将系统表空间ibdata1中的全局Checkpoint LSN更新为最大值,用于标记该LSN之前的所有数据已持久化;二是同时更新缓冲池状态,将已刷新的脏页标记为干净页,同时更新事务日志的状态信息,确保恢复逻辑的准确性。
LSN:Checkpoint的“时间戳”与恢复核心
上面提到的LSN(Log Sequence Number,日志序列号)是贯穿Checkpoint与数据恢复的核心标识,本质是一个单调递增的逻辑编号,用于标记重做日志的位置和数据页的修改版本。这里需要区分4类LSN的本质与存储位置:
-
全局Checkpoint LSN:仅存储在系统表空间(ibdata1)中,标记整个InnoDB实例的持久化“分界点”,全局唯一,单调递增;
-
独立表空间页级LSN:存储在每个.ibd文件的数据页头部(FIL_PAGE_LSN),记录该数据页最后一次修改的LSN,页级别唯一,不同页数值不同;
-
redo log记录LSN:存储在每个redo log记录的头部字段,标记该条日志对应的数据修改操作的LSN,随事务执行单调递增,与修改顺序一致;
-
缓冲池数据页LSN:存储在缓冲池中所有数据页的内存副本头部,与磁盘页级LSN一致,脏页会随修改更新,如果LSN大于全局Checkpoint LSN,则表明是脏页;如果LSN小于或等于全局Checkpoint LSN,则为干净页。
在Checkpoint执行过程中,MySQL会记录当前的全局Checkpoint LSN,表示所有LSN小于该值的重做日志对应的修改都已通过脏页刷新持久化到磁盘。系统崩溃后,InnoDB会先找到最近的全局Checkpoint LSN,然后重放该LSN之后的所有重做日志,将数据恢复到崩溃前的状态,从而确保数据一致性。
Checkpoint对数据库性能的双重影响
Checkpoint是一把“双刃剑”,既能保障数据安全,也可能对数据库性能产生一定冲击,需辨证看待其影响。
1. 正面影响:筑牢数据安全防线
2. 负面影响:警惕性能瓶颈
-
I/O压力激增:Checkpoint批量刷新脏页会产生大量磁盘写入操作,若磁盘I/O能力不足,会导致写入延迟升高,影响业务的写入响应速度(如INSERT、UPDATE、DELETE操作)。
-
锁竞争与并发下降:刷新脏页时,InnoDB会对数据页加短期锁(如意向排他锁),若此时业务并发查询/修改该数据页,会产生锁等待,降低并发处理能力。
-
CPU资源占用:Checkpoint过程中的日志记录、元数据更新、脏页筛选等操作会消耗CPU资源,在高负载场景下可能加剧CPU瓶颈。
Checkpoint优化策略:平衡安全与性能
针对Checkpoint的性能影响,可通过参数调优、监控运维等方式优化,实现数据安全与业务性能的平衡。
1. 精准调整核心参数:
-
调整 innodb_max_dirty_pages_pct:根据业务读写特性调整阈值,读写频繁的业务可适当降低(如60%),减少单次Checkpoint的脏页量,降低I/O峰值;读多写少的业务可维持默认值,减少Checkpoint频率。
-
优化 innodb_io_capacity:根据磁盘I/O能力(如SSD和机械硬盘的差异)设置合理值,SSD可适当调大(如2000),充分利用I/O性能;机械硬盘需调小(如200),避免I/O阻塞。
-
配置 innodb_flush_neighbors:默认值为1,刷新脏页时会同时刷新相邻的脏页,机械硬盘可开启以减少寻道时间,SSD建议设为0,避免不必要的额外I/O。
2. 加强性能监控
通过 SHOW ENGINE INNODB STATUS 可查看当前的LSN信息,包括“Log sequence number”(当前日志LSN)、“Log flushed up to”(已刷新到磁盘的日志LSN)、“Last checkpoint at”(最近一次Checkpoint的LSN),三者的差值可反映日志刷新和Checkpoint的滞后情况。
比如,Log sequence number远大于Log flushed up to说明redo log缓冲区积压严重,此时数据库若宕机,会丢失对应的事务,数据一致性面临风险。如果Log flushed up远大于Last checkpoint at则表明Checkpoint滞后严重,此时数据库若宕机,恢复耗时会明显增加(秒级甚至分钟级),且若 redo log 即将写满,还会触发紧急 Checkpoint,导致数据库短暂阻塞,无法处理新事务。
=====================================
2026-01-16 16:00:00 0x7f90b2345678 INNODB MONITOR OUTPUT
=====================================
...
---
LOG
---
Log sequence number 1896543210 -- 对应:Log sequence number(当前日志LSN)
Log flushed up to 1896542000 -- 对应:Log flushed up to(已刷盘到redo log file的LSN)
Pages flushed up to 1896535000
Last checkpoint at 1896535000 -- 对应:Last checkpoint at(最近一次Checkpoint的LSN)
0 pending log flushes, 0 pending chkp writes
201 log i/o's done, 0.00 log i/o's per second
...
3. 错峰执行关键操作
将数据库备份、大批量数据导入/更新等操作安排在业务低峰期(如凌晨),同时避免这些操作与Checkpoint高峰期叠加,减少资源竞争。
4. 优化硬件与存储
升级磁盘为SSD,大幅提升I/O吞吐量,从硬件层面缓解Checkpoint的I/O压力;同时配置RAID阵列,进一步提升存储性能和可靠性。
总结
MySQL Checkpoint机制是数据持久化与故障恢复的核心支撑,其本质是通过“定期+阈值”的方式批量刷新脏页,平衡内存与磁盘的数据一致性。在实际运维中,需深入理解Checkpoint的触发条件与执行逻辑,结合业务特性优化参数和运维策略,既要通过Checkpoint筑牢数据安全防线,也要避免其成为数据库性能瓶颈,让数据库在安全与高效中稳定运行。
更多数据库技术深度讨论,欢迎访问云栈社区探索交流。
 发表于 2026-1-17 04:49:20
|
查看: 201|
回复: 0
发表于 2026-1-17 04:49:20
|
查看: 201|
回复: 0
