某些业务迭代场景下,需要对 MySQL 表中的数据进行全表更新。若数据量较小(万级别),直接执行 SQL 语句可能问题不大。但当数据量达到千万乃至亿级,尤其是在采用主从复制架构部署的 MySQL 环境中,问题便会凸显。
主从同步依赖 binlog 完成,binlog 主要有以下几种格式:
| 格式 |
内容 |
| statement |
记录在主库上执行的每一条 SQL 语句,日志量少,但部分函数(如 RAND())可能导致主从不一致。 |
| row |
记录每一条数据被修改或删除的详情,在批量 DELETE、UPDATE 时日志量可能非常大。 |
| mixed |
混合模式,一般语句修改使用 statement 格式记录,可能产生不一致的函数操作则使用 row 格式。 |
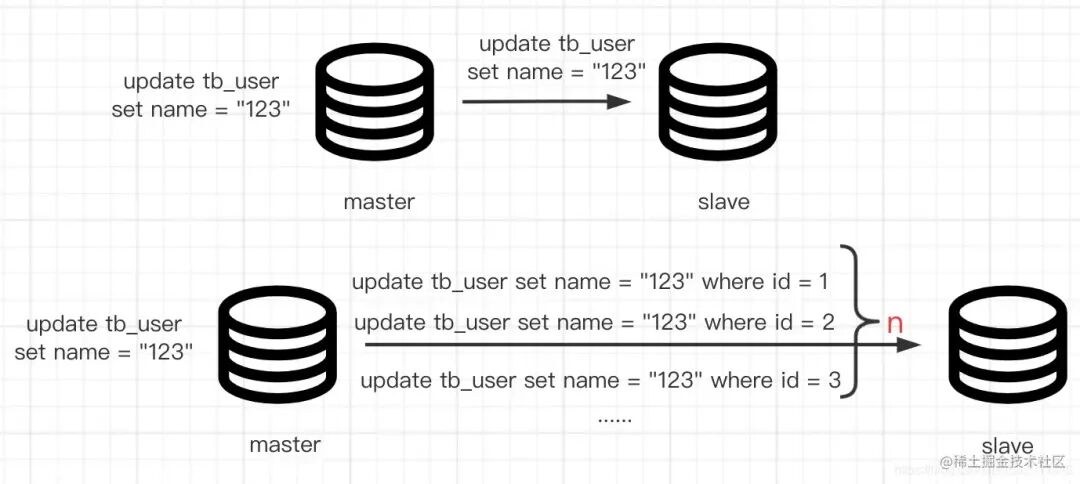
当前线上 MySQL 若使用 row 格式的 binlog 进行主从同步,在亿级数据表上执行全表 UPDATE,必然会在主库产生海量 binlog。随后,从库也需要阻塞并执行大量 SQL,风险极高。因此,直接执行全表更新是不可行的。本文将从一个最开始的 UPDATE SQL 出发,逐步拆解问题,直至推出最终上线的安全分批更新策略。
直接UPDATE的问题
我们曾需要将用户基本信息存储的 URL 从 HTTP 协议转换为 HTTPS 协议。数据库中有数千万级别的数据,涉及对多个大表进行全表更新。最初,我试探性地向 DBA 同事提出了一个简单的 UPDATE 语句,期望在业务低峰期执行:
update tb_user_info set user_img=replace(user_img, 'http://', 'https://')
这个方案的弊端显而易见:它会生成一个庞大的 row 格式 binlog 事件,对主库的 I/O、从库的同步回放造成巨大压力,极易引发同步延迟甚至中断。
深度分页问题
显然,上面的方案不合理。于是便考虑使用脚本分批处理,思路是写一个脚本,不断递增 LIMIT 的偏移量来分批更新,例如:
update tb_user_info set user_img=replace(user_img, 'http://', 'https://') limit 1,1000;
这个方案初看似乎可行,但仔细分析 MySQL 中 LIMIT 偏移量查询的原理便会发现问题:它需要在 B+ 树叶子节点上进行向后遍历查找。当偏移量较小时,效率尚可;一旦偏移量变得很大(即深度分页),其效率会急剧下降,近乎于全表扫描,这就是典型的“深度分页问题”。
IN查询的效率
既然 LIMIT 深度分页有问题,那么是否可以先批量查出 ID,然后使用 IN 子句进行批量更新呢?于是又构思了如下脚本:
select * from tb_user_info where id > {index} limit 100;
update tb_user_info set user_img=replace(user_img, 'http', 'https') where id in {id1,id3,id2};
结果证明,这仍然不是一个高效的方案。尽管 MySQL 对 IN 查询有一定的优化(如二分查找),但当 IN 列表过长时,优化器可能选择低效的执行计划,查询性能依然不理想。
最终版本:安全高效的分批策略
经过与 DBA 的多轮沟通,我们最终确定了如下 SQL 及脚本方案:
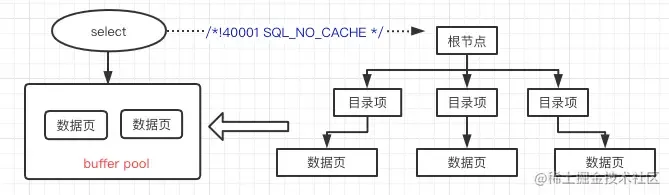
select /*!40001 SQL_NO_CACHE */ id from tb_user_info FORCE INDEX(`PRIMARY`) where id > “1” ORDER BY id limit 1000,1;
update tb_user_info set user_img=replace(user_img, 'http', 'https') where id >“{1}” and id <“{2}”;
这个方案有几个关键点需要注意:
/*!40001 SQL_NO_CACHE */:这个 Hint 指示本次查询不使用 InnoDB 的 Buffer Pool,也不会将本次查询涉及的数据页加载到 Buffer Pool 中作为热点缓存。这非常重要,因为全表更新扫描的是大量“冷数据”,我们不希望这些操作挤占掉业务正常访问的“热数据”缓存,从而影响线上业务性能。实际上,MySQL 官方的 mysqldump 工具在某些备份场景下也会使用类似的 Hint 来避免污染 Buffer Pool。FORCE INDEX(PRIMARY):强制本次查询使用主键索引,并按照主键排序。这是为了防止 MySQL 优化器在计算 I/O 成本后,可能选择其他非最优的索引,导致查询性能不稳定。- 范围更新替代 IN 或 LIMIT:第一个查询语句的目的是精确获取每一批数据的起始和结束 ID(通过
limit 1000,1 获取第1000条记录的ID作为批次边界)。第二个 UPDATE 语句则利用获取到的 ID 边界,改用 id > {start} and id < {end} 的范围查询进行更新。这种基于主键有序的范围查询效率远高于深分页或大 IN 列表查询。
通过这种方式,我们可以将全表更新包装成一个可控的任务接口。该接口能够动态调整批处理的大小和速度,同时监控数据库的主从同步延迟、IOPS、内存使用率等关键指标,实现“可观测、可调速”的安全更新。
虽然上述逻辑看起来是单线程的,但在实际接口实现中,完全可以基于线程池实现多批次并行处理(需确保不同批次处理的数据范围不重叠),从而在可控的前提下,提升整体更新速率的上限。
关于主键的思考
如果表的主键是 Snowflake 雪花算法生成的 ID 或自增 ID,数据基本上是按照主键顺序插入的,上述基于主键范围的分批策略非常有效。但如果主键是 UUID 这类无序数据呢?
对于无序主键,更好的做法是在业务层面进行“事前处理”:即在代码上线前,先对新增入库的数据做好转换(如写入时直接存为 HTTPS)。待新代码上线后,再针对历史数据进行一次性的全量补刷。这样可以最大限度地减少全量更新对数据库的冲击。
希望这篇关于大规模数据更新实践的文章能为你带来启发。在数据库运维和架构设计的路上,我们常常需要在 云栈社区 这样的技术论坛交流经验,以便在面对类似挑战时,能找到更稳妥的解决方案。
 发表于 2026-1-17 08:11:18
|
查看: 222|
回复: 0
发表于 2026-1-17 08:11:18
|
查看: 222|
回复: 0
