MySQL 作为开源关系型数据库的代表,凭借其轻量高效、稳定易用和完善的生态,已成为中小企业核心业务、互联网高并发场景乃至个人开发项目的首选。本文将围绕其核心语法体系、底层数据存储逻辑以及 ACID 事务特性这三个关键维度,深入剖析 MySQL 的工作原理与实践要点,帮助你从“会使用”迈向“懂原理”。
一、MySQL 核心语法体系
MySQL 语法遵循 SQL 标准,并在此基础上扩展了诸多自有特性。按功能划分,主要可分为数据定义语言(DDL)、数据操作语言(DML)、数据查询语言(DQL)和数据控制语言(DCL)四大类,覆盖了从数据库创建到权限管理的全流程。掌握这些关键字的分类与用法,是编写高效、规范 SQL 语句的基础。
1、数据定义语言(DDL):定义数据结构
DDL 用于定义数据库、表等基础结构,核心命令包括 CREATE、ALTER、DROP、TRUNCATE。以下是企业级开发中常用的标准操作示例:
操作数据库
-- 创建数据库(指定utf8mb4字符集,支持表情存储;指定排序规则)
CREATE DATABASE IF NOT EXISTS test_db DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
-- 安全删除数据库(避免因数据库不存在而报错)
DROP DATABASE IF EXISTS test_db;
-- 切换到要操作的数据库
USE test_db;
操作表结构
-- 创建用户表(包含主键、唯一约束、默认值、时间自动填充)
CREATE TABLE IF NOT EXISTS user (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT ‘用户ID(自动增长)’,
username VARCHAR(50) NOT NULL UNIQUE COMMENT ‘用户名(不能重复)’,
age TINYINT UNSIGNED DEFAULT 0 COMMENT ‘年龄(无负数,默认0)’,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间(自动填当前时间)’,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘更新时间(修改时自动更新)’
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT ‘用户信息表’;
-- 给用户表添加邮箱字段,放置在username字段之后
ALTER TABLE user ADD COLUMN email VARCHAR(100) DEFAULT NULL COMMENT ‘用户邮箱’ AFTER username;
-- 修改age字段类型,从TINYINT改为INT,以存储更大的数值
ALTER TABLE user MODIFY COLUMN age INT UNSIGNED DEFAULT 0 COMMENT ‘年龄’;
-- 删除邮箱字段
ALTER TABLE user DROP COLUMN email;
-- 清空表数据(保留表结构,操作不可逆)
TRUNCATE TABLE user;
特殊说明:
- MySQL 支持多种存储引擎,通过
ENGINE 指定。InnoDB(支持事务、行锁、外键)是核心业务的首选;MyISAM 查询速度快但不支持事务,仅适用于只读场景。
- 字符集推荐使用
utf8mb4,可有效避免中文乱码并支持存储表情符号。
2、数据操作语言(DML):操作数据内容
DML 用于对表中的数据进行增、删、改操作,核心命令是 INSERT、UPDATE、DELETE。使用时需特别注意添加条件和提升操作效率。
-- 插入数据(指定字段插入,即使表结构变更也不易出错)
INSERT INTO user (username, age) VALUES (‘zhangsan’, 25), (‘lisi’, 30);
-- 批量插入(使用UNION ALL,比逐条插入效率高)
INSERT INTO user (username, age)
SELECT ‘wangwu’, 28 UNION ALL SELECT ‘zhaoliu’, 32;
-- 更新数据(务必添加WHERE条件,否则将更新全表!)
UPDATE user SET age = 26 WHERE username = ‘zhangsan’;
-- 多字段同时更新(年龄加1,并同步更新时间)
UPDATE user SET age = age + 1, update_time = NOW() WHERE id > 10;
-- 删除数据(添加WHERE条件,避免误清空全表)
DELETE FROM user WHERE age < 18;
-- 按主键删除(效率最高,因为主键索引可直接定位数据行)
DELETE FROM user WHERE id = 5;
3、数据查询语言(DQL):检索数据
DQL 是日常使用最频繁的语法,核心是 SELECT 语句,能够实现单表查询、多表关联、统计排序等复杂操作。
-- 单表基础查询(指定字段,查询年龄在20到30岁之间的用户)
SELECT id, username, age FROM user WHERE age BETWEEN 20 AND 30;
-- 统计分组(按年龄分组,统计每组人数,仅保留人数大于1的组)
SELECT age, COUNT(*) AS user_count FROM user GROUP BY age HAVING user_count > 1;
-- 多表关联查询(查询用户及其对应的订单信息)
-- 假设已存在存储订单数据的order表
SELECT u.username, o.order_no, o.create_time
FROM user u
INNER JOIN `order` o ON u.id = o.user_id -- 关联条件:用户ID与订单的用户ID匹配
WHERE u.age > 25;
-- 排序分页(按创建时间降序排列,查询第2页数据,每页20条)
-- 小技巧:偏移量 = (页码 - 1) * 每页条数
SELECT * FROM user ORDER BY create_time DESC LIMIT 20, 20;
-- 子查询(查询在2024年1月1日之后下过订单的用户姓名)
SELECT username FROM user WHERE id IN (SELECT user_id FROM `order` WHERE create_time > ‘2024-01-01’);
4、数据控制语言(DCL):权限与事务控制
DCL 主要负责两方面:为用户分配权限(保障数据安全)和控制事务(保障数据一致性),核心命令包括 GRANT、REVOKE、COMMIT、ROLLBACK。
-- 创建用户(允许从任意IP访问,并设置密码)
CREATE USER IF NOT EXISTS ‘test_user’@’%’ IDENTIFIED BY ‘Test@123456’;
-- 授权:授予test_user用户对test_db库所有表的查询、插入权限
GRANT SELECT, INSERT ON test_db.* TO ‘test_user’@’%’;
-- 刷新权限(修改权限后必须执行此命令,否则变更不生效)
FLUSH PRIVILEGES;
-- 回收权限:收回test_user用户的插入权限
REVOKE INSERT ON test_db.* FROM ‘test_user’@’%’;
-- 事务控制(仅InnoDB等支持事务的存储引擎有效)
START TRANSACTION; -- 开启事务
INSERT INTO user (username, age) VALUES (‘qianqi’, 27); -- 操作1:插入用户
UPDATE `order` SET status = 1 WHERE user_id = 6; -- 操作2:更新订单状态
COMMIT; -- 提交事务(所有操作永久生效)
-- ROLLBACK; -- 回滚事务(执行失败时使用,撤销所有未提交的操作)
5、MySQL 语句执行过程详解
无论是执行 DDL、DML 还是 DQL,MySQL 都遵循一套固定的流程:“客户端 → 服务器层 → 存储引擎层 → 客户端”。深入理解这套流程,对于 SQL 优化和问题排查至关重要。下面以最常用的 SELECT 查询为例,详细拆解其执行过程。
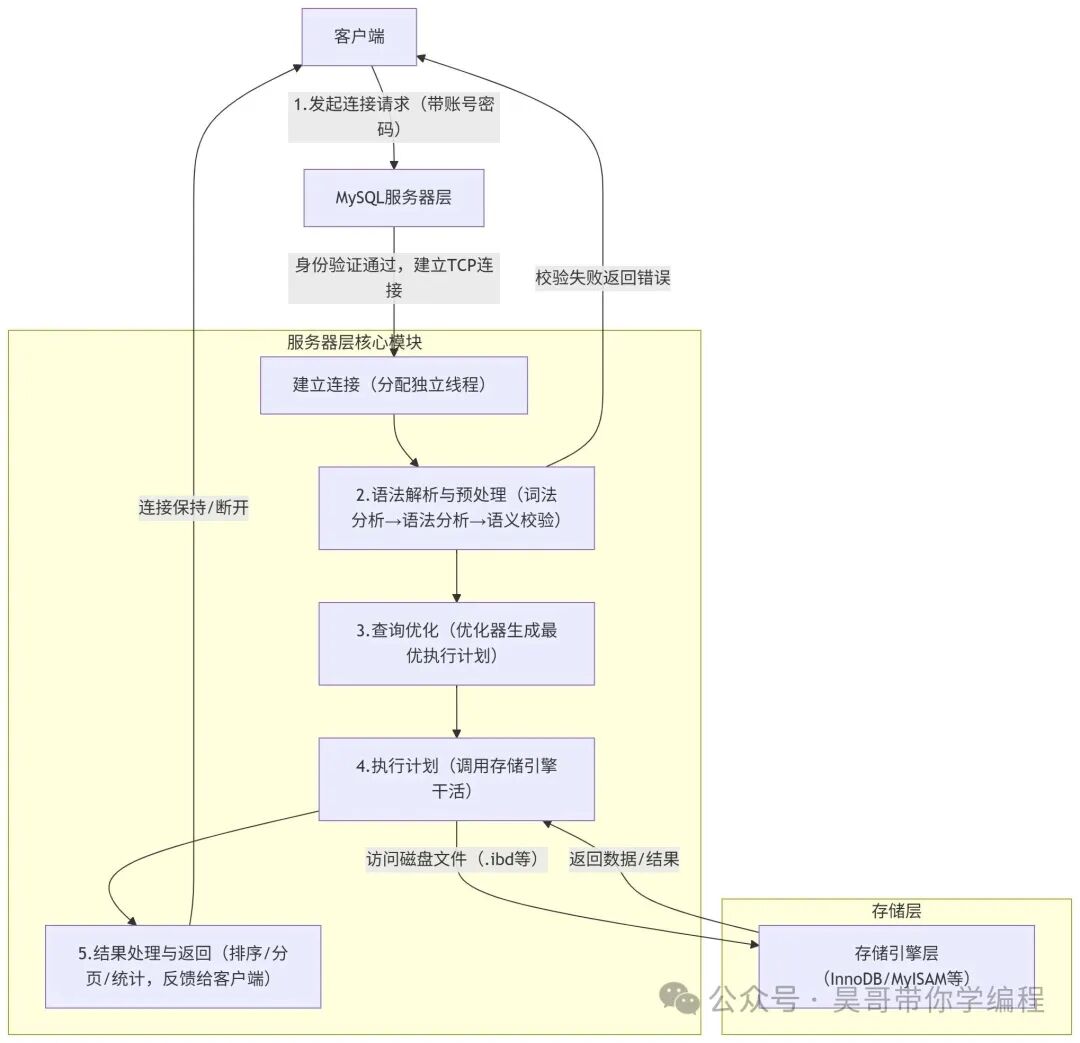
上图清晰地展示了 MySQL 执行语句的全流程,核心包括“建立连接、语法解析、查询优化、执行计划、结果返回”五个步骤,对应着“客户端-服务器层-存储引擎层”的三层架构分工。
1. 建立连接:客户端与服务器“握手”
- 客户端(如命令行工具、Navicat)发起连接请求,提供主机 IP、端口(默认 3306)、用户名和密码。
- 服务器端的
mysqld 进程接收请求,首先验证账号密码和 IP 权限,验证通过则建立 TCP 连接。
- 连接建立后,MySQL 会为该连接分配一个独立的线程,此后该客户端的所有操作均由该线程处理,直到主动断开连接或超时(由
wait_timeout 参数控制,默认 8 小时)。
2. 语法解析与预处理:检查 SQL “合法性”
- 词法分析:将 SQL 字符串拆解成一个个可识别的“单词”(Token),如关键字、表名、字段名。
- 语法分析:检查这些“单词”的排列组合是否符合 SQL 语法规则,例如是否缺少
FROM、括号是否匹配、关键字顺序是否正确。
- 语义校验:语法无误后,进一步检查语义可行性,如表名和字段名是否存在、用户是否有操作权限、函数参数是否合法。
- 以上任何一步出错,服务器都会返回错误信息并停止执行。
3. 查询优化:寻找“最快的执行方式”
- 此步骤由 MySQL 的“查询优化器”负责,其核心目标是生成一个“最省时间、最省资源”的执行计划。
- 优化器的主要工作包括:① 选择索引(判断是否需要使用索引、使用哪个索引,避免全表扫描);② 重写 SQL(例如将子查询转化为 JOIN,调整 WHERE 条件的顺序);③ 选择多表连接顺序(优先连接结果集较小的表,减少匹配次数)。
- 使用
EXPLAIN 命令可以查看优化器选择的执行计划,例如 EXPLAIN SELECT * FROM user WHERE age > 25;,通过分析 type(访问类型)、key(使用的索引)、rows(预估扫描行数)等字段,可以判断 SQL 是否需要优化。
4. 执行计划:调用存储引擎“干活”
- 服务器层根据生成的执行计划,调用对应的存储引擎(如 InnoDB)执行实际的磁盘读写操作。
- 存储引擎负责:按照执行计划的要求,访问磁盘上的数据文件(如 InnoDB 的
.ibd 文件),通过索引定位目标数据,并将其加载到内存后返回给服务器层。
- 对于 INSERT、UPDATE、DELETE 等事务性操作,存储引擎还会同步记录 Undo Log、Redo Log,以确保事务能够正常回滚和恢复。
5. 结果处理与返回:交付最终结果
- 服务器层收到存储引擎返回的原始数据后,会进行后续处理:对于查询,可能包括排序、分页、聚合统计;对于写操作,则统计“影响行数”。
- 处理完毕后,通过 TCP 连接将最终结果返回给客户端。
- 执行完成后,线程保持连接以等待下一条指令;客户端断开连接后,服务器回收该线程资源。
核心要点:MySQL 的“分层架构”(服务器层负责逻辑处理,存储引擎层负责物理存储)是其支持多种存储引擎的基石。大多数慢查询问题的根源在于“未使用索引”或“全表扫描”,使用 EXPLAIN 分析执行计划是快速定位问题的有效手段。
二、MySQL 底层数据存储逻辑
MySQL 的数据存储方式主要由“存储引擎”决定,不同引擎的存储机制差异显著。InnoDB 是当前 MySQL 的默认引擎,也是应用最广泛的引擎(支持事务、行锁、外键),本节将重点解析 InnoDB 的底层存储原理。
1、存储引擎与磁盘文件结构
MySQL 采用“插件式存储引擎”架构,数据库和表都会对应到磁盘上的物理文件。InnoDB 的核心磁盘文件包括:
- .frm 文件:所有存储引擎共有的表结构文件,存储表的字段定义、数据类型、约束、索引等信息。
- .ibd 文件:InnoDB 专属的文件,采用“数据与索引聚集存储”的方式。当参数
innodb_file_per_table=ON(默认)时,每张表对应一个独立的 .ibd 文件,便于管理。
- ibdata1 文件:系统共享表空间文件,存储数据字典、Undo 日志、临时表等系统级数据。如果未开启独立表空间,所有用户表的数据和索引也会存储在此文件中。
- ib_logfile0 / ib_logfile1 文件:Redo Log(重做日志)文件,用于保证事务的持久性。它顺序记录所有的数据修改操作,即使数据库崩溃,重启后也能通过 Redo Log 恢复数据。
2、InnoDB 的核心存储单位:页、区、段、表空间
InnoDB 的存储管理采用分层结构,从最小到最大依次是:页 → 区 → 段 → 表空间。这种设计旨在实现高效存储和易于扩展。
- 页(Page):最小的存储单位,默认大小为 16KB(可通过
innodb_page_size 参数调整)。每个页包含三部分:① 页头(记录页类型、页码、校验和等信息);② 页体(核心部分,存储行数据或索引数据);③ 页尾(存储校验和,用于检测页数据是否损坏)。
- 区(Extent):由 64 个连续的页构成(16KB * 64 = 1MB)。InnoDB 按区为单位分配空间,旨在保证数据存储的物理连续性,提升顺序 I/O 性能。
- 段(Segment):由多个区组成。常见的段有数据段(存储表数据)和索引段(存储索引数据),例如一张表的主键索引对应一个索引段。
- 表空间(Tablespace):最大的存储单位,对应磁盘上的
.ibd 文件(独立表空间模式)。一个表空间内包含了属于该表的所有段,是 InnoDB 存储数据的最终容器。
数据页的行存储格式:在数据页的页体部分,行数据按照特定的格式存储。InnoDB 支持多种行格式(如 COMPACT、DYNAMIC,默认为 DYNAMIC),每行数据主要包含:
- 隐藏列:包括
DB_ROW_ID(当表无主键时自动生成的唯一行ID)、DB_TRX_ID(最近修改该行数据的事务ID)、DB_ROLL_PTR(回滚指针,指向 Undo Log 中记录的历史版本)。
- 用户定义列:即建表时定义的各个字段的数据。对于
VARCHAR 等变长字段,会额外存储长度信息。
- NULL 值列表:使用比特位标记哪些字段的值为 NULL,无需为 NULL 值分配专门的存储空间,节省了存储开销。
3、索引的底层存储:B+树索引结构
索引的核心作用是加速数据检索,其本质是一种排好序的数据结构。InnoDB 使用 B+ 树来实现索引,并且采用了“数据与主键索引存储在一起”的聚簇索引设计,这是其查询性能优异的关键。
(1) 聚簇索引(主键索引)
以主键值作为索引键构建 B+ 树,其叶子节点直接存储完整的行数据(而非数据指针)。InnoDB 表必然拥有一个聚簇索引,创建优先级如下:
- 如果定义了主键,则使用主键作为聚簇索引。
- 如果没有主键,则选择第一个非空的唯一索引。
- 如果以上都没有,InnoDB 会隐式创建一个名为
DB_ROW_ID 的隐藏列作为聚簇索引。
优势:根据主键进行等值或范围查询时,可以直接在 B+ 树的叶子节点找到所需数据,无需二次查找,效率极高。
(2) 二级索引(非主键索引)
以非主键字段(如 age, username)为索引键构建 B+ 树,其叶子节点存储的是该索引键对应的主键值。查询时,需要先通过二级索引找到主键值,再通过主键值到聚簇索引中查找完整的行数据,这个过程称为回表。
如果查询的字段全部包含在某个二级索引中(即索引“覆盖”了查询需求),则无需回表,可显著提升查询速度,这就是覆盖索引。例如,SELECT id, age FROM user WHERE age > 20,如果 age 字段上有二级索引,且该索引叶子节点包含 id 和 age,则可直接返回结果。
性能要点:由于 InnoDB 页大小默认为 16KB,一个 B+ 树索引通常只有 3-4 层深度,却能支撑千万级数据量的高效查询。因为每一层的节点可以存储大量索引键(约1000个),从根节点到叶子节点仅需 3-4 次磁盘 I/O,而磁盘 I/O 正是数据库查询的主要性能瓶颈。
三、MySQL 的 ACID 事务特性深度解析
事务是数据库中一组不可分割的操作单元,用于保证数据的一致性。InnoDB 存储引擎完整支持 ACID(原子性、一致性、隔离性、持久性)特性,这是其能够胜任核心业务的关键。
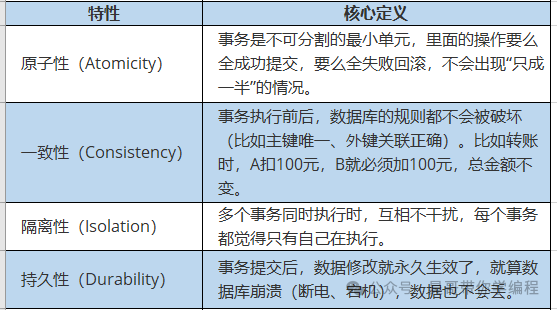
1、ACID 特性定义
2、ACID 特性的实现机制
1. 原子性 (Atomicity):由 Undo Log (回滚日志) 实现。
事务执行过程中,InnoDB 会为每个数据修改操作记录一条“反向操作”日志到 Undo Log。例如:插入记录时,记录删除该记录的日志;更新记录时,记录将数据恢复为旧值的日志。如果事务执行失败或主动执行 ROLLBACK,MySQL 就会利用 Undo Log 执行这些反向操作,将数据恢复到事务开始前的状态,从而保证“要么全部完成,要么全部不做”。
2. 持久性 (Durability):由 Redo Log (重做日志) 实现。
事务提交时,InnoDB 会先将数据修改内容顺序、快速地写入 Redo Log,然后再相对异步地将修改刷写到磁盘数据文件(.ibd)中。这种“先写日志,后写数据”的 WAL (Write-Ahead Logging) 机制保证了持久性。即使数据库在事务提交后、数据页未刷盘前发生崩溃,重启后 MySQL 也可以通过 Redo Log 重放这些修改,确保数据不会丢失。Redo Log 是固定大小的循环写入文件,并通过 Checkpoint 机制定期将已持久化的日志空间回收再利用。
3. 隔离性 (Isolation):由 锁机制 + MVCC (多版本并发控制) 共同实现。
隔离性的目标是解决并发事务执行时的相互干扰问题。InnoDB 采用组合策略:
- 锁机制:主要用于解决“写-写”冲突。InnoDB 支持行级锁和表级锁,默认使用行级锁(基于索引实现)。当多个事务要修改同一行数据时,行锁确保同一时刻只有一个事务能成功修改。
- MVCC:主要用于解决“读-写”冲突。其核心思想是为每一行数据维护多个历史版本,通过隐藏列
DB_TRX_ID(事务ID)和 DB_ROLL_PTR(回滚指针)来关联不同版本。读操作(快照读)可以读取某个时间点的历史版本,而不影响当前的写操作;写操作则生成数据的新版本。MySQL 默认的 REPEATABLE READ 隔离级别正是依靠 MVCC 来实现的。
4. 一致性 (Consistency):由 原子性、隔离性、持久性共同保证。
一致性是事务追求的最终目标,它并非由单一机制实现,而是原子性(避免部分操作)、隔离性(避免并发干扰)、持久性(避免数据丢失)三者协同作用的结果,再结合数据库自身的约束(如外键、唯一索引)和业务逻辑的校验,最终确保数据从一个一致状态转换到另一个一致状态。
3、事务隔离级别详解
事务隔离级别定义了并发事务之间数据的可见性规则,是隔离性在具体程度上的体现。MySQL 支持四种标准隔离级别,在数据一致性和并发性能之间进行权衡,默认级别为 Repeatable Read (可重复读)。
(1) Read Uncommitted (读未提交)
- 定义:一个事务可以读取到其他事务尚未提交的修改。
- 问题:存在脏读风险(读取到最终可能被回滚的无效数据)。
- 并发性能:最高(几乎不加读锁)。
- 适用场景:对数据准确性要求极低的临时性查询,如实时监控仪表盘(允许瞬时数据误差)。
(2) Read Committed (读已提交)
- 定义:一个事务只能读取到其他事务已经提交的修改。
- 改进:解决了脏读问题。
- 问题:存在不可重复读问题(同一事务内两次读取同一数据,结果可能因其他事务提交而不同)。
- 并发性能:较高。
- 适用场景:对一致性有基本要求,但可接受非重复读的业务,如电商商品详情查看、普通订单查询。
(3) Repeatable Read (可重复读,MySQL默认)
- 定义:同一事务内多次读取同一数据,结果总是一致的,不受其他已提交事务的影响(通过 MVCC 实现)。
- 改进:解决了脏读和不可重复读问题。
- 问题:理论上存在幻读(同一事务内多次执行相同范围的查询,返回的记录行数可能不同),但 InnoDB 通过 Next-Key Lock (间隙锁) 机制在绝大部分场景下解决了幻读。
- 并发性能:中等,在一致性和性能间取得了良好平衡。
- 适用场景:绝大多数核心业务场景,如金融转账、订单创建、用户账户管理。
(4) Serializable (串行化)
- 定义:最高的隔离级别,强制所有事务串行执行,完全杜绝并发冲突。
- 改进:解决了所有并发问题(脏读、不可重复读、幻读)。
- 问题:并发性能最低(事务排队执行,易发生锁等待和超时)。
- 适用场景:对数据准确性要求极端严格,不容许任何不一致的场景,如金融清算系统、政府财务报表统计。
四种隔离级别核心对比

查看和修改事务隔离级别的 SQL 命令(通常需要管理员权限)
-- 查看当前会话的事务隔离级别
SELECT @@session.transaction_isolation;
-- 查看全局的事务隔离级别
SELECT @@global.transaction_isolation;
-- 设置当前会话的隔离级别(示例:设为读已提交)
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 设置全局的隔离级别(示例:设为可重复读)
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
四、MySQL 实践核心注意事项
1、索引优化:平衡查询与写入性能
- 避免过度索引:索引加速查询,但会增加 INSERT、UPDATE、DELETE 操作的开销(需维护索引)。应在查询频率和写频率之间权衡。
- 精准创建索引:优先为高频出现在 WHERE 条件、JOIN 关联字段、ORDER BY / GROUP BY 子句中的字段创建索引。
- 警惕索引失效:避免在索引字段上使用函数、表达式,或进行以
% 开头的 LIKE 模糊查询、!=、NOT IN 等操作。
- 善用覆盖索引:尽量让查询的字段都包含在某个索引中,避免回表查询,可大幅提升性能。
2、事务使用:避免长事务,减少锁冲突
- 核心业务务必使用事务:确保数据操作的原子性和一致性。
- 警惕长事务:长时间运行的事务会持续占有锁资源,可能导致其他事务阻塞甚至死锁。应尽量将业务逻辑拆分为短小的事务。
- 选择合适的隔离级别:在保证业务一致性的前提下,非核心业务可考虑使用
READ COMMITTED 以提升并发能力;核心业务使用默认的 REPEATABLE READ 通常已足够。
3、性能调优:配置参数与 SQL 优化并重
- 关键参数调整:
innodb_buffer_pool_size:InnoDB 缓冲池大小,建议设置为物理内存的 50%-70%,用于缓存数据和索引,是减少磁盘 I/O 最重要的参数。max_connections:根据业务实际并发量调整最大连接数,避免出现“Too many connections”错误。
- 杜绝全表扫描:养成使用
EXPLAIN 分析 SQL 执行计划的习惯,确保查询有效利用了索引。
- 优先批量操作:使用批量 INSERT / UPDATE 替代循环单条操作,可显著减少网络交互和事务提交开销。
4、数据安全:定期备份与权限管控
- 定期备份:使用
mysqldump 进行逻辑备份,或利用 MySQL Enterprise Backup、Percona XtraBackup 等工具进行物理热备份,建立全量+增量的备份策略。
- 开启二进制日志 (binlog):binlog 记录了所有数据更改操作,是进行数据恢复、主从复制的基石。
- 遵循最小权限原则:为应用程序或用户分配其完成工作所必需的最小数据库权限,例如只授予 SELECT 和 INSERT 权限,杜绝安全隐患。
理解 MySQL 的语法、存储引擎的底层逻辑以及ACID事务的实现机制,是进行高效数据库设计和性能优化的基础。希望本文能帮助你构建起系统的 MySQL 知识体系。技术精进之路,贵在持续实践与思考,欢迎在云栈社区持续探索更多后端与数据库技术深度内容。
 发表于 2026-1-17 10:14:32
|
查看: 262|
回复: 0
发表于 2026-1-17 10:14:32
|
查看: 262|
回复: 0
