微软开发的GraphRAG是早期成熟的GraphRAG系统之一,它将索引阶段(实体抽取、关系构建、层级社区生成与摘要)与查询阶段的高级能力进行了深度整合。该方案的优势在于能够借助预计算的实体、关系和社区摘要来回答宏观性、主题类问题,这正是传统RAG系统基于文档检索难以实现的。
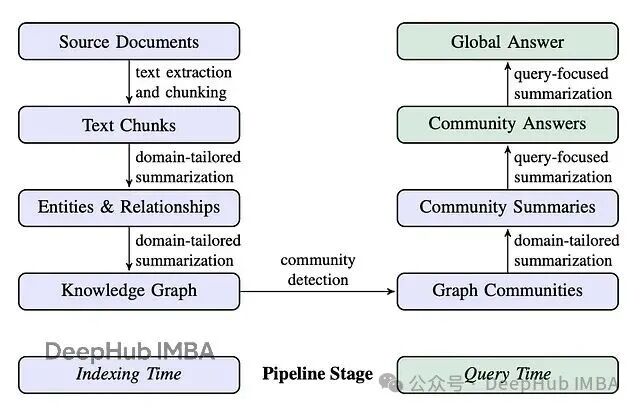
本文重点探讨DRIFT搜索(Dynamic Reasoning and Inference with Flexible Traversal),即"动态推理与灵活遍历"。这是一种兼具全局搜索和局部搜索特点的新型检索策略。
DRIFT的工作流程首先通过向量搜索建立宽泛的查询起点,再利用社区信息将原始问题拆解为细粒度后续查询。随后在知识图谱中动态遍历,抓取实体、关系等局部细节。这种设计在计算效率和答案质量之间取得了良好平衡。
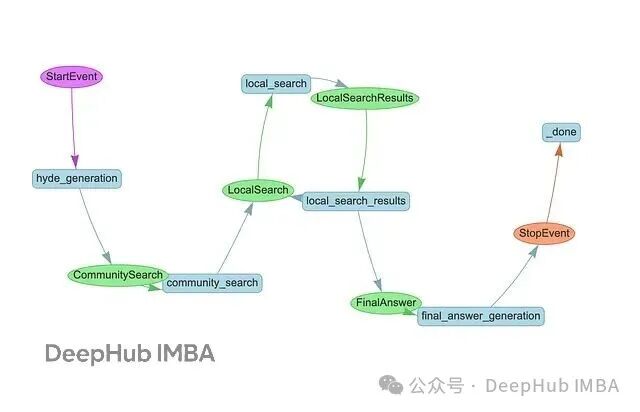
上图展示了使用LlamaIndex工作流和Neo4j实现的DRIFT搜索,核心流程分为以下几个步骤:
首先进行HyDE生成,基于样例社区报告构造假设性答案,以改善查询的向量表示。
接着执行社区搜索,通过向量相似度找出最相关的社区报告,为查询提供宏观上下文。系统会分析这些结果,输出初步中间答案,同时生成一批用于深度挖掘的后续查询。
这些后续查询在局部搜索阶段并行执行,从知识图谱中提取文本块、实体、关系以及更多社区报告。该过程可迭代多轮,每轮都可能产生新的后续查询。
最后进行答案生成,将过程中积累的所有中间答案汇总,融合社区级宏观洞察和局部细节,生成最终响应。整体思路遵循先展开后聚焦的递进策略。
本文以《爱丽丝梦游仙境》为例,这部刘易斯·卡罗尔的经典作品角色丰富、场景复杂、事件环环相扣,非常适合演示GraphRAG的实际能力。
数据导入
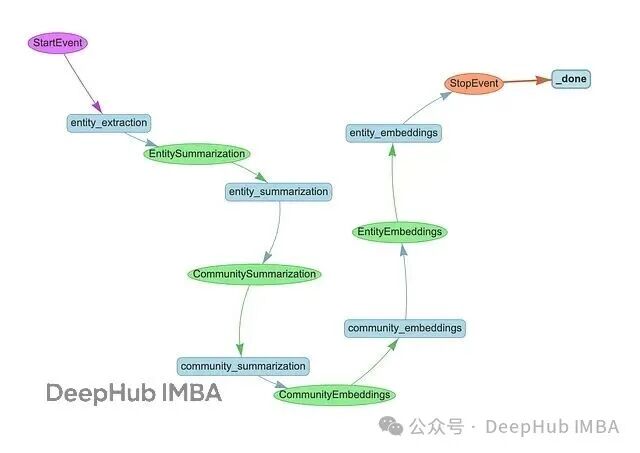
整个pipeline遵循标准GraphRAG流程,包含三个阶段:
class MSGraphRAGIngestion(Workflow):
@step
async def entity_extraction(self, ev: StartEvent) -> EntitySummarization:
chunks = splitter.split_text(ev.text)
await ms_graph.extract_nodes_and_rels(chunks, ev.allowed_entities)
return EntitySummarization()
@step
async def entity_summarization(
self, ev: EntitySummarization
) -> CommunitySummarization:
await ms_graph.summarize_nodes_and_rels()
return CommunitySummarization()
@step
async def community_summarization(
self, ev: CommunitySummarization
) -> CommunityEmbeddings:
await ms_graph.summarize_communities()
return CommunityEmbeddings()
首先从文本块中抽取实体和关系,接着为节点和关系生成摘要,最后构建层级社区并生成社区摘要。
完成摘要后,需要为社区和实体生成向量嵌入以支持相似性检索。社区嵌入的实现代码如下:
@step
async def community_embeddings(self, ev: CommunityEmbeddings) -> EntityEmbeddings:
# 从图数据库获取所有社区
communities = ms_graph.query(
"""
MATCH (c:__Community__)
WHERE c.summary IS NOT NULL AND c.rating > $min_community_rating
RETURN coalesce(c.title, "") + " " + c.summary AS community_description, c.id AS community_id
""",
params={"min_community_rating": MIN_COMMUNITY_RATING},
)
if communities:
# 基于社区描述生成向量嵌入
response = await client.embeddings.create(
input=[c["community_description"] for c in communities],
model=TEXT_EMBEDDING_MODEL,
)
# 将嵌入存储至图数据库并创建向量索引
embeds = [
{
"community_id": community["community_id"],
"embedding": embedding.embedding,
}
for community, embedding in zip(communities, response.data)
]
ms_graph.query(
"""UNWIND $data as row
MATCH (c:__Community__ {id: row.community_id})
CALL db.create.setNodeVectorProperty(c, 'embedding', row.embedding)""",
params={"data": embeds},
)
ms_graph.query(
"CREATE VECTOR INDEX community IF NOT EXISTS FOR (c:__Community__) ON c.embedding"
)
return EntityEmbeddings()
实体嵌入采用类似方法实现,至此DRIFT搜索所需的向量索引已全部建立完成。
DRIFT搜索
DRIFT的检索逻辑符合直觉:先把握整体再深入细节。它不会直接在文档或实体层面进行精确匹配,而是先查询社区摘要,这些摘要提供了知识图谱主要主题的高层次概括。
获取相关高层信息后,DRIFT会智能派生出后续查询,精确检索特定实体、关系和源文档。这种两阶段方法模拟了人类查阅资料的习惯:先建立整体认知再针对性追问细节。既具备全局搜索的覆盖范围,又保持局部搜索的精准度,同时避免了遍历所有社区报告或文档的计算开销。
下面详细解析各阶段的实现细节。
社区搜索
DRIFT采用HyDE技术提升向量检索准确率。不是直接对用户查询进行嵌入,而是先让模型生成假设答案,再用该答案进行相似性搜索。其原理在于假设答案在语义上更接近真实摘要。
@step
async def hyde_generation(self, ev: StartEvent) -> CommunitySearch:
# 获取随机社区报告作为HyDE生成模板
random_community_report = driver.execute_query(
"""
MATCH (c:__Community__)
WHERE c.summary IS NOT NULL
RETURN coalesce(c.title, "") + " " + c.summary AS community_description""",
result_transformer_=lambda r: r.data(),
)
# 生成假设答案以改进查询表示
hyde = HYDE_PROMPT.format(
query=ev.query, template=random_community_report[0]["community_description"]
)
hyde_response = await client.responses.create(
model="gpt-5-mini",
input=[{"role": "user", "content": hyde}],
reasoning={"effort": "low"},
)
return CommunitySearch(query=ev.query, hyde_query=hyde_response.output_text)
获得HyDE查询后,进行嵌入处理,通过向量相似度检索前5个报告。随后让LLM基于这些报告生成初步答案,同时识别需要深入挖掘的后续查询。存储初步答案后将所有后续查询并行分发至局部搜索阶段。
@step
async def community_search(self, ctx: Context, ev: CommunitySearch) -> LocalSearch:
# 基于HyDE增强查询创建嵌入
embedding_response = await client.embeddings.create(
input=ev.hyde_query, model=TEXT_EMBEDDING_MODEL
)
embedding = embedding_response.data[0].embedding
# 通过向量相似度查找前5个最相关社区报告
community_reports = driver.execute_query(
"""
CALL db.index.vector.queryNodes('community', 5, $embedding) YIELD node, score
RETURN 'community-' + node.id AS source_id, node.summary AS community_summary
""",
result_transformer_=lambda r: r.data(),
embedding=embedding,
)
# 生成初始答案并识别需要补充的信息
initial_prompt = DRIFT_PRIMER_PROMPT.format(
query=ev.query, community_reports=community_reports
)
initial_response = await client.responses.create(
model="gpt-5-mini",
input=[{"role": "user", "content": initial_prompt}],
reasoning={"effort": "low"},
)
response_json = json_repair.loads(initial_response.output_text)
print(f"Initial intermediate response: {response_json['intermediate_answer']}")
# 存储初始答案并为并行局部搜索做准备
async with ctx.store.edit_state() as ctx_state:
ctx_state["intermediate_answers"] = [
{
"intermediate_answer": response_json["intermediate_answer"],
"score": response_json["score"],
}
]
ctx_state["local_search_num"] = len(response_json["follow_up_queries"])
# 分发后续查询并行执行
for local_query in response_json["follow_up_queries"]:
ctx.send_event(LocalSearch(query=ev.query, local_query=local_query))
return None
这就是DRIFT的核心思路:首先通过HyDE增强的社区搜索展开全局视野,再通过后续查询逐层深入。
局部搜索
局部搜索阶段并行执行后续查询,深入挖掘具体细节。每个查询通过实体向量检索获取目标上下文,生成中间答案,并可能产生更多后续查询。
@step(num_workers=5)
async def local_search(self, ev: LocalSearch) -> LocalSearchResults:
print(f"Running local query: {ev.local_query}")
# 为局部查询创建嵌入
response = await client.embeddings.create(
input=ev.local_query, model=TEXT_EMBEDDING_MODEL
)
embedding = response.data[0].embedding
# 检索相关实体并收集关联上下文:
# - 提及实体的文本块
# - 实体所属的社区报告
# - 检索实体间的关系
# - 实体描述
local_reports = driver.execute_query(
"""
CALL db.index.vector.queryNodes('entity', 5, $embedding) YIELD node, score
WITH collect(node) AS nodes
WITH
collect {
UNWIND nodes as n
MATCH (n)<-[:MENTIONS]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN {chunkText: c.text, source_id: 'chunk-' + c.id}
ORDER BY freq DESC
LIMIT 3
} AS text_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY*]->(c:__Community__)
WHERE c.summary IS NOT NULL
WITH c, c.rating as rank
RETURN {summary: c.summary, source_id: 'community-' + c.id}
ORDER BY rank DESC
LIMIT 3
} AS report_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[r:SUMMARIZED_RELATIONSHIP]-(m)
WHERE m IN nodes
RETURN {descriptionText: r.summary, source_id: 'relationship-' + n.name + '-' + m.name}
LIMIT 3
} as insideRels,
collect {
UNWIND nodes as n
RETURN {descriptionText: n.summary, source_id: 'node-' + n.name}
} as entities
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: insideRels,
Entities: entities} AS output
""",
result_transformer_=lambda r: r.data(),
embedding=embedding,
)
# 基于检索上下文生成答案
local_prompt = DRIFT_LOCAL_SYSTEM_PROMPT.format(
response_type=DEFAULT_RESPONSE_TYPE,
context_data=local_reports,
global_query=ev.query,
)
local_response = await client.responses.create(
model="gpt-5-mini",
input=[{"role": "user", "content": local_prompt}],
reasoning={"effort": "low"},
)
response_json = json_repair.loads(local_response.output_text)
# 限制后续查询数量防止指数级增长
response_json["follow_up_queries"] = response_json["follow_up_queries"][:LOCAL_TOP_K]
return LocalSearchResults(results=response_json, query=ev.query)
下一步负责编排迭代深化过程。使用collect_events等待所有并行搜索完成,然后判断是否需要继续深入。如果当前深度未达上限(设置max depth=2),则提取所有结果中的后续查询,存储中间答案并分发下一轮并行搜索。
@step
async def local_search_results(
self, ctx: Context, ev: LocalSearchResults
) -> LocalSearch | FinalAnswer:
local_search_num = await ctx.store.get("local_search_num")
# 等待所有并行搜索完成
results = ctx.collect_events(ev, [LocalSearchResults] * local_search_num)
if results is None:
return None
intermediate_results = [
{
"intermediate_answer": event.results["response"],
"score": event.results["score"],
}
for event in results
]
current_depth = await ctx.store.get("local_search_depth", default=1)
query = [ev.query for ev in results][0]
# 若未达到最大深度则继续深入
if current_depth < MAX_LOCAL_SEARCH_DEPTH:
await ctx.store.set("local_search_depth", current_depth + 1)
follow_up_queries = [
query
for event in results
for query in event.results["follow_up_queries"]
]
# 存储中间答案并分发下一轮搜索
async with ctx.store.edit_state() as ctx_state:
ctx_state["intermediate_answers"].extend(intermediate_results)
ctx_state["local_search_num"] = len(follow_up_queries)
for local_query in follow_up_queries:
ctx.send_event(LocalSearch(query=query, local_query=local_query))
return None
else:
return FinalAnswer(query=query)
这样就形成了迭代细化的循环,每一层都在前一层基础上继续深入。达到最大深度后,触发最终答案生成。
最终答案
最后一步将DRIFT搜索过程中积累的所有中间答案汇总成完整响应:包括社区搜索的初步答案和局部搜索各轮迭代产生的答案。
@step
async def final_answer_generation(self, ctx: Context, ev: FinalAnswer) -> StopEvent:
# 获取搜索过程中收集的所有中间答案
intermediate_answers = await ctx.store.get("intermediate_answers")
# 将所有发现合成为完整的最终响应
answer_prompt = DRIFT_REDUCE_PROMPT.format(
response_type=DEFAULT_RESPONSE_TYPE,
context_data=intermediate_answers,
global_query=ev.query,
)
answer_response = await client.responses.create(
model="gpt-5-mini",
input=[
{"role": "developer", "content": answer_prompt},
{"role": "user", "content": ev.query},
],
reasoning={"effort": "low"},
)
return StopEvent(result=answer_response.output_text)
总结
DRIFT搜索提供了一种在全局搜索广度和局部搜索精度之间取得平衡的创新思路。从社区级上下文切入,通过迭代式后续查询逐层深入,既避免了遍历所有社区报告的计算负担,又确保了信息覆盖的完整性。
现有实现仍存在优化空间,例如当前对所有中间答案采用同等权重处理,如果能够基于置信度分数进行筛选,将有效提升最终答案质量并降低噪声干扰。后续查询也可按相关性或信息增益排序,优先追踪最具价值的线索。
另一个值得尝试的改进方向是加入查询精炼步骤,利用LLM分析所有生成的后续查询,合并相似查询避免重复搜索,过滤可能收益较低的查询。这样能显著减少局部搜索次数,同时保持答案质量。
完整代码参考:
https://github.com/neo4j-contrib/ms-graphrag-neo4j/blob/main/examples/drift_search.ipynb
感兴趣的用户可以自行运行实验,或在此基础框架上进行进一步优化改进。
 发表于 2025-11-29 04:29:19
|
查看: 213|
回复: 0
发表于 2025-11-29 04:29:19
|
查看: 213|
回复: 0
