一、为什么要做日志存储优化?
在当今微服务和分布式架构中,日志数据已成为运维和开发团队不可或缺的核心资产:
- 实时性:支撑问题排查、监控告警和性能分析
- 合规性:金融、医疗等行业要求长期留存日志记录
- 数据量级:日均TB级别的日志产生已成为常态
随着业务规模扩大,传统集中式存储面临三大挑战:
- 存储成本激增:全量数据存储在SSD或Elasticsearch热节点,成本难以控制
- 查询性能下降:海量日志导致检索延迟,写入阻塞频发
- 运维复杂度高:索引膨胀、分片过多、备份耗时等问题凸显
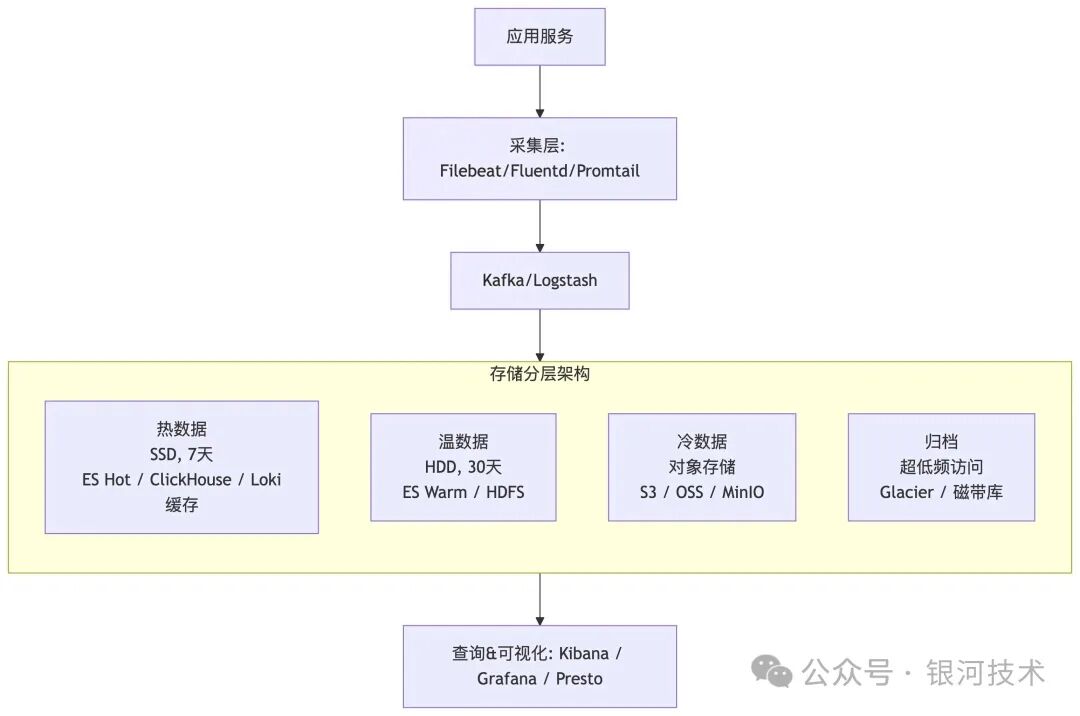
核心解决方案:冷热分离架构
- 热数据层:最近7天高频访问数据,采用SSD或ES热节点存储
- 温数据层:近30天偶尔查询数据,部署在HDD或ES温节点
- 冷数据层:历史归档数据,存储于S3/OSS/MinIO等低成本对象存储
- 归档数据层:合规性保留数据,采用Glacier或磁带极低成本方案
二、核心架构模式
1. ELK Stack(冷热分离经典方案)
作为业界成熟方案,ELK Stack通过分层存储实现成本与性能的平衡:
- 热节点:SSD存储,保障实时日志处理性能
- 温节点:HDD存储,承载只读历史日志
- 冷存储:基于S3/OSS的Snapshot和ILM管理机制
- 查询界面:Kibana提供全文检索与多维聚合能力
ILM策略配置示例(Elasticsearch)
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": { "max_age": "7d", "max_size": "50gb" }
}
},
"warm": {
"min_age": "7d",
"actions": {
"allocate": { "require": { "box_type": "warm" } },
"forcemerge": { "max_num_segments": 1 }
}
},
"cold": {
"min_age": "30d",
"actions": {
"searchable_snapshot": { "snapshot_repository": "s3-repo" }
}
},
"delete": {
"min_age": "180d",
"actions": { "delete": {} }
}
}
}
}
2. Grafana Loki(云原生低成本方案)
专为云原生环境设计的轻量级方案,天然契合Kubernetes生态:
- 采集组件:Promtail负责日志收集和标签标注
- 处理引擎:Loki仅索引元数据,原始日志直存对象存储
- 存储架构:
- 热数据:SSD缓存配合boltdb-shipper
- 冷数据:S3/OSS/MinIO对象存储
- 查询接口:Grafana集成LogQL查询语言
方案优势:
- 成本效益突出:存储重心转移至对象存储,大幅降低开支
- 架构简洁:内置冷热分离机制,近数据快速响应,远数据按需加载
- 云原生集成:与容器编排平台无缝对接,部署维护简便
3. Kafka + ClickHouse + HDFS(大规模分析架构)
面向海量日志分析场景的高性能解决方案:
- 数据管道:Kafka构建高吞吐日志总线
- 热数据存储:ClickHouse存储7-30天数据,提供亚秒级查询
- 冷数据仓库:HDFS/OSS承载历史数据,支持Spark/Presto分析
适用场景:用户行为分析、业务智能报表等需要复杂聚合计算的场景
三、架构全景示意
四、实施路线图
- 生命周期规划:明确热/温/冷数据保留策略(如7/30/180天周期)
- 采集层部署:
- ELK生态:Filebeat + Kafka + Logstash组合
- Loki体系:Promtail + boltdb-shipper配置
- 存储分层实施:
- Elasticsearch:部署hot/warm节点集群,配置ILM策略
- Loki:设定对象存储后端,规范标签体系
- ClickHouse:建立日期分区表,启用TTL自动清理
- 归档机制建立:制定定期快照转储计划,清理过期索引
- 查询层优化:
- 热数据查询直连SSD节点保障性能
- 冷数据查询添加延迟提示,管理用户预期
- 运维自动化:通过定时任务和生命周期策略减少人工干预
五、最佳实践指南
- 日志规范化:采用JSON结构化输出,提升索引解析效率
- 标签精细化管理:
- ES场景:精选关键字段设为keyword类型
- Loki环境:规避高基数标签(如用户ID)
- 压缩策略优化:
- 热数据:LZ4算法平衡性能与空间
- 冷数据:ZSTD/GZIP最大化存储效率
- 分区策略设计:按时间维度(天/周)划分索引,配置自动TTL
- 查询体验优化:界面明确标识数据层级,设置历史查询延迟提醒
- 系统健康监控:持续追踪写入吞吐、查询延迟、磁盘使用率关键指标
六、方案对比分析
| 方案 |
成本控制 |
查询能力 |
运维复杂度 |
典型应用场景 |
| ELK Stack |
较高 |
全面强大(全文检索、聚合分析) |
高 |
企业级复杂日志分析 |
| Loki |
优秀 |
中等(标签检索) |
低 |
云原生环境、成本敏感项目 |
| ClickHouse |
中等 |
极速(聚合计算) |
中等 |
海量日志分析、行为追踪 |
| 商业方案 |
最高 |
全面 |
最低 |
预算充足、追求效率团队 |
七、架构演进总结
- 核心价值:通过高性能存储处理热数据,低成本方案保存冷数据,实现全生命周期自动化管理
- 选型建议:
- 搜索分析需求优先:ELK Stack生态
- 成本与云原生考量:Loki方案
- 聚合分析性能要求:ClickHouse组合架构
- 实施关键:周期规划科学化、存储分层精细化、压缩策略最优化、查询体验分层化
架构演进精髓:
日志存储优化 = 热数据高性能保障 + 冷数据低成本存储 + 全周期自动化管理 |  发表于 2025-11-29 04:25:10
|
查看: 191|
回复: 0
发表于 2025-11-29 04:25:10
|
查看: 191|
回复: 0
