当大模型秒回复杂问题、Stable Diffusion 生成逼真图像时,你或许会好奇:支撑这些黑科技的“幕后英雄”到底长什么样?答案藏在 AI 基础设施的核心——服务器节点中。
它们绝非普通的铁盒子,而是藏着大模型高效运行的关键密码。通用服务器与 AI 服务器的差异,更是直接决定了技术落地的性能上限。
一、服务器为何要做成“长条形”?
打开机房机柜,你会发现服务器清一色是“拉长款”,这绝非设计巧合,而是多重物理与工程需求的必然选择:
- 散热刚需:高功率密度芯片运行时会产生大量热量,长条形态能优化风道设计,让冷空气顺畅贯穿整个设备,避免硬件因过热而宕机。
- 扩展自由:更长的机身可以容纳更多的硬盘位和扩展接口,以满足海量数据存储与多设备高速连接的需求,轻松应对业务扩容。
- 布局科学:合理的内部空间有助于分配 CPU、内存、电源等核心部件的位置,减少信号干扰,同时也能更好地兼容不同规格的硬件配件。
- 运维便捷:集中式、标准化的布局让运维工程师无需拆卸过多部件就能进行检修,显著降低了维护成本与系统停机时间。
二、通用服务器:全能型“多面手”
通用服务器就像 IT 世界的“万金油”,其中 1U 2 路机架式是最常见的形态。它凭借均衡的综合性能,适配各类传统企业场景,是支撑数据中心稳定运行的基础单元。

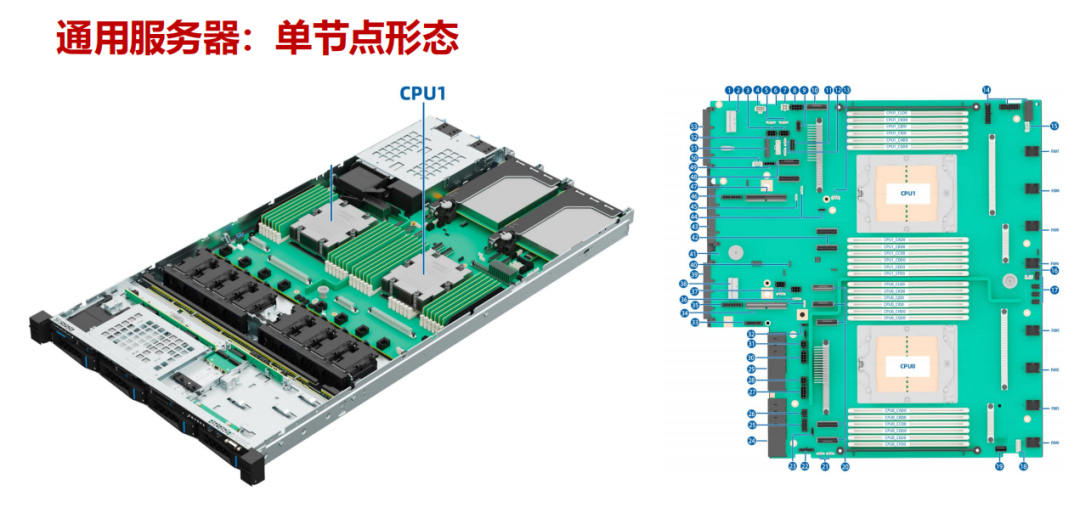
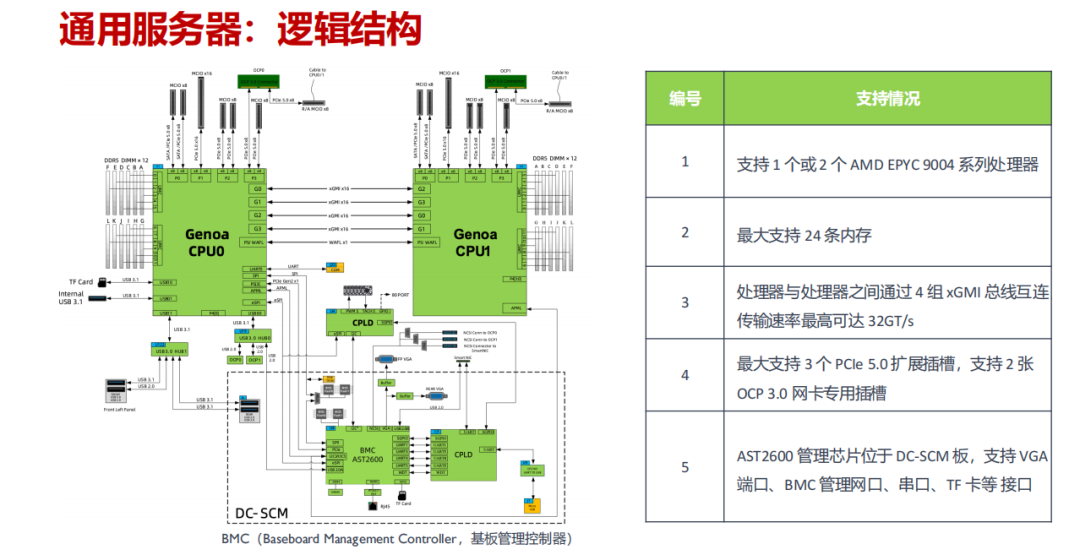
- 硬件配置:通常支持 1-2 个 AMD EPYC 9004 系列处理器,最大可扩展 24 条内存,并提供多种硬盘组合(如 4×3.5 英寸 + 2×E1.S + 2×M.2),在计算、存储与网络能力上取得平衡。
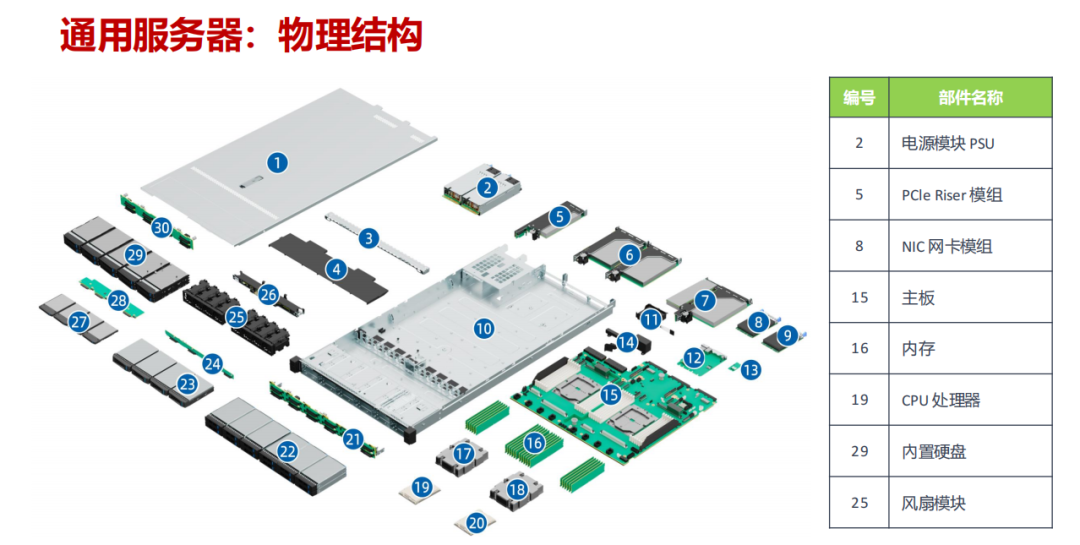
- 核心部件:主要由电源模块、主板、CPU、内存、网卡模组等组成,处理器之间通过 4 组 xGMI 总线实现高达 32GT/s 的高速互连。
- 典型应用:企业官网、办公自动化系统、小型数据库管理等。凡是不需要大规模并行计算的传统 IT 业务,都能看到它的身影。

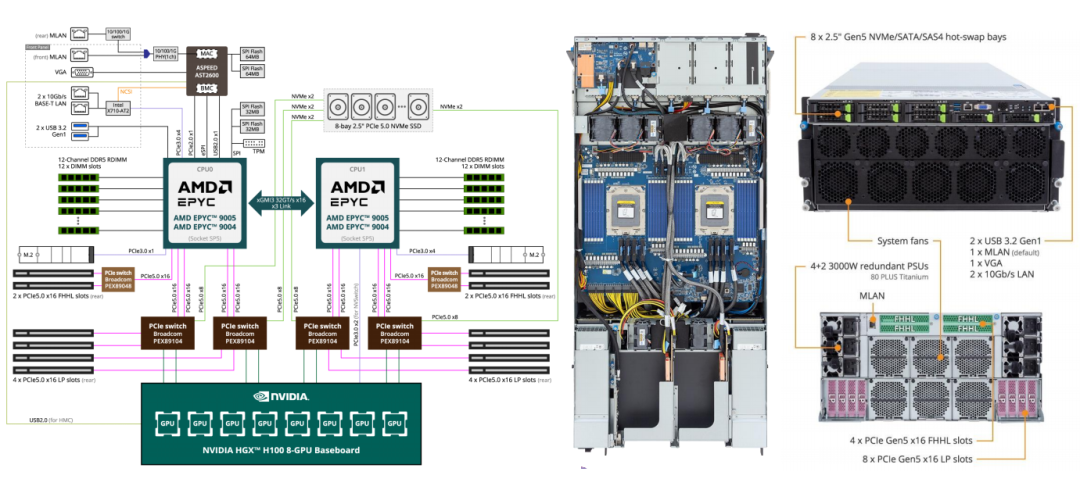
三、AI 服务器:专为大模型而生的“性能猛兽”
如果说通用服务器是“多面手”,那么 AI 服务器就是专攻异构计算的“特种兵”。它采用 CPU + GPU/NPU 的架构,堪称大模型训练与推理的“专属座驾”。
1. GPU 型 AI 服务器(以 NVIDIA HGX H100 为例)



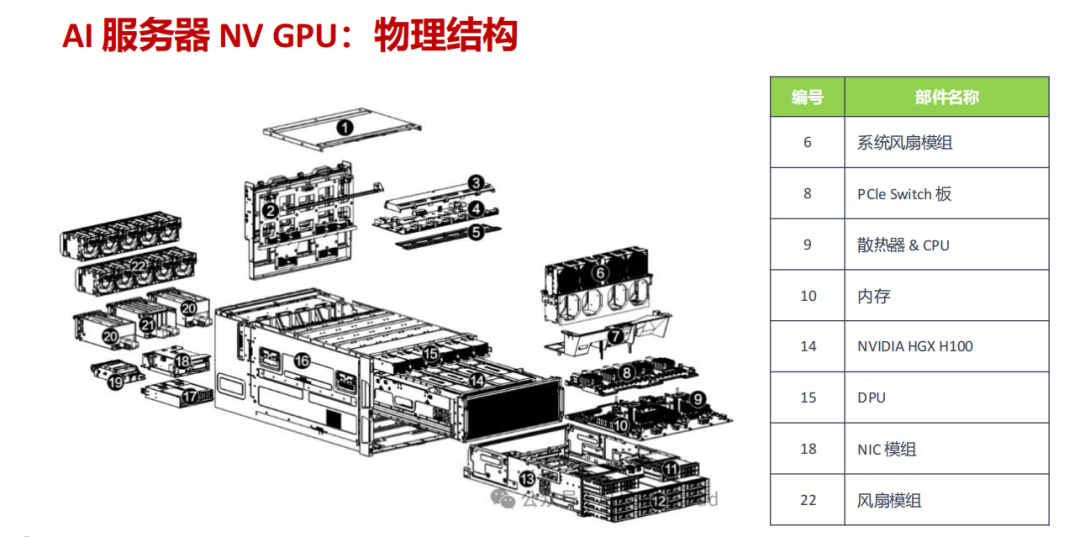
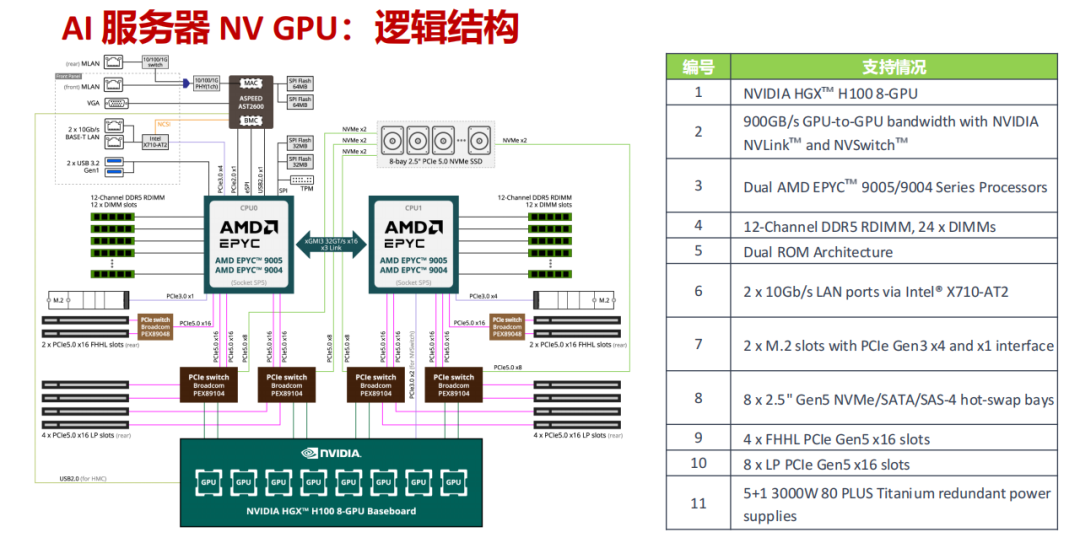

- 硬核配置:搭载双路 AMD EPYC 9005/9004 处理器和 8 块 NVIDIA HGX H100 GPU,提供 24 条 DDR5 内存插槽和 8 个 Gen5 NVMe 热插拔硬盘位,并配备 5+1 冗余钛金电源保障极端负载下的稳定运行。
- 性能亮点:通过 NVLink 和 NVSwitch 实现高达 900GB/s 的 GPU 间互联带宽,再结合 PCIe 5.0 插槽,使数据在CPU、GPU和存储间的传输速度呈指数级提升。
- 适用场景:大规模语言模型训练、自动驾驶算法迭代、多模态内容生成等对算力和并行计算要求极高的前沿领域。
2. NPU 型 AI 服务器(以华为 Atlas 800T A2 为例)


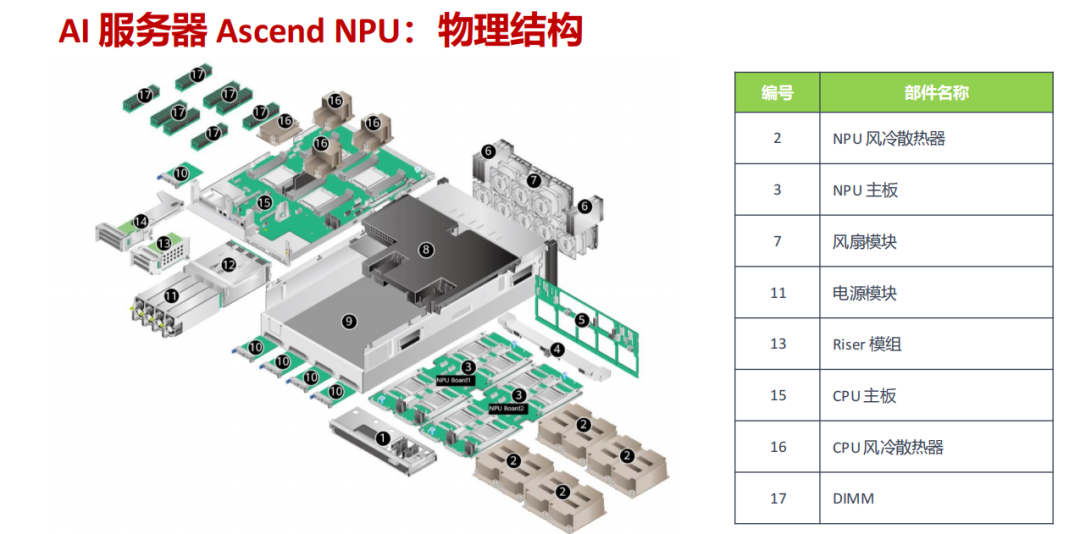
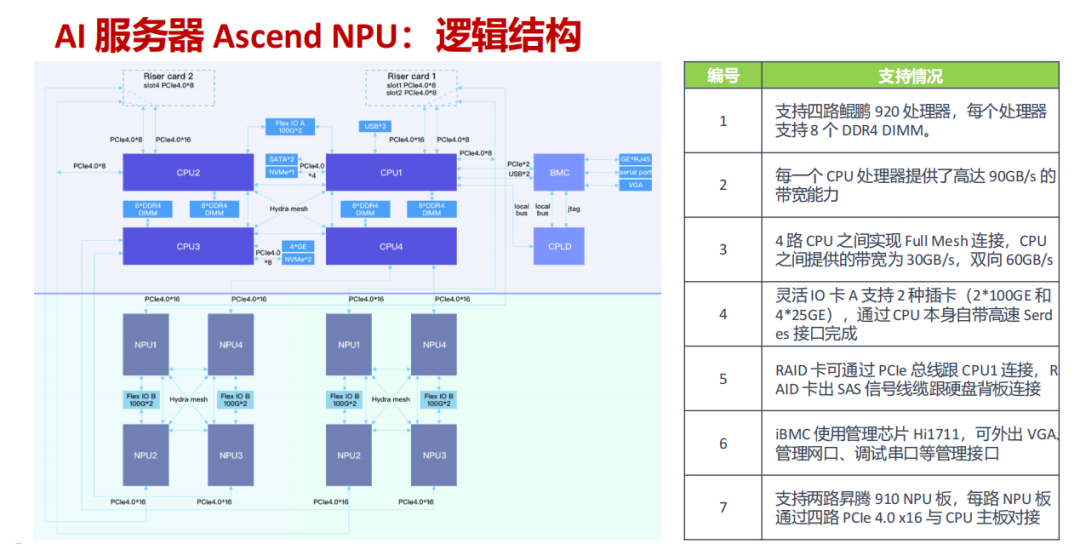
- 特色架构:支持 4 路鲲鹏 920 处理器,每路搭配 8 个 DDR4 内存插槽。两路昇腾 910 NPU 板通过 PCIe 4.0 x16 接口与 CPU 主板对接,CPU 之间通过 Full Mesh 全互联实现高达双向 60GB/s 的带宽。
- 核心优势:强调软硬件协同优化,针对中文场景和 AI 推理任务做了专项适配,在特定应用场景下展现出优秀的性价比与兼容性。
- 典型应用:工业大模型在线推理、智能客服、智慧城市实时数据处理等场景。
四、关键差异对比:一张表看懂核心区别

| 对比维度 |
通用服务器 |
AI 服务器 |
| 核心架构 |
以同构的 CPU 为主 |
CPU + GPU/NPU 异构架构 |
| 计算能力 |
擅长串行计算,综合能力均衡 |
专注并行计算,单精度/混合精度算力强悍 |
| 扩展重点 |
存储容量、网络接口扩展 |
GPU/NPU 加速卡数量、高带宽内存扩展 |
| 电源与功耗 |
常规功耗,无需特殊供电设计 |
极高功耗(如采用 3000W 冗余电源),需专项供电与散热方案 |
| 适用场景 |
传统 IT 业务、Web 服务、小型数据处理 |
大模型训练 / 推理、AI 算法开发、科学计算 |
五、散热与集群:AI 服务器的“隐形保障”
AI 服务器的高性能背后,离不开创新性的散热与大规模集群技术的强力支撑:
- 散热方案:除了强力的系统风冷,液冷技术正成为主流选择。通过冷板式液冷、浸没式液冷或风液混合方案,有效解决高功率密度芯片带来的散热难题。
- 集群建设:多台 AI 服务器可通过高速网络组成超节点集群。例如昇腾 A3 超节点,可包含 384 个昇腾处理器和 192 个鲲鹏处理器,通过 6912 个 400G 光模块和数千根光纤实现极低时延的高速互联,从而支撑千卡乃至万卡级别的大规模分布式训练。

六、结语:服务器进化史,就是AI技术的发展史
从通用服务器的均衡适配,到 AI 服务器的专项突破,服务器节点的每一次形态演进都与计算技术的浪潮同频共振。如今,随着大模型向各行各业渗透,AI 服务器正从“小众高端”走向“规模化应用”。而风冷与液冷的技术路线之争、GPU 与 NPU 的生态路径选择,也将持续推动 AI 基础设施向下一个性能与能效的巅峰迭代。
本文由云栈社区整理发布,旨在为开发者提供清晰的技术解析。想了解更多关于服务器、算力与AI基础设施的深度内容,欢迎访问我们的智能 & 数据 & 云板块进行交流探讨。 |  发表于 2026-1-18 08:40:19
|
查看: 281|
回复: 0
发表于 2026-1-18 08:40:19
|
查看: 281|
回复: 0
