有一种在数据库领域被广泛流传的说法:锁作用在索引上。这个说法对吗?我们不妨思考一下。
顺着这个思路,可以先做一个初步的逻辑梳理:
- 磁盘上的数据是以“页”为单位被加载到内存中的。
- 数据库引擎(如InnoDB)会基于主键构建聚簇索引。
- 假设操作A执行
UPDATE table SET ... WHERE id = 64。
- 操作A通过索引结构快速定位到ID=64的记录所在的数据页。
- 更新这条记录时,将对应的索引条目锁住。
- 此时,操作B也想通过相同的索引路径 (
WHERE id = 64) 来更新同一条记录。
- 操作B发现索引条目已被锁住,于是被成功阻塞。
这样理解似乎天衣无缝,符合直觉。

那么,如果 WHERE 条件使用的是无索引字段呢?例如 email = 'example@qq.com'。众所周知,这将导致全表扫描。
如果“锁作用在索引上”这个前提成立,就会出现一个漏洞:你操作A通过索引路径找到了记录并锁住了索引,我操作C不走索引,直接全表扫描。我绕过了索引检索,直接找到数据记录,岂不是就跳过了你的锁,也能成功执行UPDATE?

...等等,这么明显的漏洞轮得到我来发现吗?如果这个漏洞不存在,那么“锁作用在索引上”的说法可能就是错的。或者,是我们对它的理解有偏差?
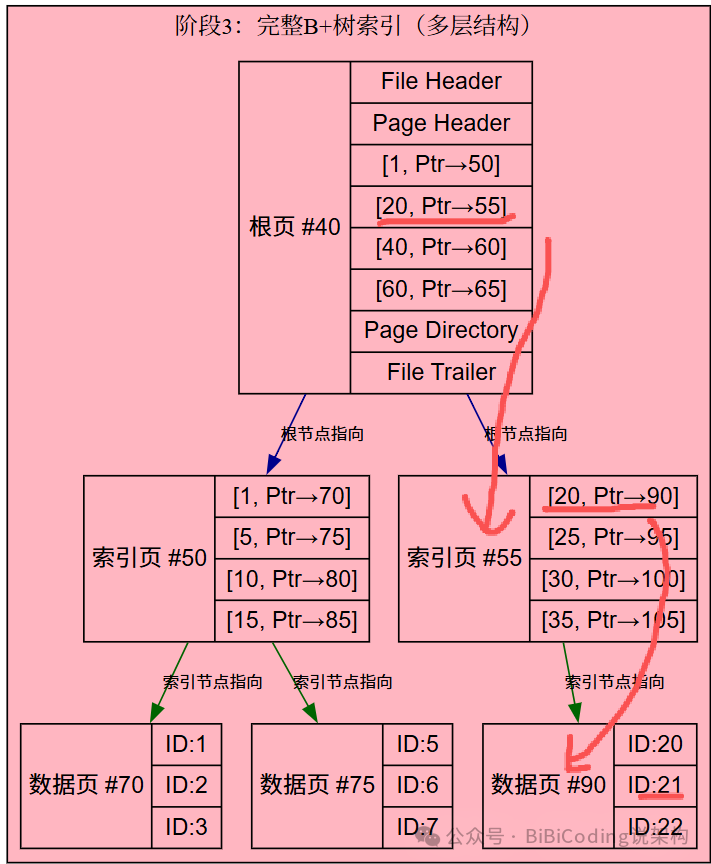
让我们再次审视聚簇索引的结构。以一个查询 WHERE id = 22 为例:
- 首先找到根页(假设是
#40),分析ID范围,检索到id=20的索引记录,它指向下一个索引页#55。
- 找到索引页
#55,分析ID范围,检索到id=20的索引记录,它指向数据页#90。
- 找到数据页
#90,最终检索到数据记录id=22。
现在问题来了:锁到底加在哪了?
- 如果锁加在根页
#40的id=20这条索引记录上,那么整个id在20~39区间的记录都会被锁住。
- 如果锁加在索引页
#55的id=20这条索引记录上,那么整个id在20~24区间的记录都会被锁住。
这显然不是我们所说的行级锁。看来,之前的理解确实可能有问题。
根据以上分析,锁很可能最终是作用在聚簇索引的叶子节点——也就是真实数据记录所在的数据页上。具体来说,是锁在了数据页#90的记录id=22上。
这说明,“锁作用在索引上”这句话里的“索引”,指的并非那些指向其他页面的“索引记录”。
一个技术讨论,差点变成了文字游戏。现在我们可以得出更精确的结论:
“锁作用在索引上”这一说法,容易引发一个普遍的误解:锁是加在一个抽象的、与数据分离的“索引条目”上。
更准确的说法是:“锁最终作用在聚簇索引的叶子节点真实记录所在的页”上。
InnoDB的行级锁,是通过对索引记录加锁来实现的。这里的“索引记录”,对于聚簇索引而言,即为其叶子节点存储的真实数据行;对于二级索引而言,为其叶子节点存储的索引键值及主键。为了保证数据一致性,任何通过二级索引的加锁操作,最终都必须在对应的聚簇索引叶子节点记录上追加一把锁。
那么,现在回看最初那个“漏洞”问题:
- 操作C执行
UPDATE ... WHERE email = 'example@qq.com'。
- 它通过全表扫描方式检索,即直接顺序扫描聚簇索引的所有叶子节点(数据页)。
- 操作A已经对
id=22的记录加了锁(锁在数据页#90的记录L上)。
- 当操作C扫描到数据页
#90的记录L时,会发现该记录已被锁住,从而被阻塞。
- 漏洞消失了,逻辑自洽了。
所以,对MySQL锁机制的理解,关键在于认识到InnoDB中数据和(聚簇)索引是一体的。锁,归根结底是加在构成这棵索引树的、存储着真实数据的“数据页记录”上。希望本文的探讨能帮助你更清晰地理解这一核心机制。更多深入的技术讨论,欢迎访问云栈社区进行交流。 |  发表于 2026-1-18 09:32:09
|
查看: 212|
回复: 0
发表于 2026-1-18 09:32:09
|
查看: 212|
回复: 0
