在当下的AI浪潮中,大模型(LLM)已远不止于文本生成,其边界正迅速扩展到多模态理解、长上下文处理、复杂推理以及自主智能体等综合领域。
若要从一名算法工程师成长为真正的大模型算法专家,你需要构建一个贯穿底层数学原理到高层工程架构的完整知识体系。以下是为你梳理的、面向2026年的专家级技术成长路线图。
第一阶段:数学基石与深度学习底层
成为专家意味着能透视模型内部的权重运作,而非仅停留在API调用层面。
- 数学功底:深入掌握线性代数(矩阵分解、奇异值分解)、微积分(梯度消失与爆炸的数学根源)以及概率统计(贝叶斯推断、分布对齐)。
- 深度学习核心:精通反向传播的详细机制、各类正则化技术的原理,以及现代优化器(如AdamW, Lion)的工作方式。
- 经典架构:尽管Transformer已成为主流,但对RNN、CNN乃至最新的状态空间模型(SSM,如Mamba)的理解,能让你在设计新架构时拥有更深刻的洞察力。
Transformer是现代大模型的“心脏”,专家需要具备从零手写并持续优化它的能力。
- 注意力机制:不仅要掌握多头注意力的原理,还需深入理解分组查询注意力(GQA,已成为2026年主流模型标配)以及线性注意力等变体的数学推导。其核心计算公式如下:
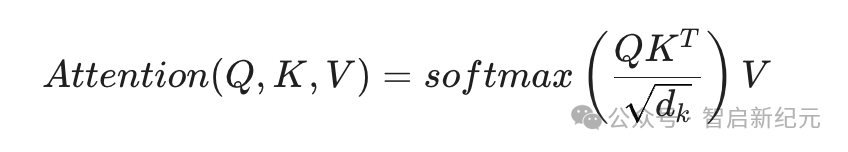
- 位置编码:深入研究RoPE(旋转位置嵌入)及其在超长上下文(例如400K+ tokens)下的外推与插值方案。
- 归一化与激活:理解为什么RMSNorm与SwiGLU在模型稳定性和表达力上优于传统的LayerNorm与ReLU/GELU组合。
第三阶段:大模型全生命周期(从预训练到推理)
这是区分专家与初学者的关键分水岭,你需要通晓模型诞生的每一个核心环节。
| 阶段 |
核心技术点 |
2026年专家重点 |
| 数据工程 |
清洗、去重、合成数据 |
掌握高质量合成数据的生成与有效性过滤策略 |
| 预训练 |
分布式训练、算子优化 |
精通3D并行(TP/PP/DP)及ZeRO系列显存优化技术 |
| 对齐阶段 |
SFT, RLHF, DPO |
能够针对复杂推理任务设计与训练高效的奖励模型 |
| 推理强化 |
CoT (思维链), 强化学习 |
掌握类似DeepSeek-R1的、基于强化学习的思维链训练方法 |
第四阶段:工程架构与性能优化
在算力依然宝贵的2026年,追求极致的效率是专家的必备标签。
- 显存管理:精通FlashAttention系列优化、KV Cache的动态压缩与分页管理技术。
- 量化压缩:不仅会应用4-bit/8-bit量化,还需能在FP8乃至更低精度下保持模型核心能力不出现显著衰退。
- 基础设施:熟悉主流分布式训练框架(如Megatron-LM, DeepSpeed)及高性能推理引擎(如vLLM, TensorRT-LLM)的内部机制。
第五阶段:2026前沿领域(专家高地)
要站在技术之巅,你必须持续关注并深入这些前沿方向:
- 多模态(LMM):超越纯文本,实现图像、视频、音频在统一模型架构下的深度融合与理解。
- 智能体架构(Agentic AI):设计具备自主任务规划、复杂工具调用与长期记忆管理能力的智能体系统。
- 长上下文设计:攻克技术难点,使模型能无损处理百万级token的输入并有效利用其中信息。
- 模型可解释性:运用特征归属分析等工具,深入解释模型产生特定决策或输出的内部逻辑与原因。
掌握以上路径中的核心技术,意味着你不仅跟上了时代,更是在塑造深度学习与AI的未来。技术演进日新月异,持续学习与实践是通往专家之路的不二法门。欢迎在云栈社区与更多同行交流探讨,共同成长。 |  发表于 2026-1-19 10:28:14
|
查看: 147|
回复: 0
发表于 2026-1-19 10:28:14
|
查看: 147|
回复: 0
