在分布式系统架构中,缓存是提升性能、降低数据库压力的核心组件,而缓存穿透问题则是高并发场景下常见且棘手的挑战之一。本文将详细解析缓存穿透的成因,并深入探讨四种主流的解决方案。
什么是缓存穿透?
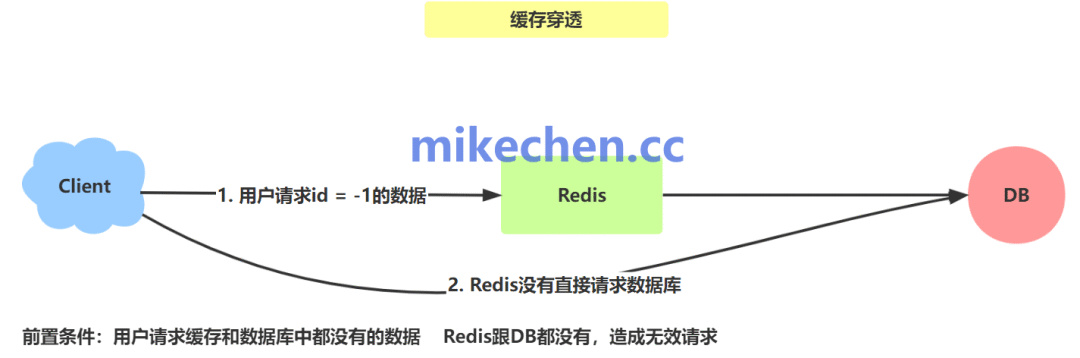
缓存穿透是指查询一个在缓存和数据库中都不存在的数据。由于缓存不具备该数据(未命中),导致每次请求都会直接落到数据库上进行查询。如果恶意攻击者或异常流量持续发起大量针对此类不存在数据的请求,数据库将不堪重负,严重时可能导致服务雪崩。
解决方案一:参数校验与黑名单
最直接的防御是在请求抵达缓存层之前,增加一道“关卡”——进行严格的参数格式与合法性校验。这包括检查ID的数值范围、使用正则表达式验证格式、验证请求签名等。通过这种方式,可以在源头上过滤掉大量格式非法或明显无效的请求。
对于反复、高频请求不存在资源的IP地址或用户标识,可以将其加入临时或长期的黑名单,从而阻断攻击链路。这种方法通常结合网关或应用层的拦截逻辑来实现。
优点与缺点:
- 优点:实现相对简单,系统开销小,能有效拦截低级的恶意扫描。
- 缺点:无法拦截那些参数格式完全合法,但数据确实不存在的查询请求。攻击者很容易构造出符合校验规则的无效键进行攻击。
解决方案二:使用布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于快速判断一个元素是否“可能存在于”某个集合中。其核心思想是:将数据集中的所有合法键(例如所有有效的商品ID)通过多个哈希函数映射到一个位数组中。当查询时,也用相同的哈希函数计算查询键,并检查对应的位是否都为1。
操作流程:
- 初始化:系统启动时,将数据库中所有有效数据的键加载到布隆过滤器中。
- 查询拦截:收到查询请求后,先让请求经过布隆过滤器判断。
- 如果过滤器返回“一定不存在”,则直接拒绝请求或返回空结果,无需查询缓存和数据库。
- 如果过滤器返回“可能存在”,则允许其继续执行正常的缓存查询流程。
优点与缺点:
- 优点:查询速度极快,内存占用远低于存储全量数据键,是应对大规模数据缓存穿透的有效手段。
- 缺点:
- 存在误判率:布隆过滤器判断“可能存在”时,数据实际可能不存在(假阳性)。这意味着少量合法但不存在的数据请求仍会穿透到数据库,但比例极低,在可接受范围内。
- 数据同步问题:当数据库中的数据新增或删除时,需要同步更新布隆过滤器,增加了系统复杂度。
这种方法在应对海量数据、特别是像 Redis 这类键值数据库的缓存穿透场景中应用广泛。
解决方案三:空值缓存
空值缓存,也称缓存空对象,是一种“以空间换保护”的策略。
核心思路:当一次查询穿透缓存后,在数据库中也没有找到对应数据时,不是直接返回空结果给客户端,而是将这个“空结果”(例如一个特定的Null对象或短字符串)也写入缓存中,并为其设置一个相对较短的过期时间(例如3-5分钟)。
后续流程:短时间内,如果再有相同的请求过来,就会命中这个缓存的“空值”,从而避免再次访问数据库。
优点与缺点:
- 优点:实现非常简单,能有效应对短期内针对同一不存在键的重复攻击。
- 缺点:
- 缓存空间浪费:如果攻击者构造大量不同的不存在键,会导致缓存中充满无意义的空值,占用内存。
- 数据不一致窗口期:如果在空值缓存过期前,数据库中实际创建了该数据,会导致用户在这段短暂时间内依旧读到空值。这需要根据业务容忍度来设置合理的过期时间。
解决方案四:限流与降级
当上述防御措施在极端流量下可能失效时,限流与降级是保护系统最后一道防线的策略。
- 接口限流:针对查询接口,在应用网关或服务层面实施限流。可以使用令牌桶、漏桶或简单的计数器算法,限制单个IP、用户或整个服务在单位时间内的请求次数。当请求频率超过阈值时,直接拒绝超额请求。
- 服务降级:当监控系统检测到对某些特定键(或模式)的查询请求异常激增,疑似缓存穿透攻击时,可以主动触发降级策略。例如,针对这些可疑请求,直接返回一个预设的默认值,或者将流量切换到只读的数据库副本上,以保护主数据库。
优点与缺点:
- 优点:能够从宏观流量层面进行抑制,有效防止因缓存穿透导致的数据库被压垮,保障核心服务的稳定运行。
- 缺点:属于“一刀切”的防护,在触发限流或降级时,可能会影响到正常用户的体验。因此,阈值的设定需要非常谨慎,通常需要与业务监控和告警系统紧密配合。
总结与选择
四种方案各有侧重,在实际的 分布式系统 架构设计中,通常会组合使用以形成多层防御体系:
- 第一层(边界):参数校验,过滤明显非法请求。
- 第二层(核心):使用布隆过滤器拦截绝大多数不存在数据的查询。对于数据量不大或变化不频繁的场景,空值缓存也是一个简单有效的选择。
- 第三层(兜底):配置限流与降级策略,在系统压力过大时提供最终保护。
选择哪种或哪几种方案,需要根据具体的业务数据量、查询模式、系统资源以及对一致性的要求来综合权衡。理解这些方案的原理和适用场景,是构建健壮、高性能缓存系统的关键一步。如果你对更多分布式架构和中间件技术感兴趣,欢迎在 云栈社区 交流探讨。 |  发表于 2026-1-19 18:38:28
|
查看: 178|
回复: 0
发表于 2026-1-19 18:38:28
|
查看: 178|
回复: 0
