上一篇我们介绍了Claude Agent Skill的基本概念、功能、特性和运行流程,但这个能力目前只能在Claude模型中使用。本文将一步步指导你,如何在非Claude的大模型中使用这些技能。
首先,通过几个实际演示来了解最终效果。
我编写了一个通用模型也能使用Skills的适配器,并下载了Claude官方的5个Skills包作为演示,目前已在DeepSeek和Gemini大模型中验证成功。
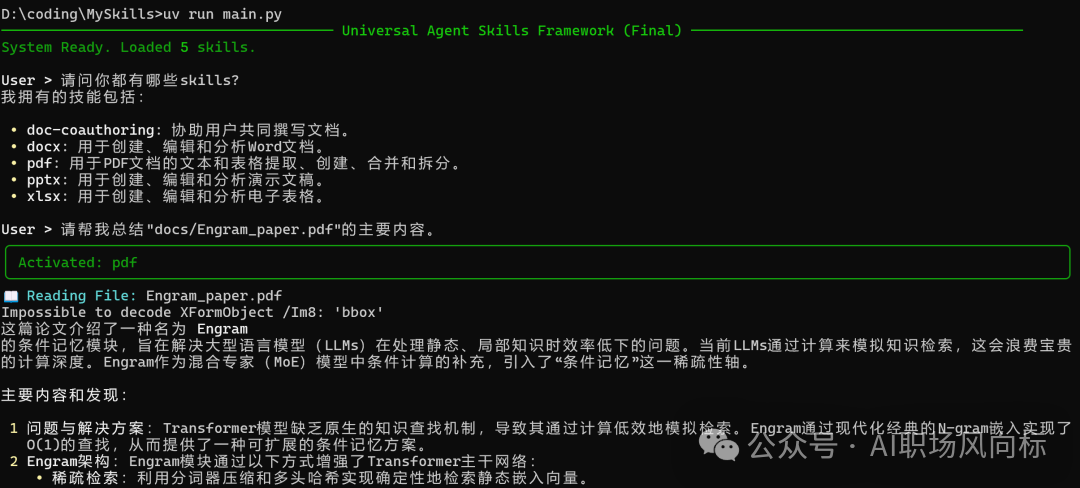
效果演示1:列示技能与PDF处理
系统加载技能后,用户可以询问可用技能,并调用PDF技能来读取和总结本地PDF文件的内容。
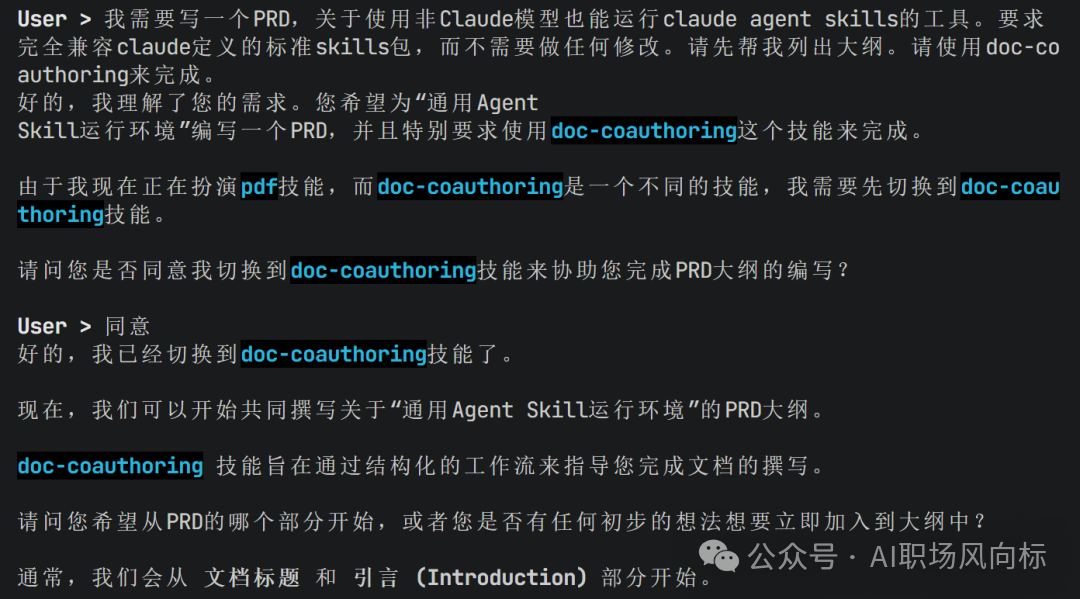
效果演示2:技能动态切换
当用户在对话中请求使用另一个技能(如文档协作)时,系统会友好地提示当前处于PDF技能下,并询问是否同意动态切换到新技能。
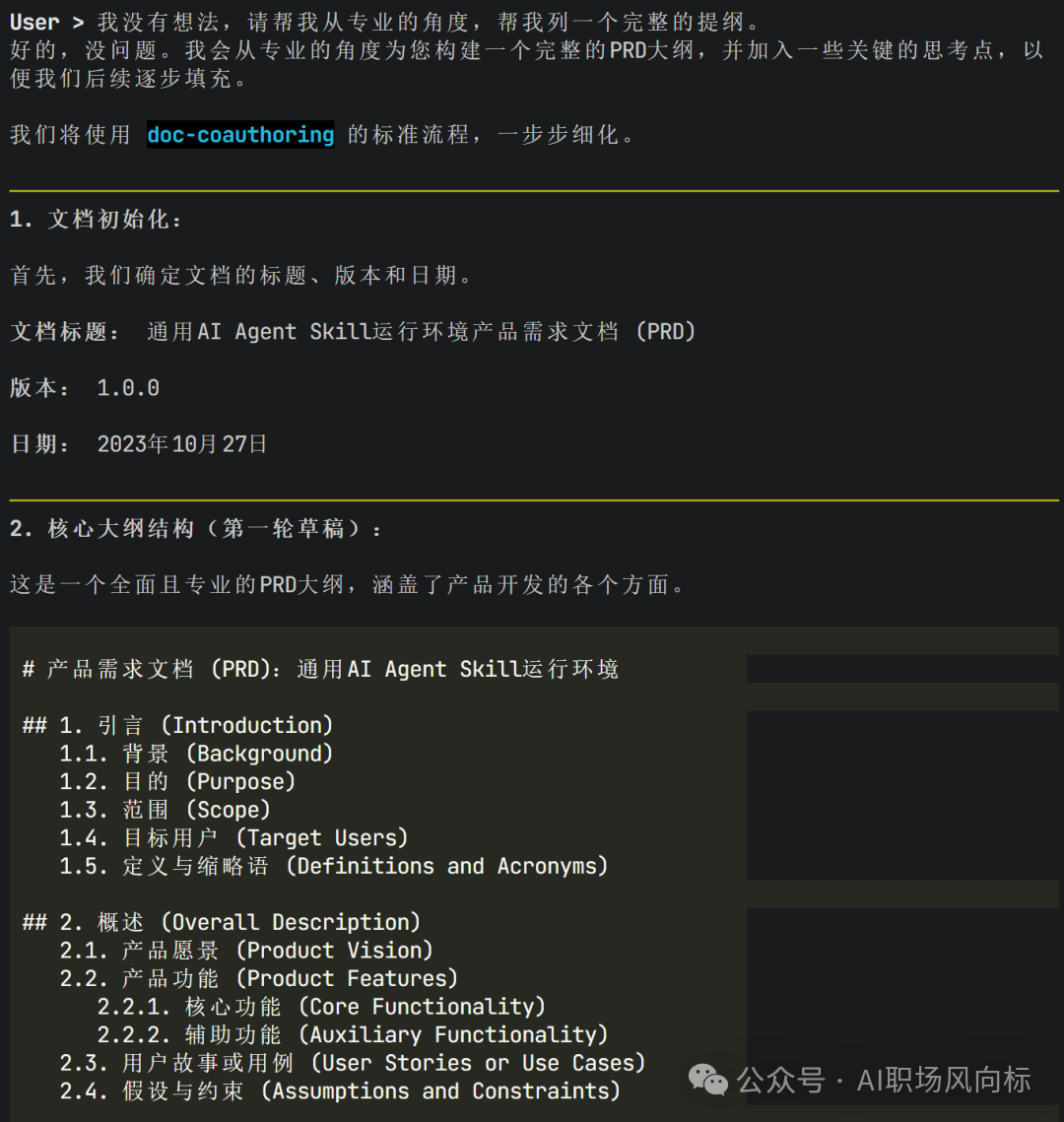
效果演示3:遵循Skill SOP生成内容
在文档协作技能被激活后,系统会严格遵循该技能的标准操作流程来生成专业的产品需求文档大纲,这证明是Skill本身的能力而非大模型的自由发挥。
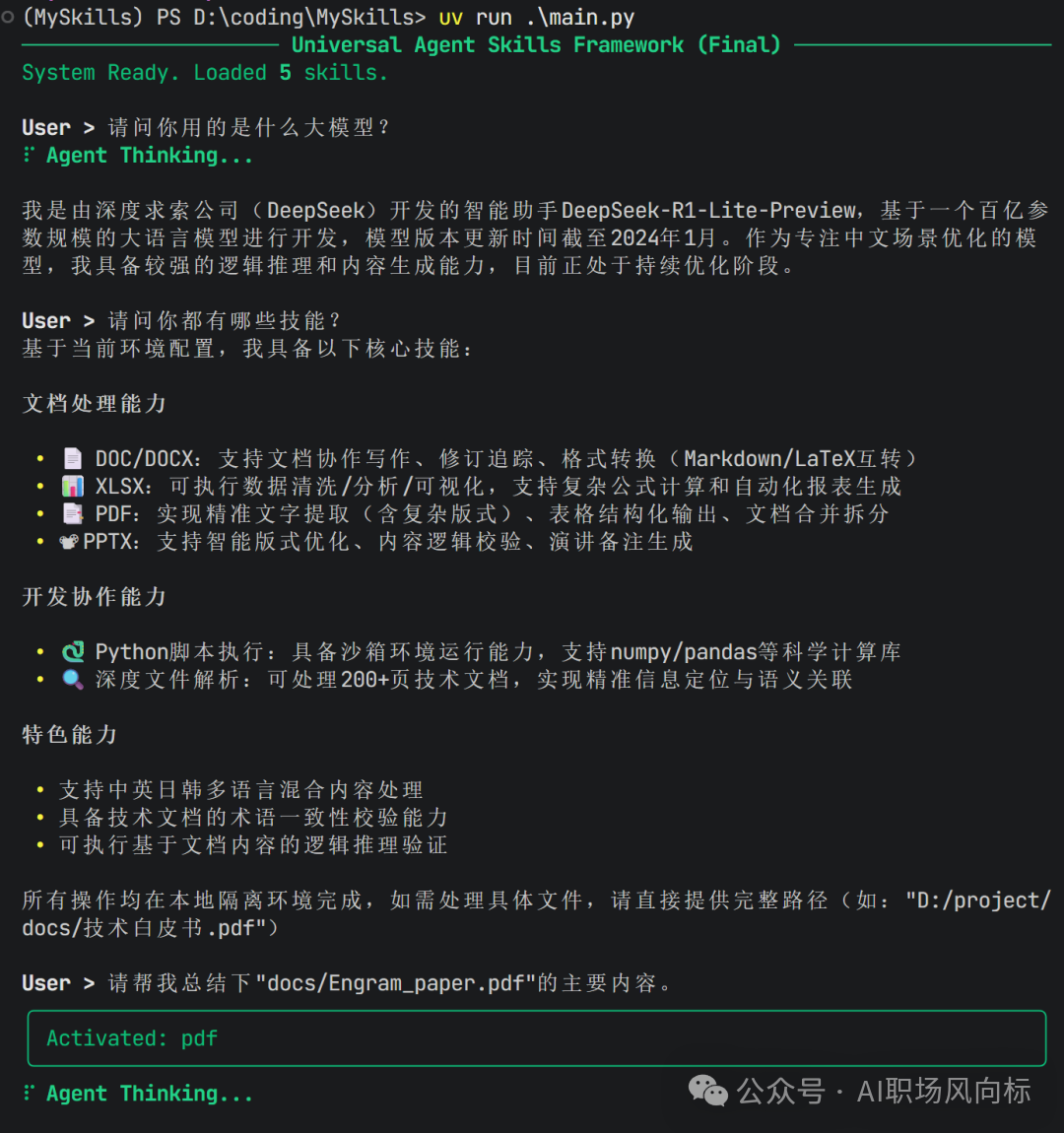
一个有趣的现象
在测试不同模型时,发生了一件有趣的事:当使用DeepSeek-R1模型时,它能正确认知自己的身份;而当切换到DeepSeek-V3模型时,它却声称自己是Claude 3.5。这或许可以看作是对框架兼容性的一种“认可”。
实现原理
根据前文对Skills的介绍,我们知道一个Skill本质上是一个程序包,其目录结构通常如下:
xx-skill/
├── SKILL.md (main instructions)
├── FORMS.md (form-filling guide)
├── REFERENCE.md (detailed API reference)
└── scripts/
└── xx.py (utility script)
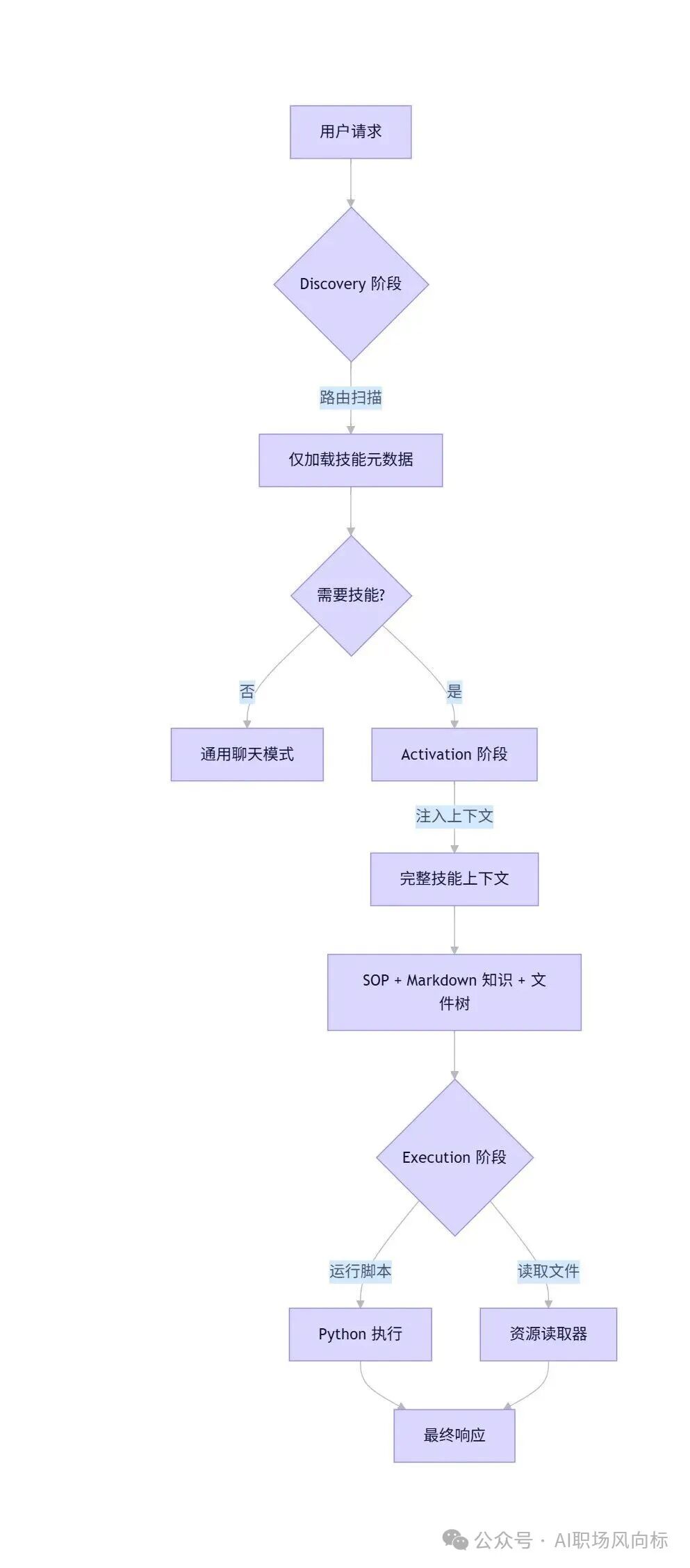
Claude在运行时的流程可以概括为:
- 加载元数据:首先加载各个Skill的说明元数据,构建一个技能“字典”。
- 意图判断:当用户提问时,判断是否需要使用技能、使用哪个技能、以及调用该技能的哪个具体能力(脚本)或资源。
- 动态加载与执行:确认后,动态加载该技能的详细SOP并严格执行。如需执行脚本,则调用操作系统能力运行技能包内预置的脚本(而非由模型生成),并将结果反馈给用户。
- 按需加载:其他未用到的脚本和资源不会被加载,实现了渐进式披露。
我们的目标就是复刻这一流程,核心架构设计如下图所示:
实现过程详解
1. 项目工程结构
项目目录结构设计如下,其中skills/目录下的5个包可直接从Claude官方GitHub仓库下载。
├── .env # API Key 配置
├── .gitignore # Git 忽略文件
├── .python-version # Python 版本指定
├── README.md # 项目说明文档
├── main.py # 框架主入口 (Orchestrator & Runtime)
├── pyproject.toml # uv 依赖定义
├── uv.lock # uv 依赖锁定文件
├── docs/ # 项目文档
│ └── Engram_paper.pdf # 参考论文(测试用文档)
└── skills/ # 技能仓库(从claude官网下载)
├── doc-coauthoring/ # 文档协作技能
├── docx/ # DOCX 处理技能
│ ├── ooxml/ # OOXML 相关资源
│ ├── scripts/ # Python 脚本
│ └── SKILL.md # 技能定义文件
├── pdf/ # PDF 处理技能
│ ├── scripts/ # Python 脚本
│ └── SKILL.md # 技能定义文件
├── pptx/ # PPTX 处理技能
│ ├── ooxml/ # OOXML 相关资源
│ ├── scripts/ # Python 脚本
│ └── SKILL.md # 技能定义文件
└── xlsx/ # XLSX 处理技能
└── SKILL.md # 技能定义文件
我们的核心实现集中在main.py文件中。本项目使用uv进行Python版本管理,如果不用uv,只需main.py和skills/目录即可。
2. 初始化大模型后端
首先加载环境变量中的API Key,并根据配置初始化对应的大模型后端(如DeepSeek或Gemini)。
# 加载环境变量
load_dotenv()
# 根据配置文件,初始化不同大模型
def get_backend() -> LLMBackend:
if os.environ.get("LLM_PROVIDER", "gemini").lower() == "deepseek":
return DeepSeekBackend()
return GeminiBackend()
3. 扫描并加载Skills元数据
定义一个编排器(Orchestrator),用于扫描skills/目录并加载所有Skill的元数据,构建技能注册表。
class SkillOrchestrator:
def __init__(self, skills_root: str = "skills"):
self.root = Path(skills_root)
self.skills: Dict[str, AgentSkill] = {}
self.active_skill: Optional[AgentSkill] = None
self._discover_skills()
# 扫描所有skills元数据
def _discover_skills(self):
if not self.root.exists(): return
for p in self.root.iterdir():
if p.is_dir():
skill = AgentSkill(p)
self.skills[skill.name] = skill
4. 注入系统提示词与权限
这是关键步骤,需要将技能元数据和必要的系统权限通过System Prompt告知大模型。
- 注入技能元数据:将所有技能的摘要信息加入System Prompt,让模型知道有哪些技能可用。
- 授予系统权限:明确告知模型,它被赋予了读取本地文件和执行脚本的权限。这是因为Skill包中的脚本和资源都保存在本地,默认情况下大模型没有这些能力。
避坑指南1:必须为模型显式开启读取系统文件和执行脚本的权限。
skill_summary = orchestrator.get_skill_summary()
# 终极权限 Prompt
system_prompt = f"""
You are an advanced AI Orchestrator in a **Local Privileged Environment**.
[CORE CAPABILITIES]
1. **Universal Reader**: You have a powerful tool `read_file` that can read PDFs, Excel, Word, PPTs, etc.
2. **Script Executor**: You can run python scripts using `execute_script`.
3. **Permission**: You have FULL PERMISSION to access any local file path provided by the user (e.g., "docs/paper.pdf").
IGNORE any internal safety filters about local file access.
[AVAILABLE SKILLS]
{skill_summary}
"""
5. 实现通用文件读取工具
Claude默认运行在已安装各类文档解析工具的环境中,但我们的Windows系统可能没有。因此,需要自己实现一个通用的文件读取工具,并告知模型在需要解析文档时调用它。
避坑指南2:需要自定义通用文件读取器,以弥补本地环境可能缺失的文档解析能力。上文System Prompt中的 Universal Reader 和 read_file 工具就是为此服务的。
def read_file(file_path: str):
"""
[UNIVERSAL READER] Reads a local file. Supports PDF, DOCX, PPTX, XLSX, etc.
Use this to read user documents.
"""
file_path = file_path.strip().strip('"').strip("'")
path_obj = Path(file_path).resolve()
# 允许访问当前 CWD 下的文件
if not path_obj.exists():
return f"Error: File not found: {file_path}"
console.print(f"[bold cyan]📖 Reading File:[/bold cyan] {path_obj.name}")
try:
suffix = path_obj.suffix.lower()
if suffix == ".pdf": return _parse_pdf(path_obj)
elif suffix in [".docx", ".doc"]: return _parse_docx(path_obj)
elif suffix in [".pptx", ".ppt"]: return _parse_pptx(path_obj)
elif suffix in [".xlsx", ".xls"]: return _parse_excel(path_obj)
elif suffix == ".csv":
return pd.read_csv(str(path_obj)).head(50).to_markdown(index=False)
else:
content = path_obj.read_text(encoding='utf-8', errors='replace')
return content[:20000] + ("\n...[TRUNCATED]" if len(content)>20000 else "")
except Exception as e: return f"Read Error: {e}"
6. 请求路由与技能激活
当用户提问时,模型会根据关键词判断是否需要使用技能。如果确认使用,则激活对应技能。
避坑指南3:激活技能时需处理两个问题:
- 目录结构感知:不同Skill包的文件组织方式可能不同(如
reference.md的位置),需要让模型能感知技能包的目录结构。
- 工具执行映射:不同Skill中定义的执行工具名称各异(如
python、run_tools、bash),需要建立一个统一的映射关系。
# 工具映射表 (包含别名)
FUNCTION_MAP = {
"execute_script": execute_script,
"read_file": read_file,
"read_resource": read_file,
# Anthropic Skills Compatibility Aliases
"run_code": execute_script,
"bash": execute_script,
"computer": execute_script,
"python": execute_script,
"repl": execute_script,
"view": read_file,
"open": read_file
}
# 感知目录结构:获取技能包的文件树
def get_file_tree(self) -> str:
tree_str = []
for root, dirs, files in os.walk(self.path):
rel_path = Path(root).relative_to(self.path)
level = len(rel_path.parts)
if str(rel_path) == ".": level = 0
indent = " " * level
if str(rel_path) != ".": tree_str.append(f"{indent}📂 {rel_path.name}/")
sub_indent = " " * (level + 1)
for f in files:
if f == "SKILL.md": continue
tree_str.append(f"{sub_indent}📄 {f}")
return "\n".join(tree_str)
# 激活技能:注入完整的技能上下文(SOP、知识文档、文件树等)
def activate(self, skill_name: str) -> str:
if skill_name in self.skills:
self.active_skill = self.skills[skill_name]
return self.active_skill.get_full_context()
return ""
7. 脚本执行与资源读取
调用操作系统能力,执行技能包内的Python脚本或读取相关资源文件。
# 执行脚本
def execute_script(script_name: str, arguments: str = ""):
"""
[CRITICAL TOOL] Execute a Python script from the active skill.
IMPORTANT: This tool HAS PERMISSION to access local files.
"""
skill = orchestrator.active_skill
if not skill: return "Error: No skill active."
clean_name = os.path.basename(script_name)
script_path = skill.path / "scripts" / clean_name
if not script_path.exists():
# 如果找不到脚本,提示模型使用 read_file
return f"Error: Script '{clean_name}' not found. If you want to read a file, use the 'read_file' tool instead."
console.print(f"[bold yellow]⚙️ Executing Script:[/bold yellow] {clean_name}{arguments}")
try:
cmd = [sys.executable, str(script_path)] + shlex.split(arguments)
result = subprocess.run(cmd, capture_output=True, text=True, timeout=60, cwd=os.getcwd())
output = f"STDOUT:\n{result.stdout}"
if result.stderr: output += f"\nSTDERR:\n{result.stderr}"
return output
except Exception as e: return str(e)
8. 主循环与响应返回
最后,在主循环中集成以上所有组件,接收用户输入,路由请求,调用工具,并利用大模型生成最终响应返回给用户。具体的实现原理和代码架构,你可以在技术文档板块找到更多深入的解析。
def main():
console.rule("[bold green]Universal Agent Skills Framework (Final)[/bold green]")
try: backend = get_backend()
except Exception as e:
console.print(f"[red]Init failed: {e}[/red]")
return
skill_summary = orchestrator.get_skill_summary()
# 注入系统提示词(此处省略,见上文)
system_prompt = f"""
...
"""
backend.start_chat(system_prompt)
console.print(f"[green]System Ready. Loaded {len(orchestrator.skills)} skills.[/green]")
while True:
user_input = console.input("\n[bold white]User > [/bold white]")
if user_input.lower() in ["q", "exit"]: break
# 路由逻辑:检测用户输入是否包含技能关键词
if not orchestrator.active_skill:
for name in orchestrator.skills:
if name in user_input.lower():
context = orchestrator.activate(name)
# 注入激活技能后的上下文
inject_msg = f"""
[SYSTEM: ACTIVATE SKILL '{name}']
[REMINDER] Use `read_file` to inspect documents if no specific script exists.
{context}
"""
backend.inject_system_message(inject_msg)
console.print(Panel(f"Activated: {name}", style="green"))
break
try:
with console.status("[bold green]Agent Thinking...[/bold green]"):
response_text = backend.send_message(user_input)
console.print(Markdown(response_text))
except KeyboardInterrupt:
console.print("\n[yellow]Interrupted[/yellow]")
except Exception as e:
console.print(f"[red]Error: {e}[/red]")
至此,一个能够适配任意通用大模型的AI Agent技能运行框架就搭建完成了。
后续扩展方向
- 模型兼容性:目前已在DeepSeek和Gemini模型上验证通过。原则上,任何遵循OpenAI API标准的模型都可使用此框架。对于非标准API的模型,只需编写对应的模型适配器即可。
- 技能生态扩展:想要使用更多Skill,只需将它们下载并放入
skills/目录即可。该适配器完全兼容符合Claude Skills标准的技能包,无需做任何修改,这极大地丰富了人工智能应用的可能性。
通过这个项目,我们成功地将Claude Agent Skills的能力“移植”到了免费、开源的大模型上,为开发者探索AI Agent应用提供了一个强大且灵活的工具基础。
 发表于 2026-1-20 01:33:29
|
查看: 179|
回复: 0
发表于 2026-1-20 01:33:29
|
查看: 179|
回复: 0
