在实际项目开发中,我深入研究了检索增强生成技术,本文将系统性地总结8种主流的RAG架构,对每种架构的核心思想进行简要剖析,并运用 LangChain 框架提供可直接参考的实现代码。
1. Naive RAG
简介:Naive RAG 是最基础、最经典的检索增强生成架构,严格遵循“索引-检索-生成”的三段式流程。
架构:
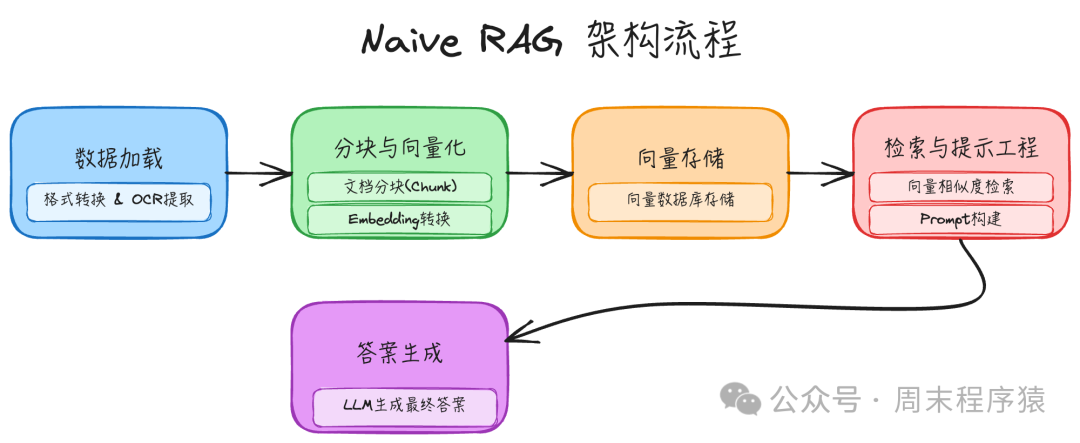
实现步骤:
- 数据加载:收集并清洗原始数据,例如完成不同文档格式间的转换、OCR文字提取等预处理工作。
- 分块和向量化:将文档切分成更小的文本块。这不仅能帮助 Embedding 模型更好地转换语义信息,同时也是为了解决大语言模型的上下文长度限制问题。
- 向量存储:将文本块生成的向量表示存储到向量数据库中,以便后续进行高效的相似度搜索。
- 检索与提示工程:对于用户查询,首先通过向量数据库进行相似度检索,然后将召回的相关文档原文,通过精心设计的提示词模板加工后,提供给大语言模型。
- 输出答案:大语言模型根据提示词和检索到的上下文,生成最终答案。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
import lancedb
class NaiveRAG:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
# 使用轻量级的all-MiniLM-L6-v2模型,仅80MB
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.db = lancedb.connect("/tmp/lancedb_naive_rag")
self.vectorstore = None
def build_index(self, documents: list):
"""构建向量索引"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="naive_rag_docs"
)
def query(self, question: str) -> str:
"""执行检索并生成答案"""
# 创建检索链
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 3})
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template="""基于以下上下文回答问题:
上下文: {context}
问题: {question}
答案:"""
)
qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={"prompt": prompt_template}
)
return qa_chain.invoke({"query": question})["result"]
# 使用示例
naive_rag = NaiveRAG()
naive_rag.build_index(["文档1内容...", "文档2内容...", "文档3内容..."])
answer = naive_rag.query("What is issue date of lease?")
print(answer)
2. Multi-Head RAG
简介:Multi-Head RAG 的灵感来源于 Transformer模型 的多头注意力机制。它利用模型不同注意力头所捕获的多样化语义特征进行并行检索,从而获得更全面的信息。
架构:
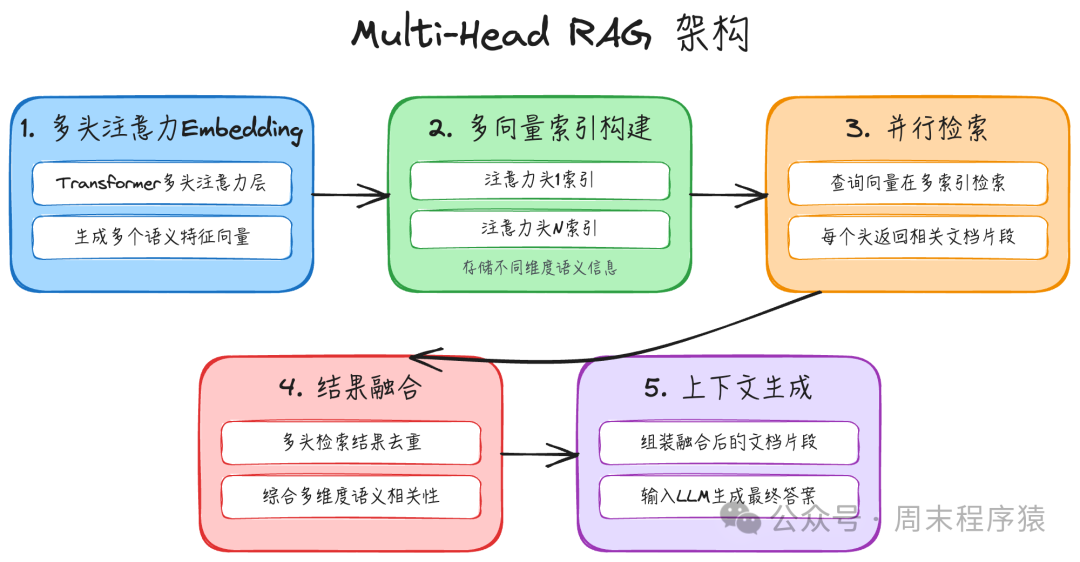
实现步骤:
- 多头注意力Embedding:利用 Transformer 模型的多头注意力层(而非最后一层的CLS向量)生成多个向量表示,每个头捕获文本中不同的语义或语法特征。
- 多向量索引构建:为每一个注意力头构建独立的向量索引,分别存储不同维度视角下的语义信息。
- 并行检索:针对用户的查询,在所有索引上并行执行检索操作,每个头都会返回其认为最相关的文档片段。
- 结果融合:将来自多个头的检索结果进行去重和融合,综合考虑不同语义维度下的相关性。
- 上下文生成:将融合后的文档片段组装成最终的上下文,输入给大语言模型生成答案。
相关参考:
参考代码:
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.embeddings.base import Embeddings
from transformers import AutoModel, AutoTokenizer
import torch
import lancedb
from typing import List
class MultiHeadEmbeddings(Embeddings):
"""自定义多头注意力Embedding,继承LangChain的Embeddings基类"""
def __init__(self, model_name="bert-base-uncased", head_index=0, num_heads=12):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name, output_hidden_states=True)
self.head_index = head_index
self.num_heads = num_heads
self.head_dim = 768 // num_heads # BERT hidden size / num_heads
def _get_head_embedding(self, texts: List[str]) -> List[List[float]]:
"""获取指定头的embedding"""
inputs = self.tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = self.model(**inputs, output_hidden_states=True)
hidden_states = outputs.hidden_states[-2] # 倒数第二层
start = self.head_index * self.head_dim
end = (self.head_index + 1) * self.head_dim
head_emb = hidden_states[:, 0, start:end].numpy()
return head_emb.tolist()
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return self._get_head_embedding(texts)
def embed_query(self, text: str) -> List[float]:
return self._get_head_embedding([text])[0]
class MultiHeadRAG:
def __init__(self, num_heads=12):
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
self.num_heads = num_heads
self.db = lancedb.connect("/tmp/lancedb_multihead_rag")
self.vectorstores = [] # 每个头一个向量存储
self.documents = []
def build_index(self, documents: List[str]):
"""为每个头构建独立的LanceDB向量存储"""
self.documents = documents
docs = [Document(page_content=d) for d in documents]
for head_idx in range(self.num_heads):
embeddings = MultiHeadEmbeddings(head_index=head_idx, num_heads=self.num_heads)
vectorstore = LanceDB.from_documents(
docs,
embeddings,
connection=self.db,
table_name=f"head_{head_idx}_docs"
)
self.vectorstores.append(vectorstore)
def search(self, query: str, top_k: int = 3) -> List[str]:
"""多头并行检索并融合结果"""
all_results = set()
for vectorstore in self.vectorstores:
docs = vectorstore.similarity_search(query, k=top_k)
for doc in docs:
all_results.add(doc.page_content)
return list(all_results)
def query(self, question: str) -> str:
"""检索并生成答案"""
retrieved_docs = self.search(question)
context = "\n\n".join(retrieved_docs)
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template(
"""基于以下多维度检索的上下文回答问题:
上下文: {context}
问题: {question}
答案:"""
)
chain = prompt | self.llm
response = chain.invoke({"context": context, "question": question})
return response.content
# 使用示例
mrag = MultiHeadRAG(num_heads=12)
documents = ["文档1的内容...", "文档2的内容...", "文档3的内容..."]
mrag.build_index(documents)
answer = mrag.query("查询问题")
print(answer)
3. Corrective RAG
简介:Corrective RAG 在传统 RAG 流程中引入了文档质量评估和自我修正机制。它会对检索到的每个文档进行相关性评分(Correct/Incorrect/Ambiguous),如果发现本地知识库的文档质量不足,则会主动搜索外部知识源(如网络)进行补充和修正。
架构:
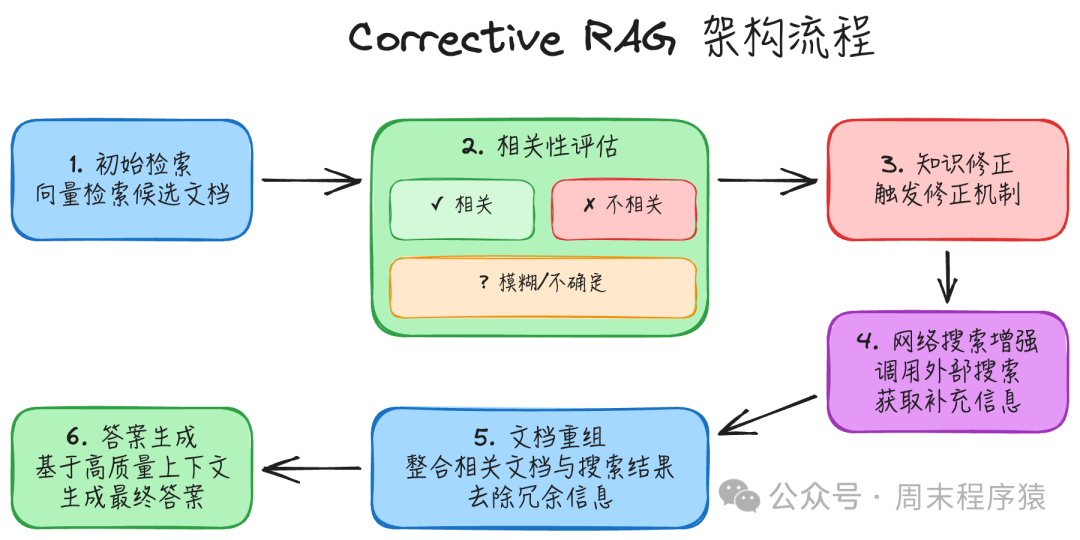
实现步骤:
- 初始检索:使用向量检索从本地知识库中获取与查询相关的候选文档。
- 相关性评估:使用大语言模型或专门的评估模型对每个检索到的文档进行相关性评分,判断其是否相关、不相关或模糊不确定。
- 知识修正:对于评估为不相关或模糊的文档,系统会触发知识修正机制。
- 网络搜索增强:当本地知识库无法提供足够质量的信息时,调用外部搜索引擎API来获取补充信息。
- 文档重组:将评估为相关的本地文档和补充的搜索结果进行整合,去除冗余信息,形成高质量的上下文。
- 答案生成:基于修正和重组后的高质量上下文,生成最终答案。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain_community.tools import TavilySearchResults
from langchain.schema import Document
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import lancedb
from typing import List
class CorrectiveRAG:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.db = lancedb.connect("/tmp/lancedb_corrective_rag")
self.vectorstore = None
# 使用Tavily进行网络搜索
self.web_search = TavilySearchResults(max_results=3)
def build_index(self, documents: List[str]):
"""构建向量索引"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="corrective_rag_docs"
)
def evaluate_relevance(self, query: str, document: str) -> str:
"""评估文档与查询的相关性"""
prompt = ChatPromptTemplate.from_template(
"""评估以下文档与查询的相关性。
查询: {query}
文档: {document}
请回答: CORRECT(相关), INCORRECT(不相关), 或 AMBIGUOUS(模糊)
只返回一个词。"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"query": query, "document": document})
return response.strip().upper()
def search_web(self, query: str) -> List[str]:
"""当本地文档不足时进行网络搜索"""
try:
results = self.web_search.invoke(query)
return [r["content"] for r in results if "content" in r]
except:
return []
def retrieve_and_correct(self, query: str, top_k: int = 5) -> List[str]:
"""检索并修正文档"""
# 1. 初始检索
retriever = self.vectorstore.as_retriever(search_kwargs={"k": top_k})
docs = retriever.invoke(query)
# 2. 评估每个文档的相关性
correct_docs = []
need_web_search = True
for doc in docs:
relevance = self.evaluate_relevance(query, doc.page_content)
if relevance == "CORRECT":
correct_docs.append(doc.page_content)
need_web_search = False
elif relevance == "AMBIGUOUS":
# 对模糊文档进行知识精炼
refined = self.refine_document(query, doc.page_content)
correct_docs.append(refined)
# 3. 必要时进行网络搜索补充
if need_web_search or len(correct_docs) < 2:
web_results = self.search_web(query)
correct_docs.extend(web_results)
return correct_docs
def refine_document(self, query: str, document: str) -> str:
"""精炼文档,提取与查询相关的部分"""
prompt = ChatPromptTemplate.from_template(
"""从以下文档中提取与查询最相关的信息:
查询: {query}
文档: {document}
请只返回相关的精炼内容:"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"query": query, "document": document})
def query(self, question: str) -> str:
"""生成最终答案"""
corrected_docs = self.retrieve_and_correct(question)
context = "\n\n".join(corrected_docs)
prompt = ChatPromptTemplate.from_template(
"""基于以下经过修正的上下文回答问题:
上下文: {context}
问题: {question}
答案:"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"context": context, "question": question})
# 使用示例
crag = CorrectiveRAG()
crag.build_index(["文档1...", "文档2...", "文档3..."])
answer = crag.query("你的问题是什么?")
print(answer)
4. Agentic RAG
简介:Agentic RAG(智能体RAG)将 AI Agent 的自主规划、决策和推理能力与 RAG 技术深度融合。智能体可以自主分析用户查询的复杂性,动态制定检索策略,灵活选择合适的工具(如语义搜索、关键词搜索、计算器、API调用等),并基于中间结果进行迭代优化和自我反思。
架构:
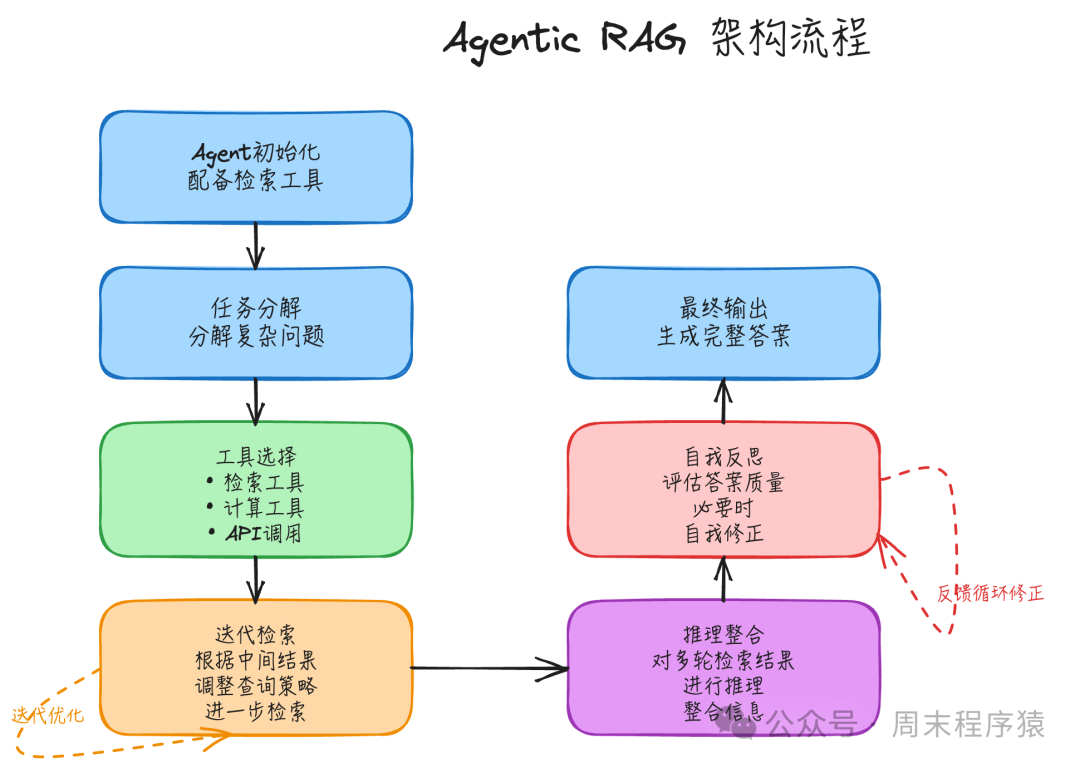
实现步骤:
- Agent初始化:创建一个具备推理和规划能力的AI智能体,并为其配备一系列检索和计算工具。
- 任务分解:智能体分析用户查询,将复杂问题拆解为一系列可执行的子任务。
- 工具选择:智能体根据每个子任务的特点,自主选择合适的工具来执行(例如,理解意图用语义搜索,精确匹配用关键词搜索,计算数值用计算器)。
- 迭代检索:智能体可以根据工具执行的中间结果,判断是否需要进一步检索,或调整查询策略以获取更精准的信息。
- 推理整合:智能体对多轮检索和工具调用的结果进行综合推理和整合,提炼出核心信息。
- 自我反思:智能体评估初步答案的质量,必要时启动自我修正流程。
- 最终输出:生成完整、准确且经过验证的最终答案。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain.tools import tool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
import lancedb
from typing import List
class AgenticRAG:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0)
# 使用轻量级的all-MiniLM-L6-v2模型,仅80MB
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.db = lancedb.connect("/tmp/lancedb_agentic_rag")
self.vectorstore = None
self.agent_executor = None
def build_index(self, documents: List[str]):
"""构建向量索引"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="agentic_rag_docs"
)
def setup_agent(self):
"""配置Agent和工具"""
vectorstore = self.vectorstore # 闭包引用
@tool
def semantic_search(query: str) -> str:
"""用于语义搜索,当需要理解问题含义并查找相关文档时使用"""
docs = vectorstore.similarity_search(query, k=3)
return "\n".join([d.page_content for d in docs])
@tool
def keyword_search(query: str) -> str:
"""用于关键词搜索,当需要精确匹配特定术语时使用"""
docs = vectorstore.similarity_search(query, k=2)
return "\n".join([d.page_content for d in docs])
@tool
def calculator(expression: str) -> str:
"""用于数学计算,输入数学表达式"""
try:
return str(eval(expression))
except:
return "计算错误"
tools = [semantic_search, keyword_search, calculator]
# 使用新版本的Agent提示模板
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个智能助手,可以使用工具来回答问题。
可用工具:
- semantic_search: 用于语义搜索,查找相关文档
- keyword_search: 用于关键词精确匹配
- calculator: 用于数学计算
请根据问题选择合适的工具,可以多次调用工具来获取完整信息。"""),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# 创建Tool Calling Agent
agent = create_tool_calling_agent(self.llm, tools, prompt)
self.agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=5,
handle_parsing_errors=True
)
def query(self, question: str) -> str:
"""执行查询"""
if not self.agent_executor:
self.setup_agent()
result = self.agent_executor.invoke({"input": question})
return result["output"]
# 使用示例
arag = AgenticRAG()
arag.build_index(["产品A价格100元...", "产品B价格200元...", "优惠政策..."])
answer = arag.query("产品A和产品B的总价是多少?有什么优惠?")
print(answer)
5. Graph RAG
简介:Graph RAG 将 知识图谱 技术与 RAG 相结合。它首先从文档中抽取出实体和关系,构建结构化的知识图谱,然后在此基础上进行社区检测和摘要生成。这种方式使得检索不仅基于文本相似度,更能利用实体间的关联关系进行更深入、更全面的信息获取。
架构:
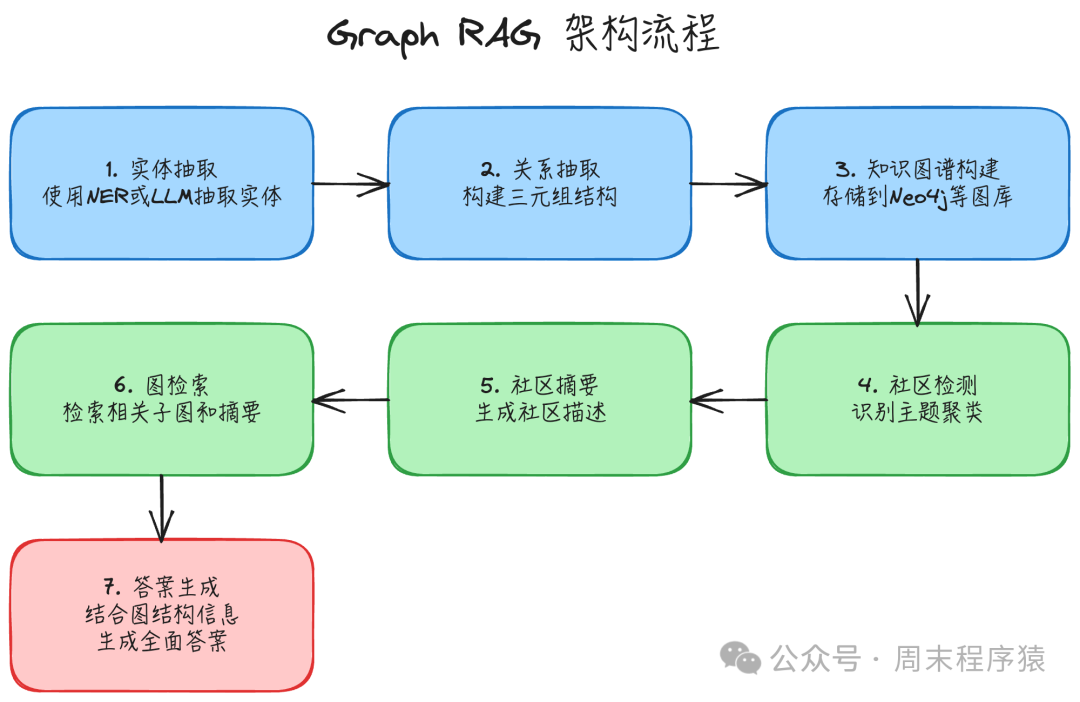
实现步骤:
- 实体抽取:使用命名实体识别(NER)或大语言模型从文档中抽取关键实体,如人物、地点、组织、概念等。
- 关系抽取:识别并抽取出实体之间的相互关系,构建“主体-关系-客体”的三元组结构。
- 知识图谱构建:将抽取出的实体和关系存储到图数据库(如 Neo4j)中,形成结构化的知识网络。
- 社区检测:对构建好的知识图谱进行社区划分算法,识别出紧密相关的主题或概念聚类。
- 社区摘要:为每个检测出的社区生成一段概括性的描述摘要。
- 图检索:根据用户查询,在知识图谱中检索相关的子图(包含实体及其关联)和对应的社区摘要。
- 答案生成:结合检索到的图结构信息和社区摘要,生成更全面、更具洞察力的答案。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_community.graphs import Neo4jGraph
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
import networkx as nx
from typing import List, Dict
import json
class GraphRAG:
def __init__(self, neo4j_uri="bolt://localhost:7687",
neo4j_user="neo4j", neo4j_password="password"):
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
# 使用LangChain的Neo4j集成
self.graph_db = Neo4jGraph(
url=neo4j_uri,
username=neo4j_user,
password=neo4j_password
)
self.nx_graph = nx.Graph()
def extract_entities_and_relations(self, text: str) -> Dict:
"""使用LLM抽取实体和关系"""
prompt = ChatPromptTemplate.from_template(
"""从以下文本中抽取实体和关系,返回JSON格式:
文本: {text}
返回格式(只返回JSON):
{{
"entities": ["实体1", "实体2", ...],
"relations": [["实体1", "关系", "实体2"], ...]
}}"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"text": text})
try:
return json.loads(response)
except:
return {"entities": [], "relations": []}
def build_knowledge_graph(self, documents: List[str]):
"""构建知识图谱"""
for doc in documents:
extracted = self.extract_entities_and_relations(doc)
# 添加到NetworkX图
for entity in extracted["entities"]:
self.nx_graph.add_node(entity)
for rel in extracted["relations"]:
if len(rel) == 3:
self.nx_graph.add_edge(rel[0], rel[2], relation=rel[1])
# 存储到Neo4j
for entity in extracted["entities"]:
self.graph_db.query(
"MERGE (e:Entity {name: $name})",
{"name": entity}
)
for rel in extracted["relations"]:
if len(rel) == 3:
self.graph_db.query(
"""MATCH (a:Entity {name: $from})
MATCH (b:Entity {name: $to})
MERGE (a)-[r:RELATED {type: $rel}]->(b)""",
{"from": rel[0], "to": rel[2], "rel": rel[1]}
)
def detect_communities(self) -> List[List[str]]:
"""社区检测"""
from networkx.algorithms import community
if len(self.nx_graph.nodes()) == 0:
return []
communities = community.louvain_communities(self.nx_graph)
return [list(c) for c in communities]
def generate_community_summaries(self, communities: List[List[str]]) -> List[Dict]:
"""为每个社区生成摘要"""
summaries = []
for i, comm in enumerate(communities):
subgraph = self.nx_graph.subgraph(comm)
edges_info = [(u, v, d.get('relation', ''))
for u, v, d in subgraph.edges(data=True)]
prompt = ChatPromptTemplate.from_template(
"""为以下实体群组生成简短摘要:
实体: {entities}
关系: {relations}
摘要:"""
)
chain = prompt | self.llm | StrOutputParser()
summary = chain.invoke({"entities": comm, "relations": edges_info})
summaries.append({"community": i, "entities": comm, "summary": summary})
return summaries
def query(self, question: str) -> str:
"""基于图的检索和回答"""
# 1. 从问题中提取关键实体
entities = self.extract_entities_and_relations(question)["entities"]
# 2. 在Neo4j中查找相关子图
graph_context = self.graph_db.query(
"""MATCH (e:Entity)-[r]-(related)
WHERE e.name IN $entities
RETURN e.name AS entity, type(r) AS rel_type,
r.type AS relation, related.name AS related_entity
LIMIT 20""",
{"entities": entities}
)
# 3. 获取社区摘要
communities = self.detect_communities()
summaries = self.generate_community_summaries(communities[:3])
# 4. 生成答案
context = f"图关系: {graph_context}\n社区摘要: {summaries}"
prompt = ChatPromptTemplate.from_template(
"""基于以下知识图谱信息回答问题:
{context}
问题: {question}
答案:"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"context": context, "question": question})
# 使用示例
grag = GraphRAG()
grag.build_knowledge_graph([
"张三是ABC公司的CEO,该公司位于北京",
"李四是ABC公司的CTO,他与张三是大学同学",
"ABC公司开发了产品X,市场份额领先"
])
answer = grag.query("ABC公司的领导层有哪些人?")
print(answer)
6. Self RAG
简介:Self RAG 赋予模型自我评估和自主决策的能力。它通过引入四个关键的反思标记(Retrieve/ISREL/ISSUP/ISUSE),让模型能够自主判断:当前问题是否需要检索外部知识?检索到的文档是否相关?生成的答案是否被检索内容所支持?答案对用户是否有用?模型会基于这些评估生成多个候选答案并进行综合评分,最终选择最优结果输出。
架构:
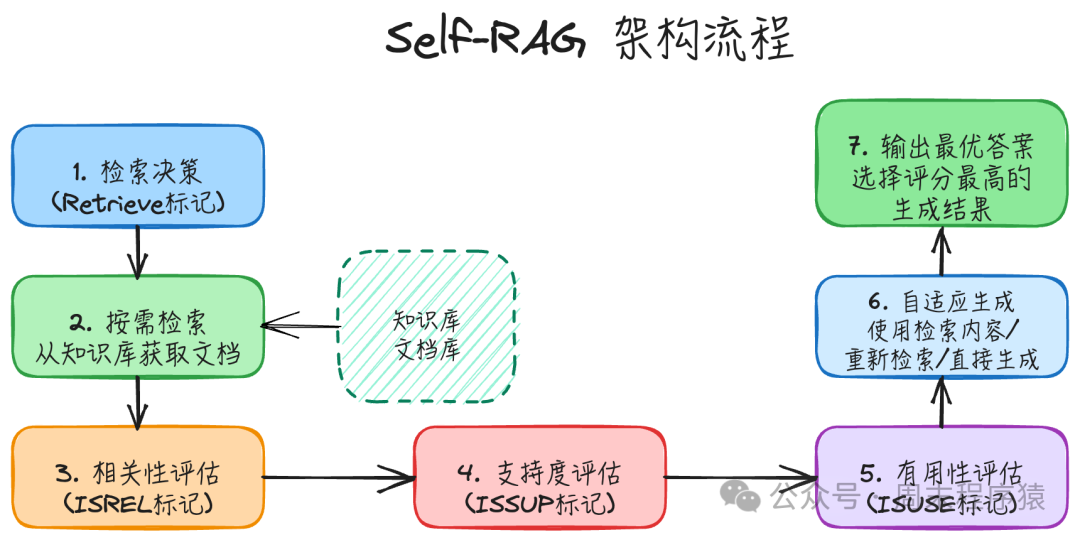
实现步骤:
- 检索决策:模型首先判断当前问题是否需要检索外部知识来回答(生成Retrieve标记)。
- 按需检索:如果判断需要检索,则从知识库中获取相关文档。
- 相关性评估:模型评估检索到的文档是否与用户查询真正相关(生成ISREL标记)。
- 支持度评估:模型评估自己生成的内容是否被检索到的文档所支持,是否有事实依据(生成ISSUP标记)。
- 有用性评估:模型评估生成的回答是否对用户真正有用、是否解决了问题(生成ISUSE标记)。
- 自适应生成:基于以上一系列的评估标记,模型动态决定是使用检索内容生成、重新检索还是直接依靠自身知识生成。
- 输出最优答案:模型会生成多个候选答案,并根据综合评分选择最优的一个作为最终输出。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import lancedb
from typing import List, Tuple
class SelfRAG:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0)
# 使用轻量级的all-MiniLM-L6-v2模型,仅80MB
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.db = lancedb.connect("/tmp/lancedb_self_rag")
self.vectorstore = None
def build_index(self, documents: List[str]):
"""构建向量索引"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="self_rag_docs"
)
def should_retrieve(self, query: str) -> bool:
"""判断是否需要检索 (Retrieve标记)"""
prompt = ChatPromptTemplate.from_template(
"""判断以下问题是否需要检索外部知识来回答。
问题: {query}
如果问题需要事实性知识、最新信息或特定领域知识,回答YES。
如果问题是通用问题或推理问题,回答NO。
只回答YES或NO:"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"query": query}).strip().upper()
return "YES" in response
def evaluate_relevance(self, query: str, document: str) -> Tuple[bool, float]:
"""评估文档相关性 (ISREL标记)"""
prompt = ChatPromptTemplate.from_template(
"""评估文档与问题的相关性,打分1-5分。
问题: {query}
文档: {document}
返回格式: 分数|理由
示例: 4|文档直接回答了问题的核心内容"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"query": query, "document": document})
try:
score = int(response.split("|")[0].strip())
return score >= 3, score / 5.0
except:
return True, 0.6
def evaluate_support(self, document: str, answer: str) -> Tuple[bool, float]:
"""评估答案是否被文档支持 (ISSUP标记)"""
prompt = ChatPromptTemplate.from_template(
"""评估答案是否被文档内容支持,打分1-5分。
文档: {document}
答案: {answer}
返回格式: 分数|理由"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"document": document, "answer": answer})
try:
score = int(response.split("|")[0].strip())
return score >= 3, score / 5.0
except:
return True, 0.6
def evaluate_usefulness(self, query: str, answer: str) -> Tuple[bool, float]:
"""评估答案有用性 (ISUSE标记)"""
prompt = ChatPromptTemplate.from_template(
"""评估答案对用户问题的有用程度,打分1-5分。
问题: {query}
答案: {answer}
返回格式: 分数|理由"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"query": query, "answer": answer})
try:
score = int(response.split("|")[0].strip())
return score >= 3, score / 5.0
except:
return True, 0.6
def generate_with_context(self, query: str, context: str) -> str:
"""基于上下文生成答案"""
prompt = ChatPromptTemplate.from_template(
"""基于以下上下文回答问题。如果上下文不足以回答,请说明。
上下文: {context}
问题: {query}
答案:"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"context": context, "query": query})
def generate_without_context(self, query: str) -> str:
"""不使用检索直接生成"""
prompt = ChatPromptTemplate.from_template("请回答以下问题: {query}")
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"query": query})
def query(self, question: str) -> str:
"""Self-RAG主流程"""
# 1. 检索决策
need_retrieval = self.should_retrieve(question)
if not need_retrieval:
# 直接生成
answer = self.generate_without_context(question)
_, usefulness = self.evaluate_usefulness(question, answer)
return answer
# 2. 检索文档
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke(question)
# 3. 对每个文档生成候选答案并评分
candidates = []
for doc in docs:
# 评估相关性 (ISREL)
is_relevant, rel_score = self.evaluate_relevance(question, doc.page_content)
if not is_relevant:
continue
# 生成答案
answer = self.generate_with_context(question, doc.page_content)
# 评估支持度 (ISSUP)
is_supported, sup_score = self.evaluate_support(doc.page_content, answer)
# 评估有用性 (ISUSE)
is_useful, use_score = self.evaluate_usefulness(question, answer)
# 综合评分
total_score = rel_score * 0.3 + sup_score * 0.4 + use_score * 0.3
candidates.append((answer, total_score))
# 4. 选择最佳答案
if candidates:
candidates.sort(key=lambda x: x[1], reverse=True)
return candidates[0][0]
else:
# 如果没有合适的检索结果,直接生成
return self.generate_without_context(question)
# 使用示例
srag = SelfRAG()
srag.build_index(["文档1内容...", "文档2内容...", "文档3内容..."])
answer = srag.query("你的问题是什么?")
print(answer)
7. Adaptive RAG
简介:Adaptive RAG 的核心思想是“因查询制宜”。它能够根据用户查询的类型和复杂程度,动态选择最优的处理策略。系统会先对查询进行分类,然后将其路由到最适合的RAG处理流程中。
架构:
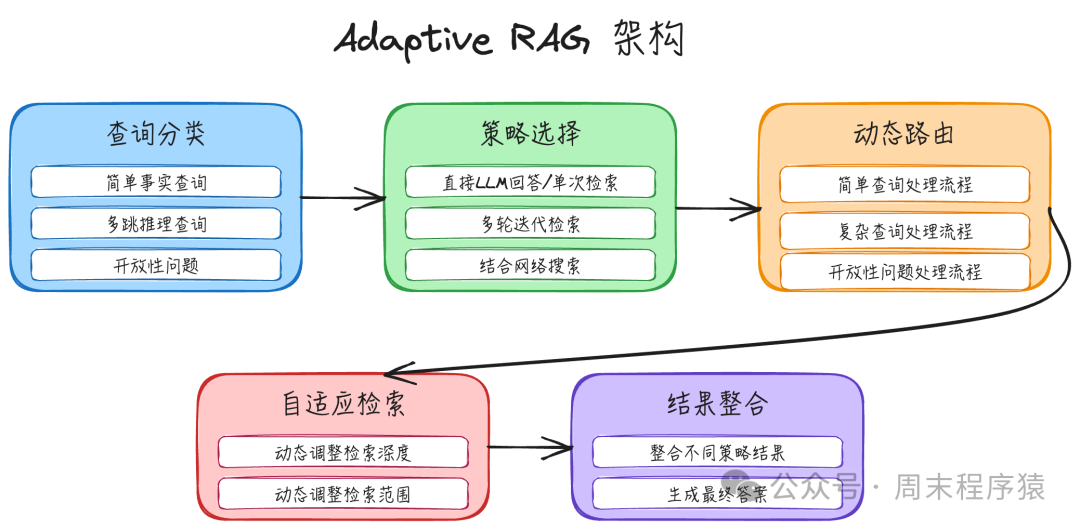
实现步骤:
- 查询分类:分析用户查询的类型和复杂度,通常分为:简单事实查询、多跳推理查询、开放性问题等。
- 策略选择:根据查询类型,从策略池中选择最优的RAG处理策略。
- 简单查询:采用直接LLM回答或单次检索的轻量级策略。
- 复杂查询:启用多轮迭代检索的策略,逐步收集信息。
- 开放性问题:结合网络搜索或广泛检索,获取更全面的背景信息。
- 动态路由:将分类后的查询自动路由到对应的处理流程模块。
- 自适应检索:在处理过程中,根据中间结果动态调整检索的深度(检索轮次)和范围(检索数量)。
- 结果整合:整合来自不同策略或不同轮次检索的结果,生成最终的统一答案。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain.schema import Document
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
import lancedb
from enum import Enum
from typing import List
class QueryType(Enum):
SIMPLE = "simple" # 简单事实查询
MULTI_HOP = "multi_hop" # 多跳推理查询
OPEN_ENDED = "open_ended" # 开放性问题
NO_RETRIEVAL = "no_retrieval" # 不需要检索
class AdaptiveRAG:
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4", temperature=0)
# 使用轻量级的all-MiniLM-L6-v2模型,仅80MB
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.db = lancedb.connect("/tmp/lancedb_adaptive_rag")
self.vectorstore = None
def build_index(self, documents: List[str]):
"""构建向量索引"""
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="adaptive_rag_docs"
)
def classify_query(self, query: str) -> QueryType:
"""分类查询类型"""
prompt = ChatPromptTemplate.from_template(
"""分析以下查询的类型,返回对应类别:
查询: {query}
类别说明:
- SIMPLE: 简单的事实性问题,可以直接从单个文档找到答案
- MULTI_HOP: 需要综合多个信息源进行推理的复杂问题
- OPEN_ENDED: 开放性问题,需要广泛的知识和创造性思考
- NO_RETRIEVAL: 通用知识问题,不需要检索即可回答
只返回类别名称(SIMPLE/MULTI_HOP/OPEN_ENDED/NO_RETRIEVAL):"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({"query": query}).strip().upper()
mapping = {
"SIMPLE": QueryType.SIMPLE,
"MULTI_HOP": QueryType.MULTI_HOP,
"OPEN_ENDED": QueryType.OPEN_ENDED,
"NO_RETRIEVAL": QueryType.NO_RETRIEVAL
}
return mapping.get(response, QueryType.SIMPLE)
def simple_rag(self, query: str) -> str:
"""简单RAG:单次检索"""
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 2})
prompt = ChatPromptTemplate.from_template(
"基于以下内容回答问题:\n{context}\n\n问题:{question}\n答案:"
)
def format_docs(docs):
return "\n".join([d.page_content for d in docs])
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| self.llm
| StrOutputParser()
)
return chain.invoke(query)
def multi_hop_rag(self, query: str, max_hops: int = 3) -> str:
"""多跳RAG:迭代检索"""
accumulated_context = []
current_query = query
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 2})
for hop in range(max_hops):
# 检索
docs = retriever.invoke(current_query)
accumulated_context.extend([d.page_content for d in docs])
# 检查是否已有足够信息
context = "\n".join(accumulated_context)
check_prompt = ChatPromptTemplate.from_template(
"""基于当前收集的信息,判断是否足够回答问题。
收集的信息: {context}
问题: {query}
回答YES如果信息足够,回答NO如果需要更多信息。
如果回答NO,请提供下一步应该搜索的子问题。
格式: YES 或 NO|子问题"""
)
check_chain = check_prompt | self.llm | StrOutputParser()
check_response = check_chain.invoke({"context": context, "query": query})
if check_response.strip().upper().startswith("YES"):
break
elif "|" in check_response:
current_query = check_response.split("|")[1].strip()
# 生成最终答案
final_context = "\n".join(accumulated_context)
final_prompt = ChatPromptTemplate.from_template(
"综合以下信息回答问题:\n{context}\n\n问题:{question}\n答案:"
)
final_chain = final_prompt | self.llm | StrOutputParser()
return final_chain.invoke({"context": final_context, "question": query})
def open_ended_rag(self, query: str) -> str:
"""开放性RAG:广泛检索+创造性生成"""
# 扩展查询
expand_prompt = ChatPromptTemplate.from_template(
"为以下问题生成3个相关的搜索查询:\n{query}\n查询列表:"
)
expand_chain = expand_prompt | self.llm | StrOutputParser()
expanded = expand_chain.invoke({"query": query})
queries = [query] + [q.strip() for q in expanded.split("\n") if q.strip()][:3]
# 多查询检索
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 2})
all_docs = []
for q in queries:
docs = retriever.invoke(q)
all_docs.extend([d.page_content for d in docs])
# 去重
unique_docs = list(set(all_docs))
context = "\n".join(unique_docs[:5])
final_prompt = ChatPromptTemplate.from_template(
"""基于以下信息,对问题给出全面、有见地的回答:
信息: {context}
问题: {question}
请提供详细的分析和见解:"""
)
final_chain = final_prompt | self.llm | StrOutputParser()
return final_chain.invoke({"context": context, "question": query})
def no_retrieval_generate(self, query: str) -> str:
"""直接生成:不使用检索"""
prompt = ChatPromptTemplate.from_template("请回答:{query}")
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"query": query})
def query(self, question: str) -> str:
"""自适应查询主流程 - 使用LangChain路由"""
# 1. 分类查询
query_type = self.classify_query(question)
print(f"查询类型: {query_type.value}")
# 2. 路由到对应策略
routing_map = {
QueryType.SIMPLE: self.simple_rag,
QueryType.MULTI_HOP: self.multi_hop_rag,
QueryType.OPEN_ENDED: self.open_ended_rag,
QueryType.NO_RETRIEVAL: self.no_retrieval_generate
}
return routing_map[query_type](question)
# 使用示例
arag = AdaptiveRAG()
arag.build_index(["公司财报数据...", "市场分析报告...", "行业趋势..."])
answer = arag.query("分析公司未来的发展前景") # 会被识别为OPEN_ENDED
print(answer)
8. SFR RAG
简介:SFR RAG(Salesforce Research RAG)代表了工业级高质量RAG的最佳实践。它集成了一系列经过验证的优化技术,包括使用经过指令微调的高性能Embedding模型(如BGE系列)、结合Cross-Encoder进行精细的重排序、对检索到的长上下文进行智能压缩、生成答案时附带引用来源,并对最终输出进行严格的质量控制。
架构:
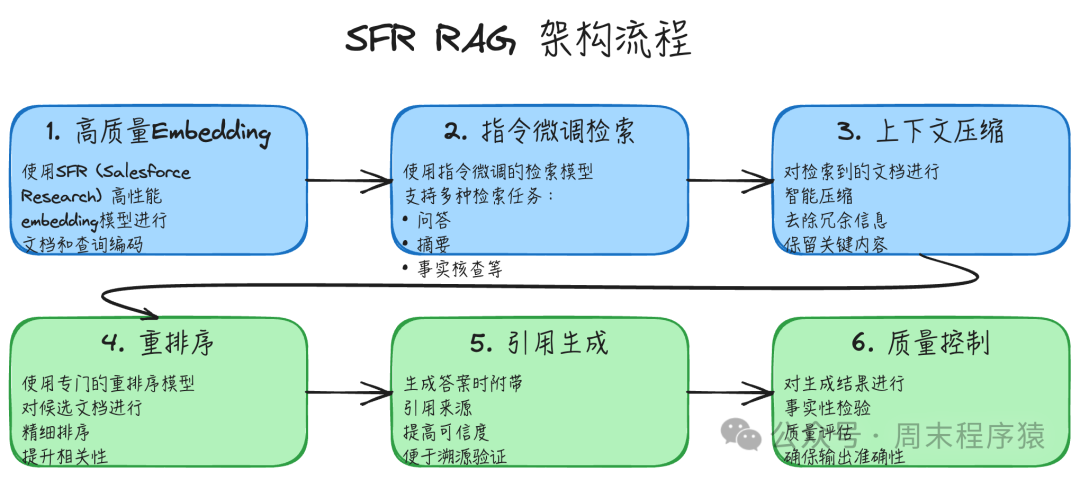
实现步骤:
- 高质量Embedding:使用如BGE(BAAI General Embedding)这类经过大规模指令微调的高性能模型进行文档和查询的向量编码,显著提升检索精度。
- 指令微调检索:检索模型本身经过多种下游任务(如问答、摘要、事实核查)的指令微调,使其更适应具体的应用场景。
- 上下文压缩:对初步检索到的大量文档进行智能压缩,自动去除冗余和无关信息,保留最核心的内容,以节省大语言模型的上下文窗口。
- 重排序:在初步的向量检索之后,使用专门的交叉编码器模型对候选文档列表进行精细化的相关性重排序,进一步提升Top结果的准确性。
- 引用生成:要求大语言模型在生成答案时,明确标注出所依据的文档来源编号,提高答案的可信度和可追溯性。
- 质量控制:对生成的最终答案进行自动化的事实性检验和质量评估,确保输出结果的准确性和可靠性。
参考代码:
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.vectorstores import LanceDB
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain.retrievers import ContextualCompressionRetriever
from langchain.schema import Document
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import lancedb
from typing import List, Dict
class SFRRAG:
def __init__(self):
# 使用BGE高质量Embedding模型
self.embeddings = HuggingFaceBgeEmbeddings(
model_name="BAAI/bge-large-en-v1.5",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True},
query_instruction="为检索任务生成查询表示: "
)
# 重排序模型
self.reranker_model = HuggingFaceCrossEncoder(
model_name="cross-encoder/ms-marco-MiniLM-L-6-v2"
)
self.llm = ChatOpenAI(model="gpt-5", temperature=0)
self.db = lancedb.connect("./lancedb_sfr_rag")
self.vectorstore = None
self.documents = []
def build_index(self, documents: List[str]):
"""构建高质量向量索引"""
self.documents = documents
docs = [Document(page_content=d) for d in documents]
self.vectorstore = LanceDB.from_documents(
docs,
self.embeddings,
connection=self.db,
table_name="sfr_rag_docs"
)
def get_retriever_with_reranker(self, top_k: int = 5):
"""创建带重排序的检索器"""
# 基础检索器
base_retriever = self.vectorstore.as_retriever(search_kwargs={"k": 10})
# 重排序压缩器
reranker = CrossEncoderReranker(
model=self.reranker_model,
top_n=top_k
)
# 组合检索器
return ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
def compress_context(self, query: str, documents: List[Document]) -> str:
"""上下文压缩"""
doc_texts = "\n".join([f"[{i+1}] {doc.page_content}"
for i, doc in enumerate(documents)])
prompt = ChatPromptTemplate.from_template(
"""提取以下文档中与问题相关的关键信息:
问题: {query}
文档:
{documents}
请返回压缩后的关键信息,保留文档编号以便引用:"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"query": query, "documents": doc_texts})
def generate_with_citations(self, query: str, context: str) -> str:
"""生成带引用的答案"""
prompt = ChatPromptTemplate.from_template(
"""基于以下上下文回答问题,并标注引用来源[1][2]等。
上下文: {context}
问题: {query}
要求:
1. 准确回答问题
2. 在相关陈述后标注引用来源
3. 如果上下文不足以回答,请说明
答案:"""
)
chain = prompt | self.llm | StrOutputParser()
return chain.invoke({"context": context, "query": query})
def verify_answer(self, query: str, answer: str, documents: List[Document]) -> Dict:
"""验证答案质量"""
doc_contents = [doc.page_content for doc in documents]
prompt = ChatPromptTemplate.from_template(
"""评估以下答案的质量:
问题: {query}
答案: {answer}
参考文档: {documents}
评估维度(1-5分):
1. 准确性:答案是否被文档支持
2. 完整性:答案是否全面回答了问题
3. 相关性:答案是否紧扣问题
返回格式: 准确性分数|完整性分数|相关性分数|总评"""
)
chain = prompt | self.llm | StrOutputParser()
response = chain.invoke({
"query": query,
"answer": answer,
"documents": doc_contents
})
try:
parts = response.split("|")
return {
"accuracy": int(parts[0].strip()),
"completeness": int(parts[1].strip()),
"relevance": int(parts[2].strip()),
"summary": parts[3].strip() if len(parts) > 3 else ""
}
except:
return {"accuracy": 3, "completeness": 3, "relevance": 3, "summary": ""}
def query(self, question: str) -> Dict:
"""SFR-RAG主流程"""
# 1. 初始检索 + 重排序
retriever = self.get_retriever_with_reranker(top_k=5)
docs = retriever.invoke(question)
# 2. 上下文压缩
compressed_context = self.compress_context(question, docs)
# 3. 生成带引用的答案
answer = self.generate_with_citations(question, compressed_context)
# 4. 质量验证
quality = self.verify_answer(question, answer, docs)
return {
"answer": answer,
"sources": [{"content": doc.page_content[:100]} for doc in docs],
"quality": quality
}
# 使用示例
sfr_rag = SFRRAG()
sfr_rag.build_index([
"人工智能是计算机科学的一个分支...",
"机器学习是AI的核心技术之一...",
"深度学习使用神经网络进行学习..."
])
result = sfr_rag.query("什么是人工智能?")
print(f"答案: {result['answer']}")
print(f"质量评估: {result['quality']}")
参考
 发表于 2026-1-20 02:37:50
|
查看: 232|
回复: 0
发表于 2026-1-20 02:37:50
|
查看: 232|
回复: 0
