一直以来,英伟达都是自动驾驶领域不可或缺的关键先生。从用于模型训练的H200、GB300,到用于车端推理的Xavier、Orin、雷神Thor,其琳琅满目、代代跃迁的芯片产品,始终是方案供应商和车企们的首选。
不过,从AI三要素——算力、算法、数据的角度——来看,英伟达的主要角色始终是一个算力供应商。算法层面,英伟达早在2016年便布局端到端神经网络,甚至早于特斯拉,却未大力投入推进工程化落地,长期停留在“探索”阶段。数据层面,尽管其Cosmos世界基础模型平台能合成高度多样化的模型训练数据,但英伟达在数据规模与闭环应用上存在感不强。
在近日的CES 2026展上,英伟达一口气开源了Alpamayo系列VLA推理模型、仿真工具AlpaSim和数据集,似乎在一定程度上补齐了算法和数据短板。豪横开源之后,“削平自动驾驶门槛”、“挑战特斯拉FSD”等观点频现。事实究竟如何?
开源数据集价值高吗?
数据,被喻为人工智能时代的“石油”,是驱动AI进化的核心资产。但对于头部玩家来说,英伟达此次开源的数据集价值可能并不像看起来那么高。
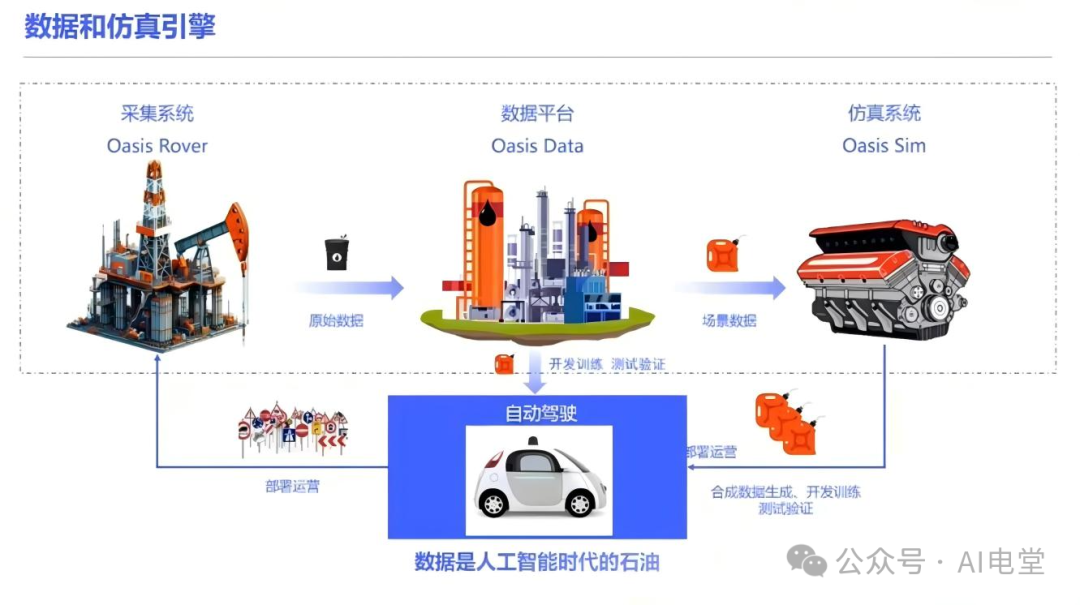
图片来源:中国科技大学
首先看数据规模。英伟达此次开源了1700个小时的驾驶数据,乍看很有噱头,但与特斯拉FSD积累的上亿段用于模型训练的视频片段(Clips)相比,差距悬殊。若按每个片段约三十秒计算,特斯拉对应的数据量预估高达83.33万小时,两者规模相差约五百倍!
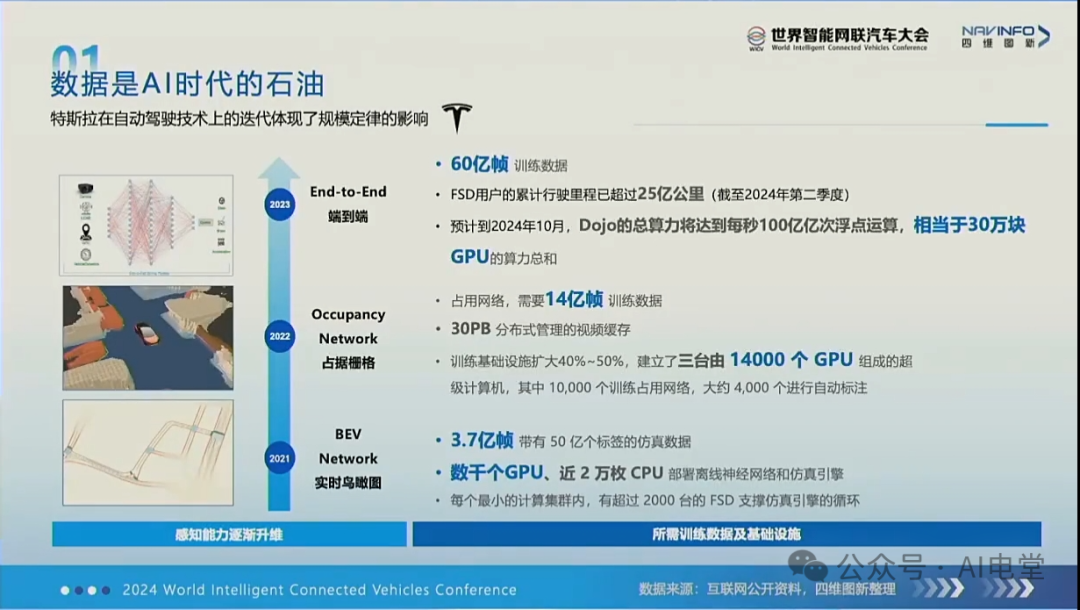
图片来源:2024世界智能网联汽车大会,四维图新
再看数据价值。在端到端自动驾驶时代,数据的核心价值在于为特定模型挖掘和补齐长尾案例(Corner Case)。评价数据价值的高低,关键在于它能否精准地补上该模型迭代过程中的短板。不同公司的模型架构、传感器方案、训练策略各异,其知识盲区和薄弱环节也各不相同,对A模型构成挑战的长尾场景,对B模型可能只是普通场景。
对头部自动驾驶玩家而言,其数据工作的核心是构建深度融合云计算和人工智能大模型的高效数据闭环与工具链,在PB、EB级别的海量原始数据中,精准筛选出适配自家模型的高价值内容。既然数据需要如此“精挑细选”和“精准挖掘”,那么一个面向全行业的、通用的开放数据集,其对于特定玩家的实用价值有多大,答案不言自明。
开源模型作用大吗?
坦白说,英伟达开源的Alpamayo VLA推理模型对业界头部玩家的实用价值可能有限。原因有三:一是其时空认知能力存在短板,这在自动驾驶任务中是致命的;二是参数规模过大,难以实车部署;三是头部玩家的核心竞争力在于私有数据闭环+自研专用硬件+专有模型的深度绑定,不太可能为一个外部半成品模型而改弦更张。
早在2025年12月初,英伟达就开源了Alpamayo-R1,其核心正是专为物理AI打造的Cosmos Reason视觉语言模型。这款模型于同年8月推出,是一款经过海量视觉问答任务预训练的具身智能推理模型,后续还针对自动驾驶任务进行了强化学习。得益于其基于VLM的特性,该模型具备很强的概念认知能力、复杂场景理解和逻辑推理能力,但美中不足的是其时空认知能力偏弱。

图片来源:谷歌
自动驾驶智能体与真实世界交互的核心是三维空间和一维时间。不仅“空间”本身用语言极难精确描述,“时间”的严格序列性和因果关系更是传统语言模型的能力短板。因此,一个合格的自动驾驶智能体必须具备与“概念认知”并行的“时空认知”能力,能够学习物理规律、理解时空变化。这样一来,时空认知能力较弱的世界模型,就难以补齐自动驾驶智能体与真实世界交互的短板,其开源的实际价值自然大打折扣。
再看模型规模的硬伤。Alpamayo-R1参数规模高达100亿,即便使用了非车规的顶级计算卡RTX 6000 Pro Blackwell,也只跑出了约10Hz的帧率(端到端延迟约99毫秒)。相比之下,特斯拉端到端模型的运行频率是36Hz,差距一目了然。
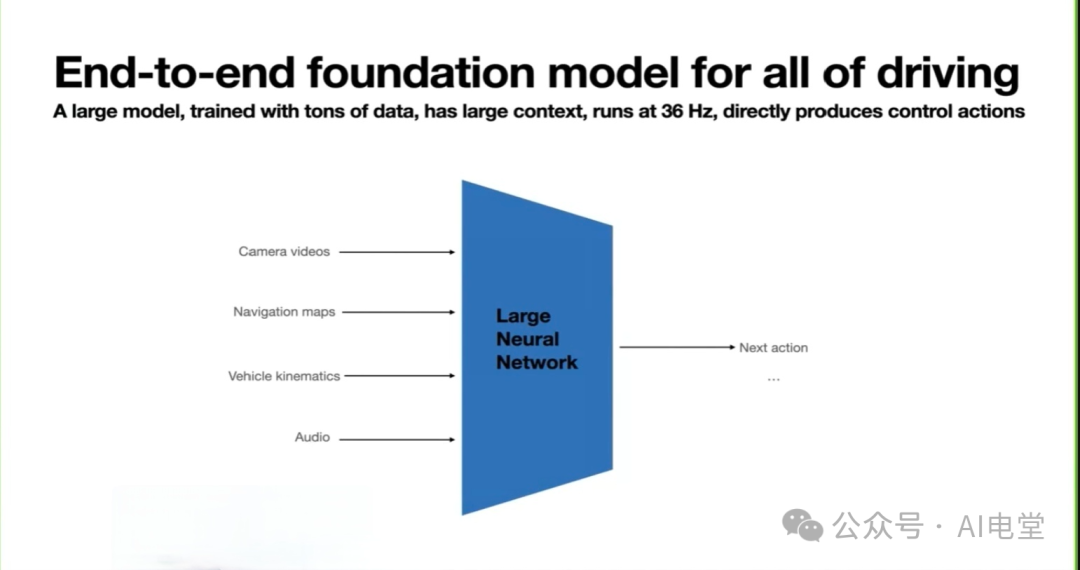
图片来源:特斯拉
或许有人认为,通过剪枝、量化、压缩等模型轻量化技术,可以将如此庞大的模型部署到车端;或者通过流式视频编码器、投机采样、GPTQ等优化技术来提升其运行频率。这种思路,或许低估了自动驾驶系统工程的复杂性。对于特斯拉、华为、小鹏、理想、蔚来这些手握自研算法栈、成熟数据闭环和车规级硬件平台的头部玩家而言,他们更不可能舍近求远,去费力优化部署一个外部的通用模型。
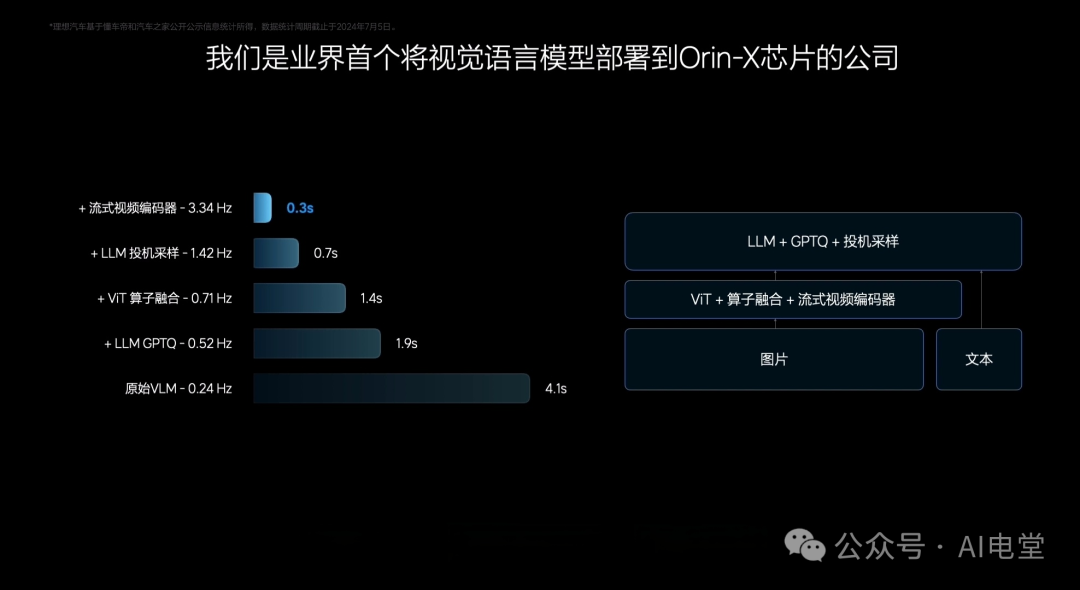
图片来源:理想汽车
首先,头部玩家深耕多年,早已搭建起完整的技术闭环,其核心优势就在于算法与芯片的深度耦合所带来的高度定制化性能。这种性能优势是通用硬件平台和通用模型难以比拟的。因此,他们会持续迭代自研的专有模型,而非引入一个可能与自家硬件架构格格不入的外部模型。
其次,如前所述,数据的核心价值是为特定模型精准地补齐长尾场景短板。头部玩家拥有海量、优质的私有车辆数据,这些数据与其自研模型的知识盲区高度相关,价值巨大。而若使用一个外部通用模型,则需要将其庞大的、与自身数据分布不完全匹配的先验知识“蒸馏”到自家系统中,这个过程不仅效率低下,反而可能稀释了自身数据闭环的独特价值。
当然,英伟达Alpamayo系列模型也并非毫无价值。它可以为行业带来一些方法论上的启示,也可以作为模型能力的一个对标基准,帮助车企或方案供应商横向评估自家模型在复杂推理、场景理解等维度的能力水平,发现自身技术的相对优劣。
或许有人会问,这个模型对非头部玩家有价值吗?但我们可以思考一下,在未来几年技术路线日益收敛、资源消耗巨大的竞争环境下,非头部玩家的生存空间究竟在哪里?或许,这个问题本身就已经揭示了答案。
英伟达推销工具链的目的是什么?
常言道“醉翁之意不在酒”。在英伟达此次开源的三件套——VLA推理模型Alpamayo、自动驾驶数据集、仿真工具AlpaSim中,AlpaSim的存在感看似最低,却恰恰是此次开源策略的关键所在。其真正目的,是借助AlpaSim这个“开源鱼饵”,推广其背后更为宏大的Cosmos和Omniverse生态系统。
要知道,AlpaSim虽然是一个完全开源的端到端高保真自动驾驶仿真框架,但它并非孤立存在的工具。当开发者尝试用它来实现大规模、高保真的合成数据生成和复杂场景测试时,会自然而然地被引导至其背后更强大的平台——Cosmos世界基础模型和Omniverse数字孪生平台。
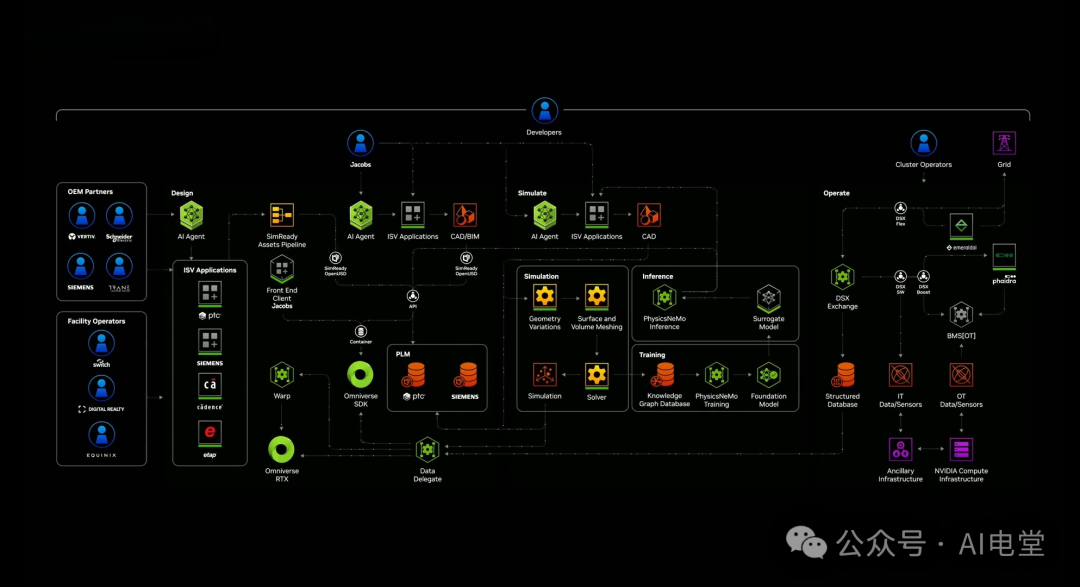
图片来源:英伟达
Cosmos堪称解决数据稀缺与长尾难题的“终极答案”之一。多年来,自动驾驶发展的一大瓶颈就是获取真实、多样且能覆盖各类长尾场景的数据。这些数据不仅获取成本高昂,且风险极大。Cosmos世界基础模型的推出,正是为了从根本上解决这一问题。当模型训练遇到数据瓶颈或需要极端场景时,开发者可以调用Cosmos世界模型来生成基于物理学的、可控的逼真合成数据。这意味着,你可以按需“制造”出暴雨、暴雪、极端拥堵甚至交通事故等罕见但关键的训练场景,而无需在真实世界中“守株待兔”,直接解决了长尾场景数据稀缺的难题。

图片来源:英伟达
Omniverse则被黄仁勋称为“构建和运营物理真实数字孪生的操作系统”,它提供了承载驾驶场景、进行高保真仿真和闭环测试的虚拟环境。它深度融合了英伟达在实时渲染、计算机视觉、物理仿真、运动模拟、传感器模拟等领域数十年的技术积累。在Omniverse中,开发者可以构建与真实世界无限接近的虚拟环境,让自动驾驶系统在其中进行安全、可重复的极限测试,在这个“安全的平行世界”里反复试验、不断学习。
一旦行业对“使用Cosmos生成数据、在Omniverse中进行仿真测试”这一开发模式形成依赖,对英伟达GPU和超算系统的需求将迎来指数级增长。这就完美地将软件生态的繁荣转化成了硬件销售的持续动力。毕竟,无论是部署和运行庞大的Cosmos模型,还是在Omniverse中进行实时高保真仿真,都离不开超强算力的支撑。而算力,正是英伟达的根基所在。
写在最后
明修栈道,暗度陈仓。英伟达在CES 2026上的慷慨开源,表面看是通过数据集和VLA推理模型推动自动驾驶技术的平权与普及,其深层的商业逻辑和战略目的,却是将整个自动驾驶乃至更广阔的物理AI产业,更深地卷入其以Cosmos(合成数据生成)和Omniverse(数字孪生仿真)为核心、以超级算力为基座的宏大生态系统中。
开源是吸引开发者的“鱼饵”,而打造一个繁荣、封闭且具有高度粘性的软硬件生态系统,才是藏在鱼饵里的那个“钩”。对于技术决策者和开发者而言,理解这盘棋局的真正走向,或许比争论某个开源模型本身的价值更为重要。欢迎在云栈社区继续探讨自动驾驶与人工智能的未来趋势。
 发表于 2026-1-20 05:53:08
|
查看: 177|
回复: 0
发表于 2026-1-20 05:53:08
|
查看: 177|
回复: 0
