如果你曾使用Claude Code或类似的AI编程助手,可能会遇到一个痛点:为了让AI生成符合特定要求的代码或设计,你不得不在每次对话中重复输入一长串的、详细的指令。
例如,你想让Claude Code开发一个“美观”的博客网站。如果不加任何约束,它给出的结果可能只是一个功能齐全但设计普通的界面。
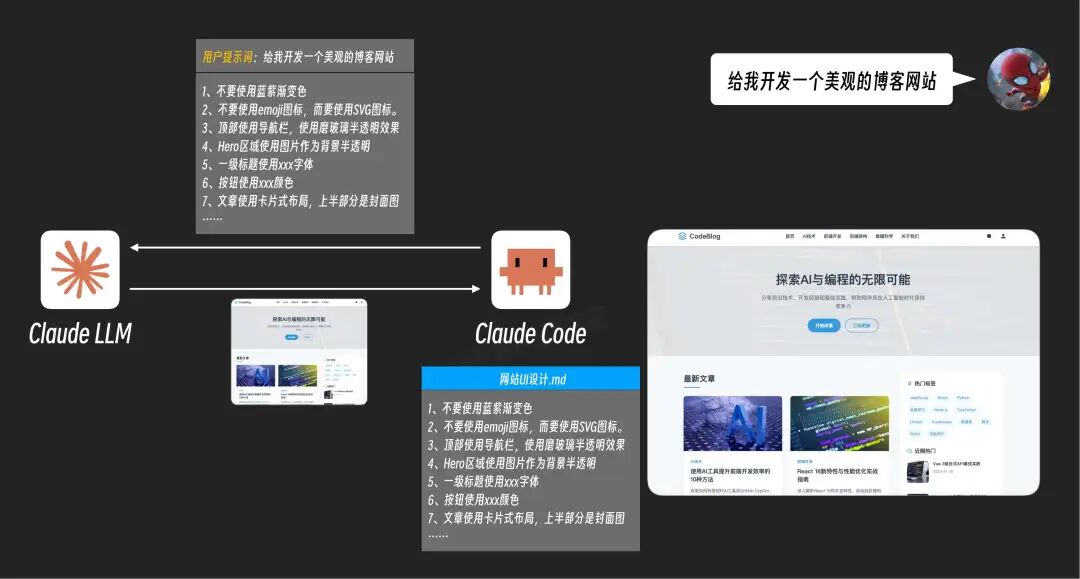
为了让结果更符合你的审美,你不得不补充一大堆具体要求:
1、不要使用蓝紫渐变色
2、不要使用emoji图标,而要使用SVG图标。
3、顶部使用导航栏,使用磨砂玻璃半透明效果
4、Hero区域使用图片作为背景半透明
5、一级标题使用xxx字体
6、按钮使用xxx颜色
7、文章使用卡片式布局,上半部分是封面图
......
当你把这些要求详细告知Claude Code后,它重新生成的网站设计在美观度上通常会有显著提升。
但问题随之而来:我不想在每次开始新项目时都重复输入这些冗长的指令。能否让Claude Code“记住”我的偏好,实现一劳永逸呢?
从静态文档到动态技能库
Claude Code提供了一种基础的解决方案:你可以将这些要求整理成一个单独的Markdown文件。之后,当Claude Code与AI大模型交互时,会把这个文件的内容一并发送给AI,这样就不必每次都重写指令了。
然而,这种方法存在新的效率问题。如果我只是进行普通的聊天或提问,并非开发网站,Claude Code也会把这个庞大的UI设计文档发送给AI,这无疑会浪费大量宝贵的上下文Token。
那么,能否优化这个流程,实现按需加载,只在真正需要时才发送相关文档呢?
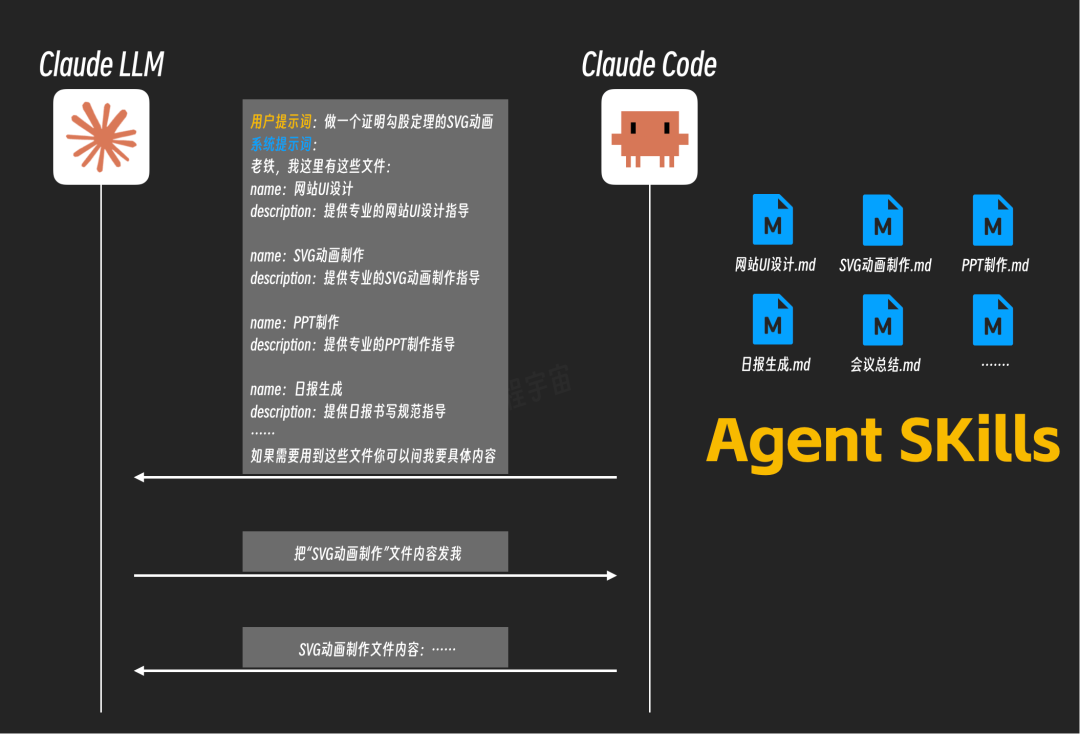
答案是肯定的。我们可以在文档的开头部分添加元数据(Metadata),例如名称(name)和描述(description),用简单的文字说明这个文档是做什么的。

这样,Claude Code在与AI沟通时,可以先告诉AI:“我这里有一个名为‘网站UI设计’的文档,它提供了专业的网站UI设计指导。如果你需要,可以向我索取具体内容。”
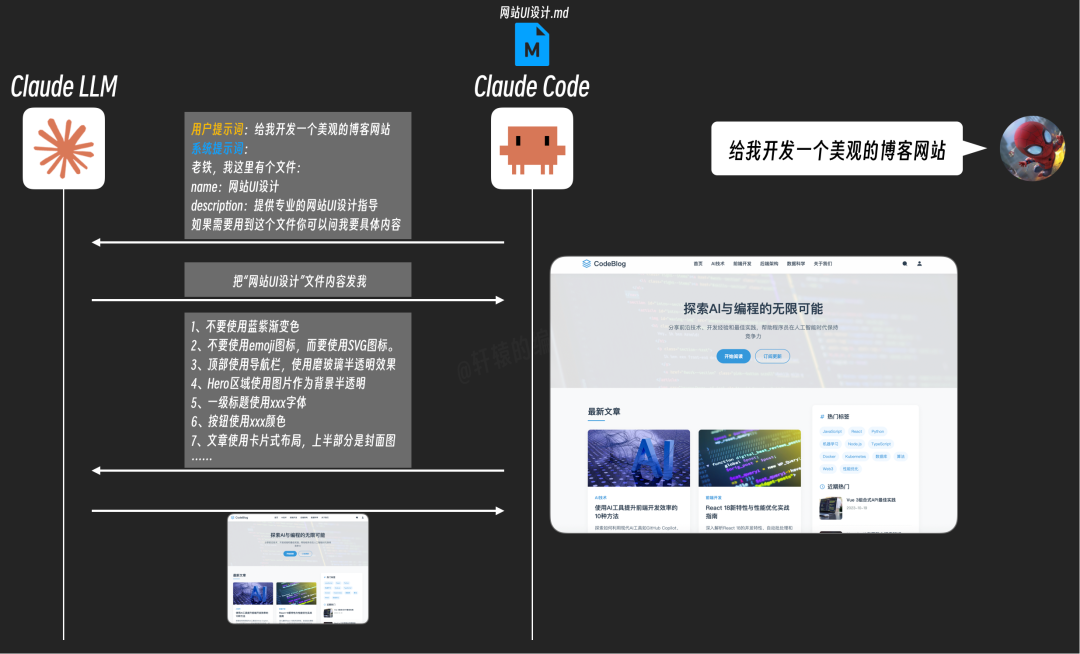
当AI接收到用户“开发网站”的指令后,它才会向Claude Code请求加载这个具体的文档。这种机制有效避免了无关文档对上下文的无效占用。
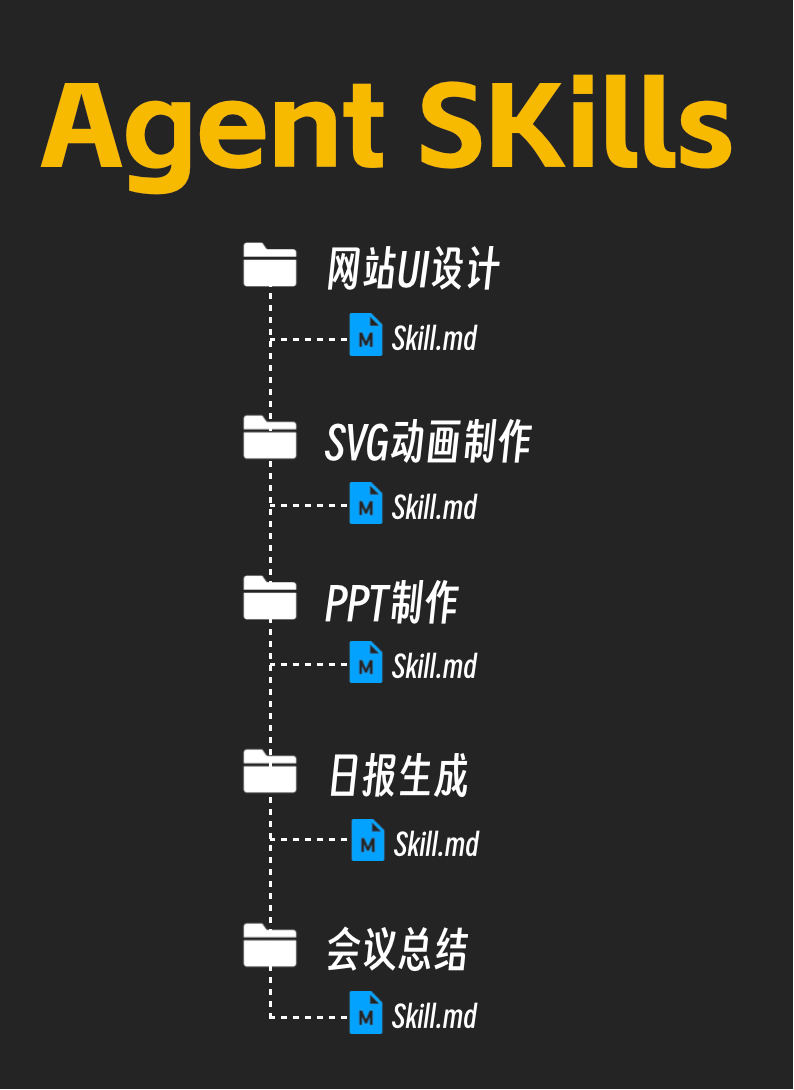
这一模式被证明非常有效。你可以如法炮制,创建一系列针对不同任务的文档,例如:
SVG动画制作.md: 指导AI制作网页SVG动画。PPT制作.md: 指导AI制作美观的PPT。日报生成.md: 指导AI书写符合公司规范的工作日报。

Claude Code在与AI交互时,只需将这些文档的名称和描述作为一个技能目录告知AI。AI会根据用户的实时指令,动态决定加载和使用哪些技能。
这样一来,同样的大模型,因为配备了这样一套技能库,就比“裸奔”的AI更擅长完成特定领域的任务——它更懂UI设计、更会做动画、更擅长写报告。
这套技术的核心概念,就是 Agent Skills(智能体技能)。每一个Markdown文档,都是一个独立的“Skill”(技能),即一本专项工作手册,指导AI智能体完成特定任务。
技能的结构化与渐进式加载
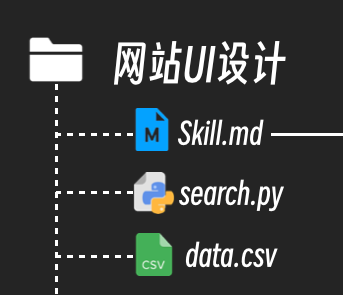
为了规范管理,Claude Code通常以文件夹的形式组织这些技能,并将每个技能的核心文件统一命名为 Skill.md。
以“网站UI设计”这个技能为例,随着经验的积累,Skill.md 文件可能变得越来越臃肿,因为包含了简约风、科技风、小清新风等数十种风格的详细要求。但实际任务中,AI可能只需要其中一种风格的信息,其余大部分内容都成了无用的Token开销。
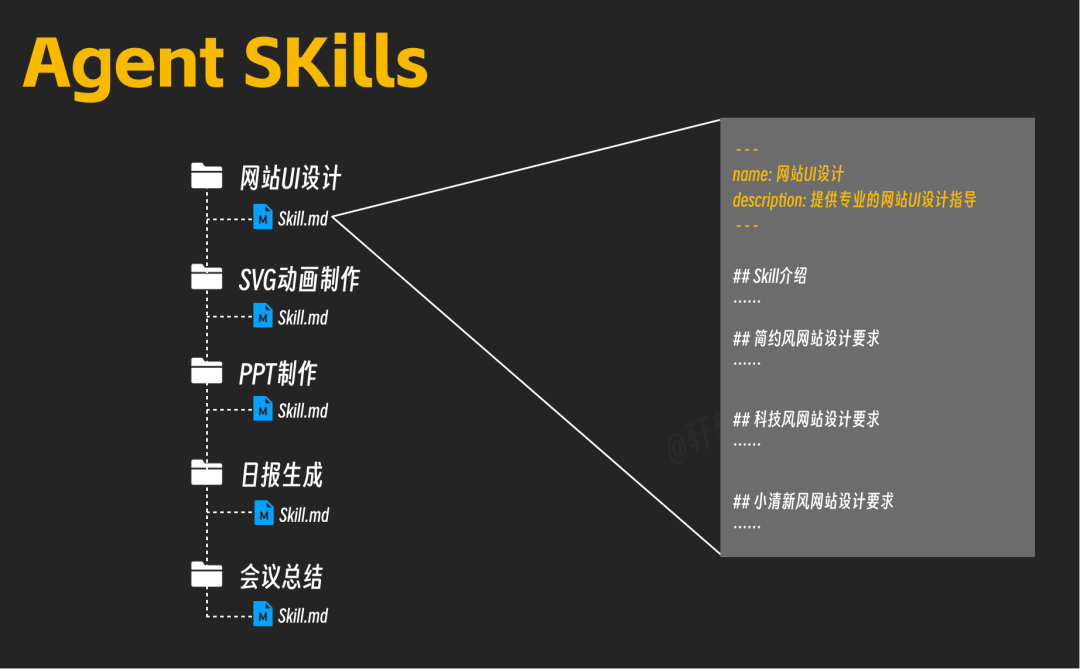
为了解决这个问题,可以进行模块化改造。将每种风格的具体要求拆分到独立的文件中(如 简约风.md、科技风.md),在主 Skill.md 文件中只保留索引和调度逻辑,例如:
- 如果要做简约风网站就读取《简约风.md》
- 如果要做科技风网站就读取《科技风.md》
- 如果要做小清新风格网站就读取《小清新.md》

当用户要求制作一个“科技风的博客网站”时,AI会先加载主 Skill.md 文件,然后根据其中的指引,再按需加载 科技风.md 这个子文档。
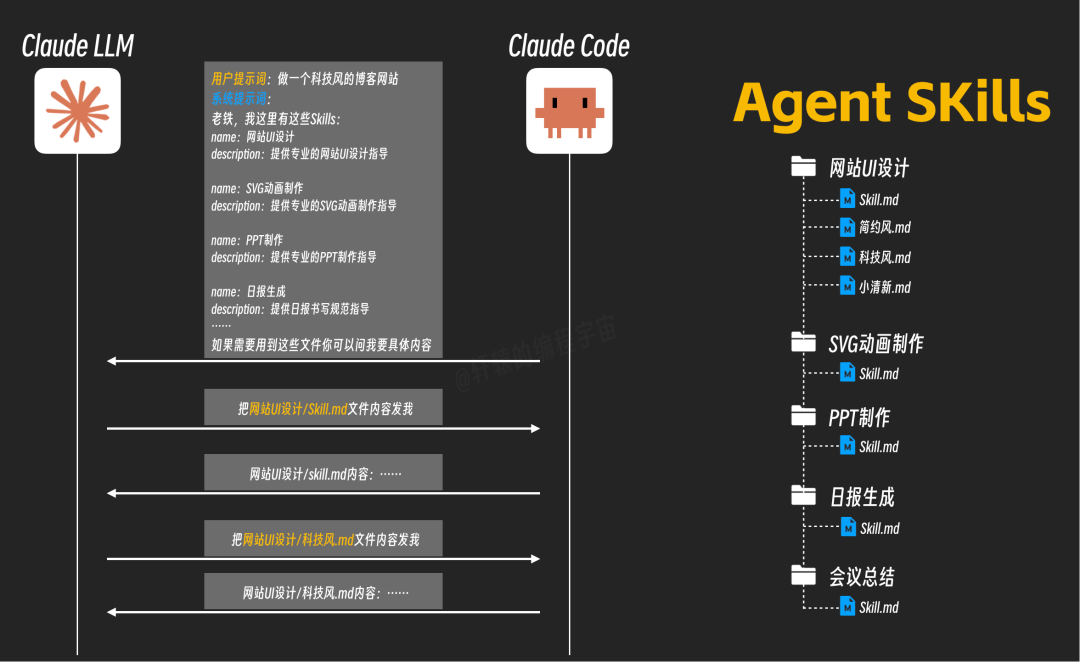
这种渐进式加载机制,让Token的使用变得极为高效。
从文档到工作流:技能的进化
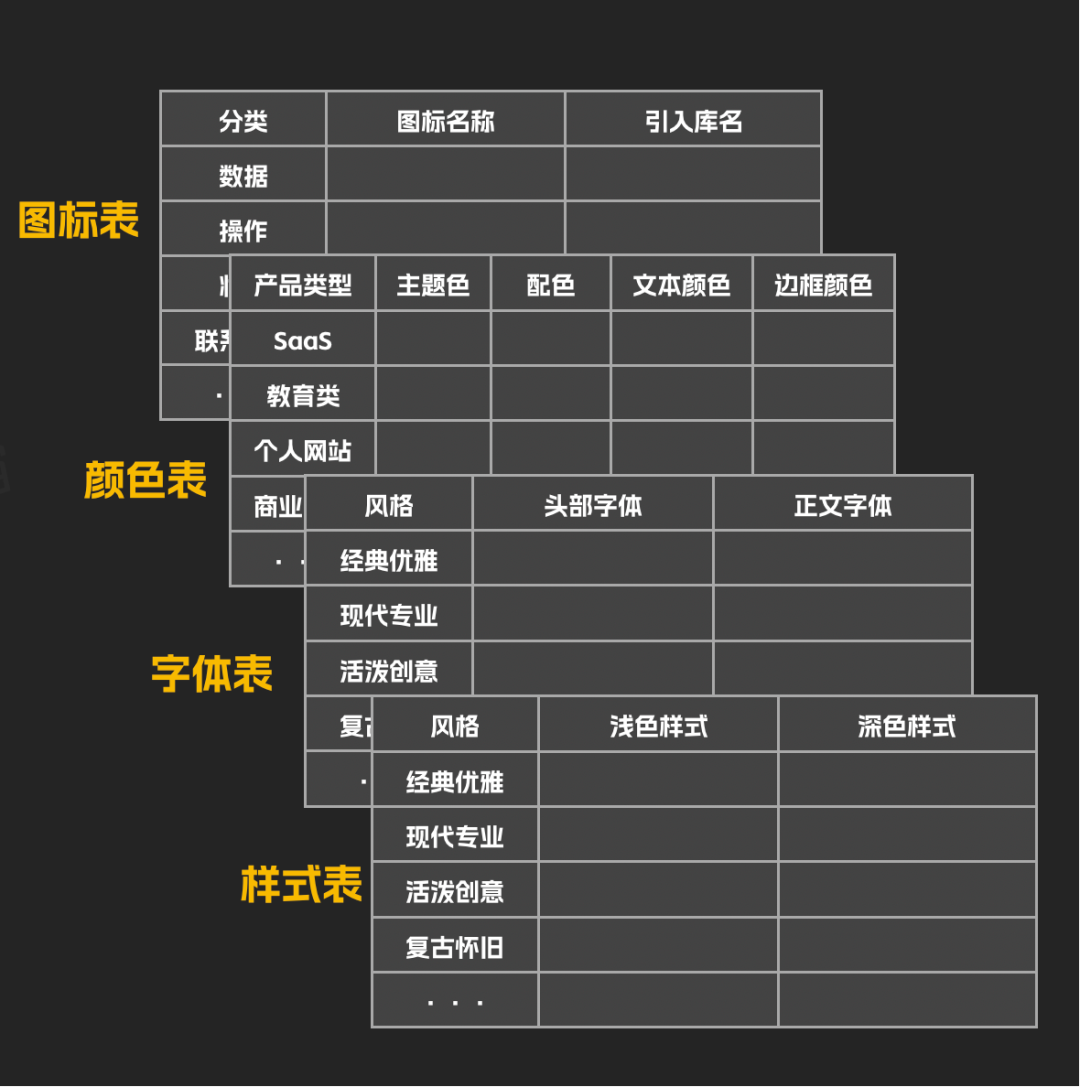
随着任务复杂度的提升,仅靠文档已不足以描述精细的工作流程。例如,对于UI设计,你可能需要管理图标、配色、字体、图表等大量细粒度元素。
这时,可以用结构化的数据文件(如CSV表格)来管理这些资源。
同时,你可以在 Skill.md 中定义一套完整的工作流,指导AI如何一步步完成任务。例如:
- 分析用户需求:确定网站类型和风格。
- 搜索相关领域:根据需求在资源库中检索。
- 搜索技术栈指南:获取实现该风格的技术建议。
- 交付前检查:核对最终方案。

为了让AI能执行搜索,你甚至可以编写一个Python脚本,并在技能文档中告诉AI如何调用这个脚本,从CSV表格中检索出符合条件的设计元素。
此时,AI大模型在Claude Code的配合下,不再仅仅是阅读一个参考文档。它会遵循你定义的流程,执行你提供的工具(如Python脚本),动态获取所需信息,最终完成复杂的开发任务。技能从一个静态的“说明书”,进化成了一个动态的、可执行的“工作流引擎”。
上文所描述的,并非虚构场景,而是一个在 GitHub 上获得了超过16K Star的真实开源项目所实现的 Agent 技能。
这个技能正是通过上述原理,让Claude Code这类智能体能够开发出UI更加美观、专业的产品。
Agent Skills 技术原理总结
最后,让我们系统地梳理一下Agent Skills的技术构成:
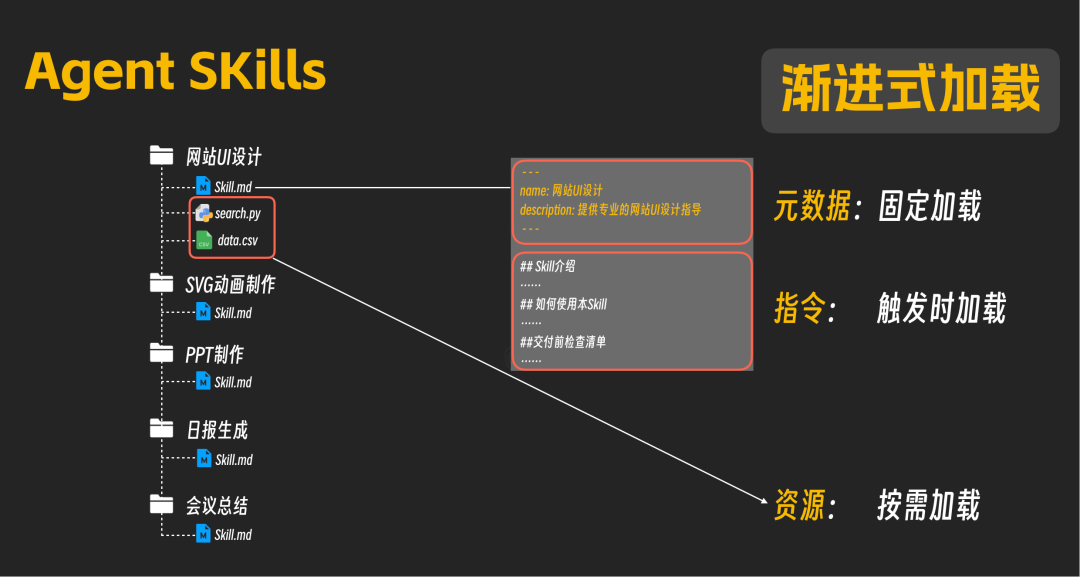
- 元数据(Meta Data):每个Skill的核心
Skill.md 文件开头都必须包含name和description等元数据字段。Claude在启动时会加载所有技能的元数据并放入系统提示词。由于元数据简短,占用Token极少。
- 指令(Instructions):即
Skill.md 文件中元数据之后的主体内容。它是一段精心设计的提示词,用于指导AI执行特定任务。这部分内容仅在AI判定需要使用该技能时才会被加载,即“触发时加载”。
- 资源与代码(Resources & Code):与技能相关的其他文件,如图片、数据文件(CSV)、可执行脚本(Python)等。这些资源仅在技能指令执行过程中确需使用时才会被动态加载,即“按需加载”。
本质与展望
归根结底,Anthropic推出的Agent Skills技术,是提示词工程(Prompt Engineering)的一种高级和规范化应用。它与模型上下文协议(MCP)等概念有相似之处,核心都是为了更高效、更结构化地扩展和大模型的能力。
无论是Agent Skills还是MCP,其本质都是符合特定规范的、相对复杂的提示词工程实践。引入“技能”、“资源”、“按需加载”等技术名词,主要是为了便于规范管理、降低使用复杂度并优化性能(尤其是Token使用效率)。
通过构建和分享高质量的Skill,开发者们正在共同创建一个丰富的、可复用的 智能体能力生态。这不仅能极大提升个人使用AI的效率,也为未来更多复杂、自动化的 AI应用 开发铺平了道路。
 发表于 2026-1-20 08:29:58
|
查看: 321|
回复: 0
发表于 2026-1-20 08:29:58
|
查看: 321|
回复: 0
