当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?短短一个词,背后承载了完全不同的购买意图。推荐的精准度,直接决定了用户的搜索体验和平台的转化效率。
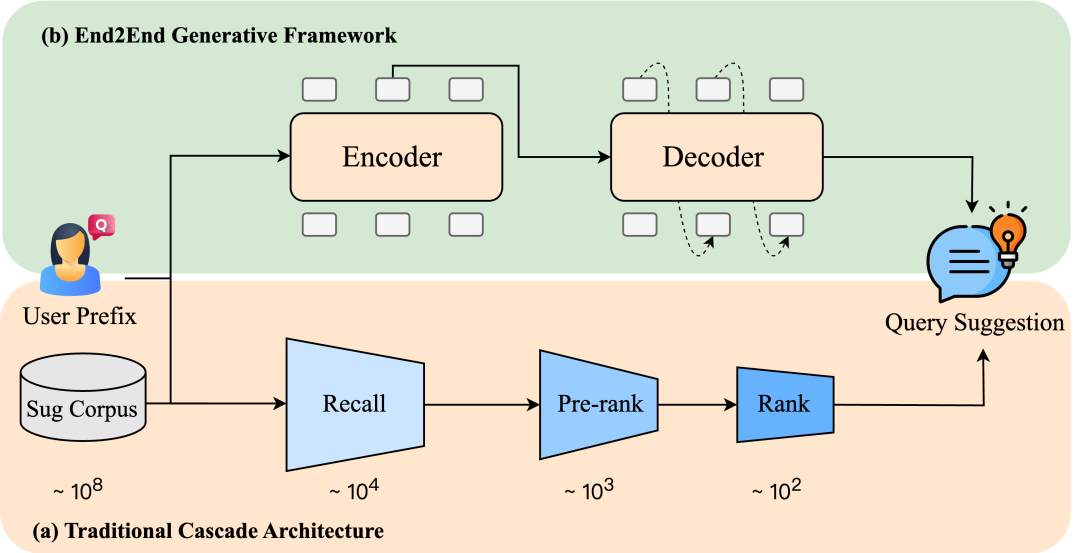
查询推荐是现代电商搜索系统中的核心功能,它通过在用户输入过程中实时推荐相关查询,帮助用户快速明确意图。传统方法通常采用多阶段级联架构,虽然在效率与效果之间取得了一定平衡,但也存在各阶段目标不一致、长尾查询召回困难等固有局限。
针对这些问题,快手技术团队在业界首次提出了端到端的生成式统一查询推荐框架——OneSug。该框架成功将召回、粗排、精排等多个阶段统一在一个生成模型中,显著提升了推荐效果与系统效率。本工作相关成果《OneSug: The Unified End-to-End Generative Framework for E-commerce Query Suggestion》已被人工智能顶级会议 AAAI 2026 接收。

论文链接: https://arxiv.org/abs/2506.06913
一、研究背景
传统的查询推荐系统通常采用多阶段级联架构,依次进行召回、粗排和精排。该架构带来了几个明显的局限性:
- 级联式框架:前一链路的性能决定了下一链路的性能上限。
- 目标不一致:召回、排序分离的技术迭代范式,难以实现全链路统一目标的优化。
- 长尾难题:缺乏历史行为数据的长尾前缀,难以召回高质量的查询(Query)。
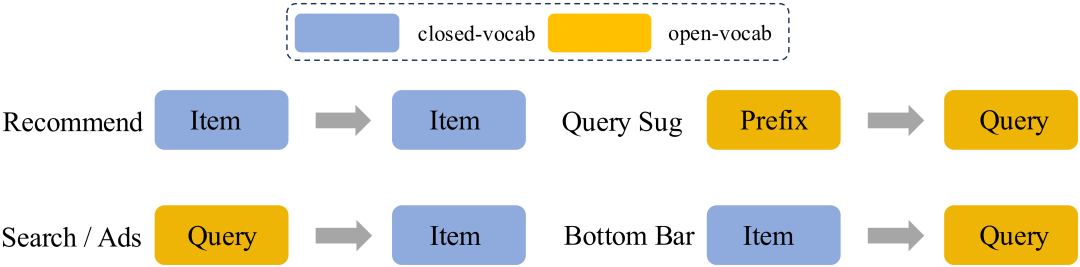
近年来,生成式检索因其强大的语义理解与生成能力,在搜索推荐领域展现出巨大潜力。然而,现有方法多聚焦于视频推荐(本质上是开集到开集的任务),难以直接应用于输入输出均为开放词表的查询推荐场景。
二、方法简介:OneSug 的三大核心模块
针对上述挑战,OneSug 模型应运而生。其整体架构包含以下三个核心部分:
- Prefix-Query表征增强模块
- 统一的编码器-解码器生成架构
- 用户行为偏好对齐模块
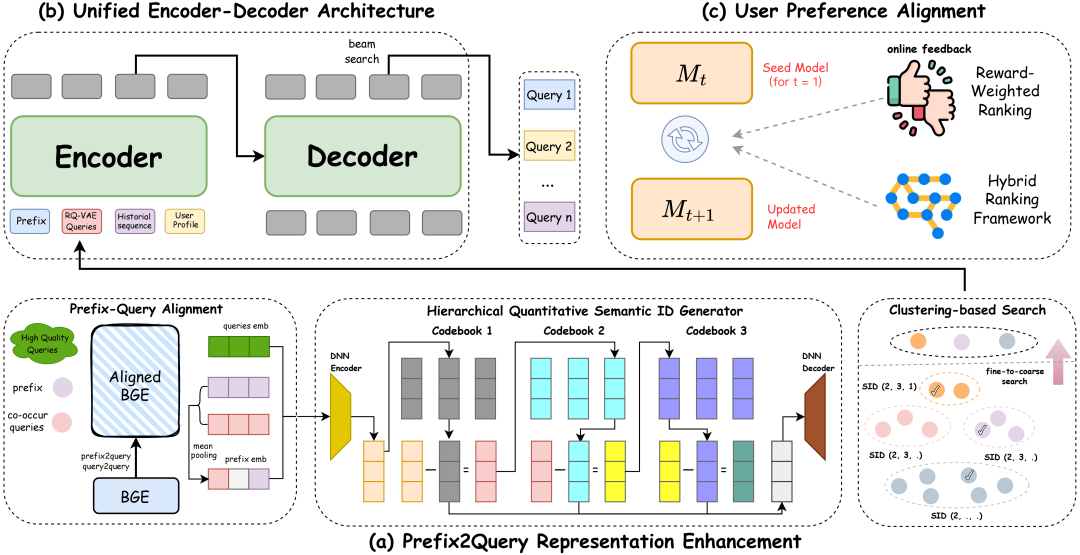
2.1 Prefix-Query表征增强模块
在查询推荐场景下,用户输入的前缀往往较短且意图模糊。为此,OneSug 设计了以下两个部分来解决:
- 语义与业务空间对齐:以 BGE 作为基础模型,引入用户真实的 prefix2query、query2query 数据,使用对比学习对模型进行微调,使其语义空间与快手电商的业务特征空间对齐。
- 层次化语义ID生成:在对齐的语义空间基础上,引入 RQ-VAE,为每个前缀和 Query 生成层次化的语义ID。这保证了语义相近的查询会被编码到相同的簇中。对于任何用户输入的前缀,系统可以快速匹配到与其语义ID最接近的 top-K 个相关查询,作为增强上下文输入后续的生成模型。
2.2 统一的编码器-解码器生成架构
OneSug 的生成架构基于编码器-解码器结构,直接通过自回归方式生成用户最有可能点击的 Query。
模型的输入包含四个关键部分:
- 用户当前输入前缀
- 由表征增强模块生成的相关查询序列
- 用户历史行为序列
- 用户画像信息
输出即为模型生成的 Query 列表。这种端到端的 大语言模型 生成方式,直接绕过了传统多阶段系统的复杂管道。
2.3 用户行为偏好对齐
为了让模型生成的查询更符合用户的真实偏好,OneSug 引入了基于奖励加权排序的用户偏好对齐方法。
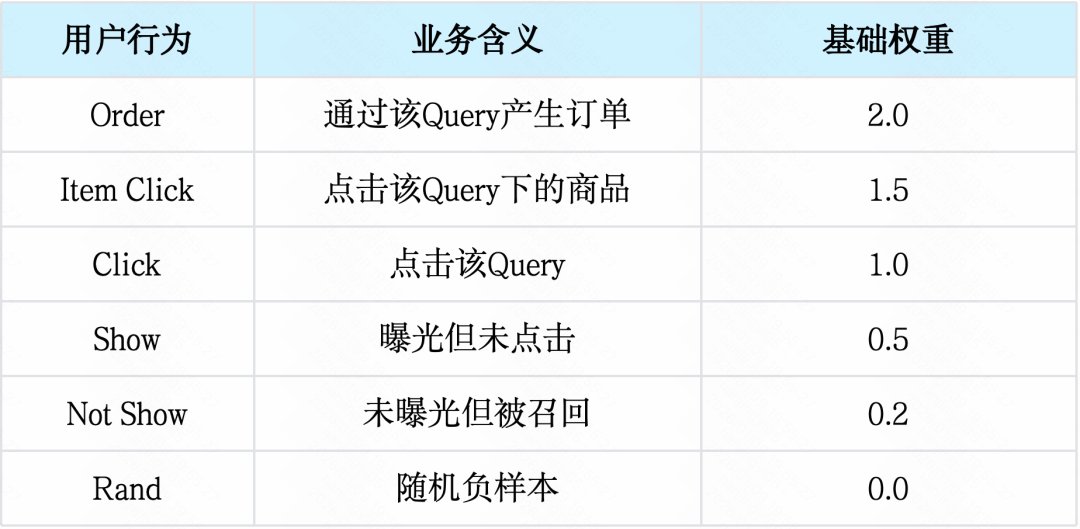
2.3.1 用户偏好量化
首先,对用户在搜索场景下的真实行为进行了精细化分级,划分为六个明确层次,并为每个层级赋予基础奖励权重。
2.3.2 奖励加权偏好优化
传统偏好对齐方法默认正负样本同等重要,这在业务场景中不尽合理。OneSug 提出的奖励加权排序核心思想是:根据正负样本之间的奖励差距,为不同的样本对赋予不同的学习权重。
我们构建了九种类型的样本对。对于每一对样本,计算其奖励差异权重 _rwΔ:
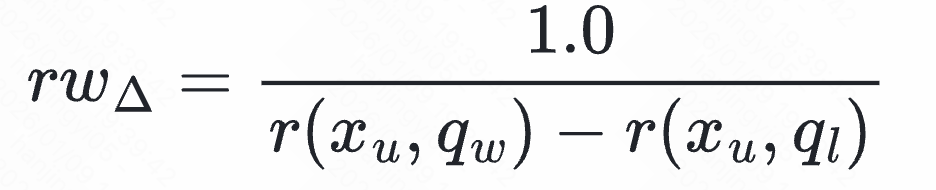
- _rwΔ 值小:说明正负样本奖励差距大(如<点击,随机负样本>),是“容易样本”。
- _rwΔ 值大:说明正负样本奖励差距小(如<点击,曝光>),是“困难样本”,RWR 会赋予更大的权重,迫使模型更努力地学习其间微妙的偏好差异。
2.3.3 混合排序框架
为了克服传统Pairwise范式的局限性,OneSug引入了一种混合排序框架,将listwise范式的排序损失和point-wise范式的监督微调损失相结合。这使得模型既能获得高效的全局排序能力,同时避免奖励黑客行为造成的生成能力下降。
受 Plackett-Luce 模型启发,我们设计了 Listwise 排序损失。对于正样本,让模型同时拉大它与所有负样本的奖励差距,迫使模型直接优化列表的整体排序质量。这是一种更先进的 算法优化 思路。
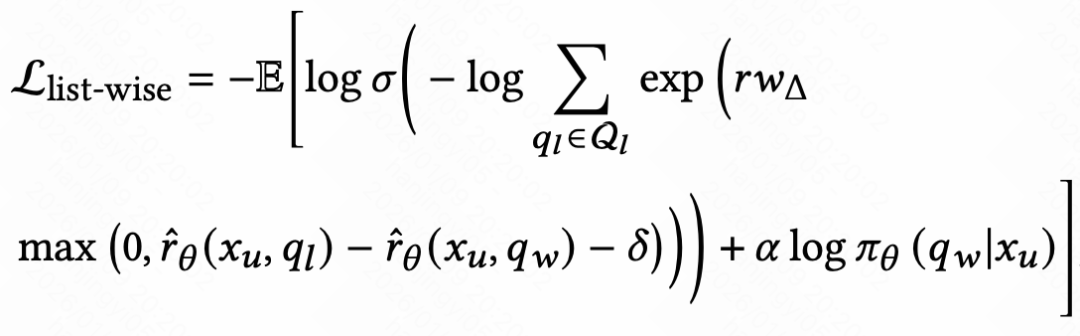
三、实验结果
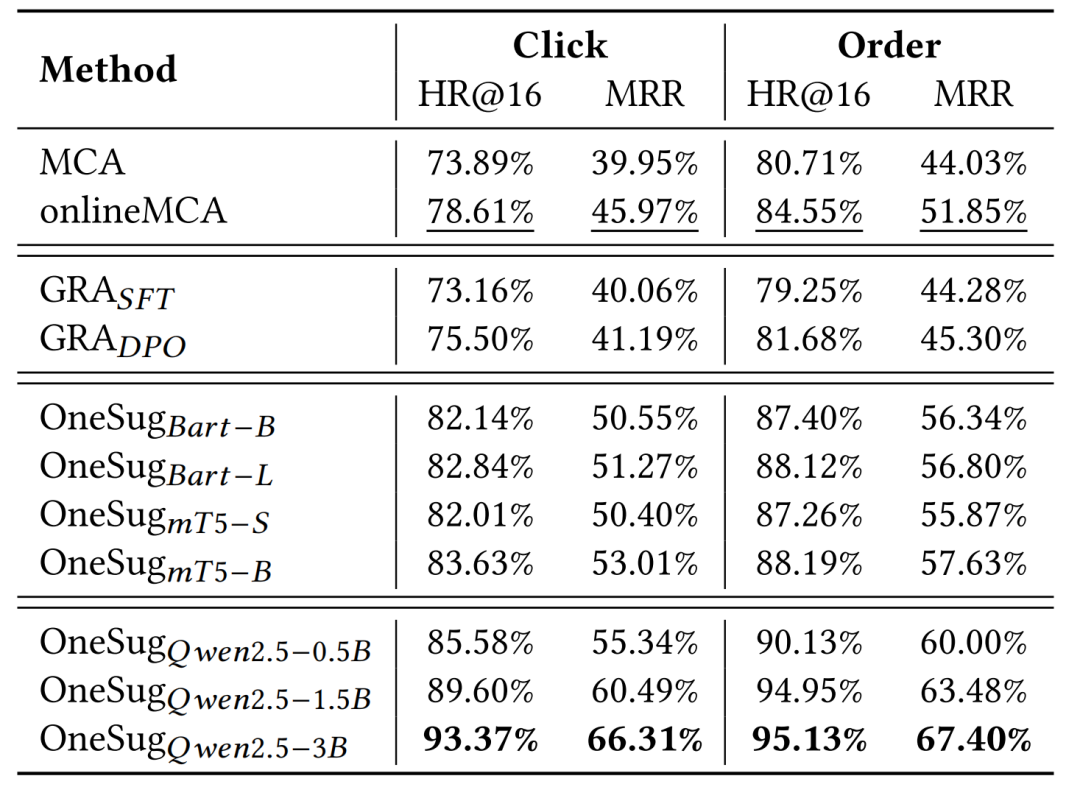
3.1 离线效果
在快手电商场景的大规模数据集上,OneSug 在 HR@16 和 MRR 指标上均显著优于传统多阶段系统与生成式基线模型。实验表明,OneSug不仅适用于编码器-解码器结构的模型,Decoder-only架构的模型(如 Qwen2.5)同样适用,且能取得更高的离线指标。
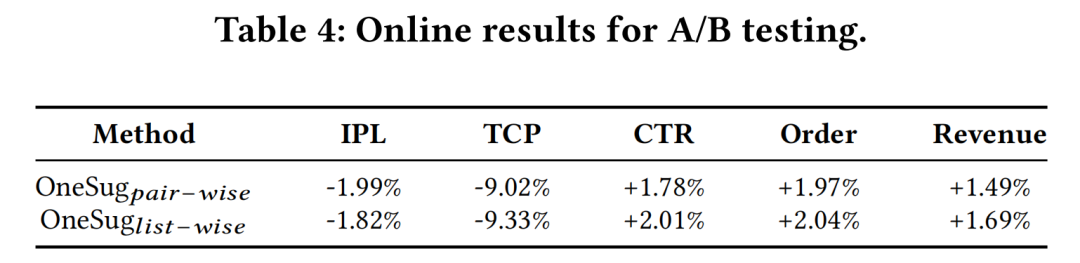
3.2 在线A/B测试
OneSug 模型在快手电商搜索场景下已全量上线。A/B 实验结果显示,该模型大幅提升了点击率、订单量和GMV等核心业务指标,同时人工评测的查询相关性等指标也有显著提升。
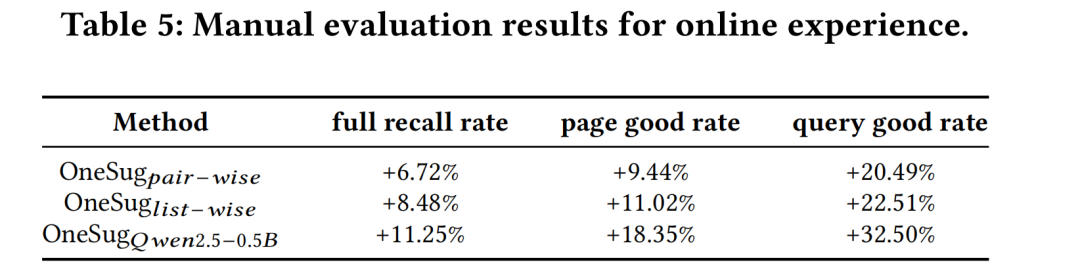
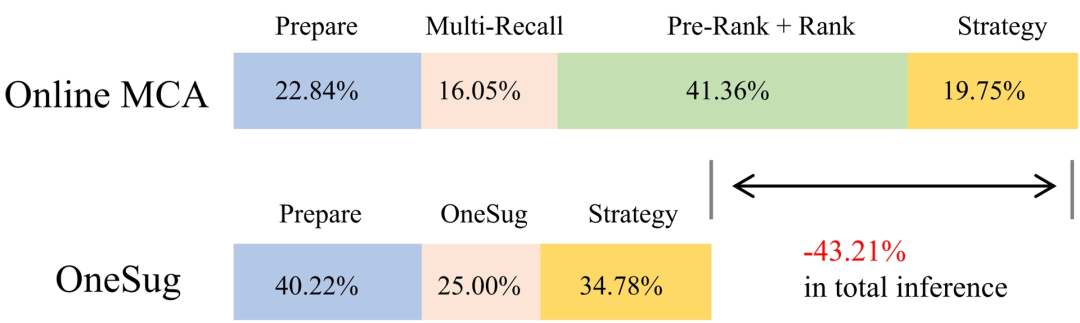
3.3 在线推理性能
在线服务流程中,OneSug 完全取代了传统的召回-粗排-精排多阶段链路。数据显示,其平均推理耗时相比旧系统降低了 43.2%,为后续模型迭代和效果优化提供了充足的计算资源空间。
四、总结与展望
OneSug 是业界首个在电商场景中实现全流量部署的端到端生成式查询推荐系统。其统一的建模方式显著提升了语义理解与个性化推荐的能力,为生成式模型在搜索、推荐、广告等领域的落地提供了新的技术范式。
未来,团队将进一步探索大语言模型在排序阶段的强化学习优化、模型实时更新等方向,持续推动端到端生成式系统在更广泛业务场景中的应用。这项研究也展示了将前沿学术成果(如 开源实战 中的大模型)与工业级海量数据深度融合的巨大潜力。
想了解更多类似的 AI 与搜索技术前沿动态,欢迎关注 云栈社区 ,一个专注于开发者成长与技术交流的平台。
 发表于 2026-1-20 10:30:05
|
查看: 169|
回复: 0
发表于 2026-1-20 10:30:05
|
查看: 169|
回复: 0
