在分布式系统架构中,消息队列(MQ)承担着解耦、异步和削峰填谷的重任。然而,线上环境复杂多变,消息丢失问题时常让开发者头疼不已。排查起来犹如大海捞针,不仅影响业务,更消耗心力。今天,我们就深入探讨如何从技术层面系统性解决MQ消息丢失问题。
一、消息丢失的三大环节
在寻找解决方案之前,我们必须先搞清楚:消息到底会在哪些环节丢失?只有定位问题根源,才能对症下药。
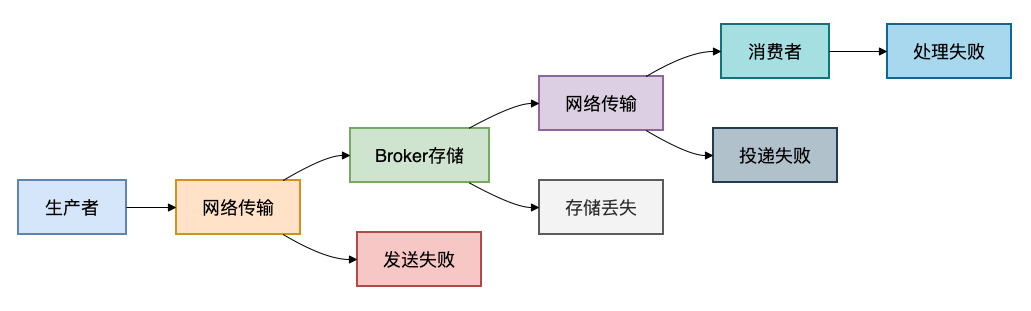
1. 生产者发送阶段
这是消息旅程的起点,也是最容易出问题的环节之一:
- 网络抖动导致发送失败:生产者和Broker之间的网络不稳定,消息未能成功送达。
- 生产者宕机未发送:业务处理完成,但发送消息前生产者实例发生故障。
- Broker处理失败未返回确认:Broker虽然收到了消息,但因内部错误(如存储失败)未能正确处理,也未给生产者返回成功确认。
2. Broker存储阶段
消息成功抵达消息代理服务器后,仍面临存储风险:
- 内存消息未持久化,重启丢失:如果消息仅存储在内存中,Broker重启或崩溃将导致数据清空。
- 磁盘故障导致数据丢失:即便配置了持久化,磁盘损坏也可能造成数据丢失(通常需要依赖磁盘RAID或集群复制来解决)。
- 集群切换时消息丢失:在主从切换或集群脑裂等异常场景下,未同步的消息可能丢失。
3. 消费者处理阶段
消息被投递给消费者后,考验才刚刚开始:
- 自动确认模式下处理异常:消费者设置为自动确认(Auto Ack),消息一旦被接收,无论业务处理是否成功,Broker都会立即删除该消息。若后续处理失败,则消息实质丢失。
- 消费者宕机处理中断:消费者在处理消息过程中突然宕机。
- 手动确认但忘记确认:采用了手动确认模式,但代码逻辑缺陷导致在某些异常路径下未发送确认(ACK)或否认(NACK)信号。
理解了这三个核心风险点,我们就可以构建一套从发送、存储到消费的完整防护体系。下面介绍五种经过实战检验的解决方案。
二、方案一:生产者确认机制
核心原理
生产者发送消息后,并不立即认为发送成功,而是同步或异步等待Broker返回的确认(ACK)信号。只有收到确认,才认为消息已稳妥抵达Broker。这是防止消息在“第一公里”丢失的第一道也是最重要的防线。
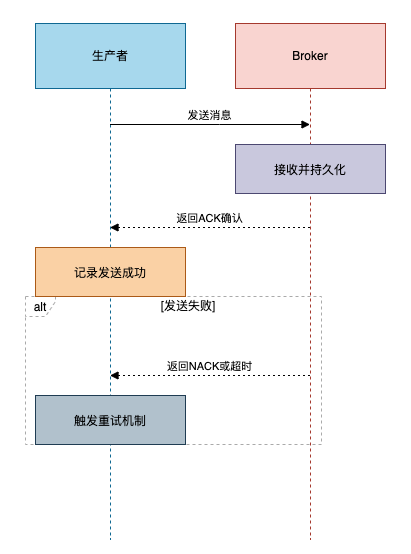
关键实现
以RabbitMQ为例,可以通过设置ConfirmCallback来实现异步确认。
// RabbitMQ生产者确认配置
@Bean
public RabbitTemplate rabbitTemplate() {
RabbitTemplate template = new RabbitTemplate(connectionFactory);
template.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
// 消息成功到达Broker
messageStatusService.markConfirmed(correlationData.getId());
} else {
// 发送失败,触发重试
retryService.scheduleRetry(correlationData.getId());
}
});
return template;
}
// 可靠发送方法
public void sendReliable(String exchange, String routingKey, Object message) {
String messageId = generateId();
// 先落库保存发送状态
messageStatusService.saveSendingStatus(messageId, message);
// 发送持久化消息
rabbitTemplate.convertAndSend(exchange, routingKey, message, msg -> {
msg.getMessageProperties().setDeliveryMode(MessageDeliveryMode.PERSISTENT);
msg.getMessageProperties().setMessageId(messageId);
return msg;
}, new CorrelationData(messageId));
}
对于高吞吐场景,Kafka生产者可通过配置 acks=all 来确保消息被所有ISR副本确认,这也是实现高可靠消息队列发送的关键配置。
适用场景
- 对消息可靠性要求极高的业务,如支付通知、订单状态同步。
- 需要精确知晓消息发送结果,以便进行后续补偿或记录日志的场景。
三、方案二:消息持久化机制
核心原理
将消息和元数据(队列、交换机)保存到非易失性存储(如磁盘),而非仅仅存放在内存中。这样即使Broker进程重启或服务器宕机,恢复后也能从磁盘加载消息,确保数据不丢。这是防御Broker端风险的核心手段。
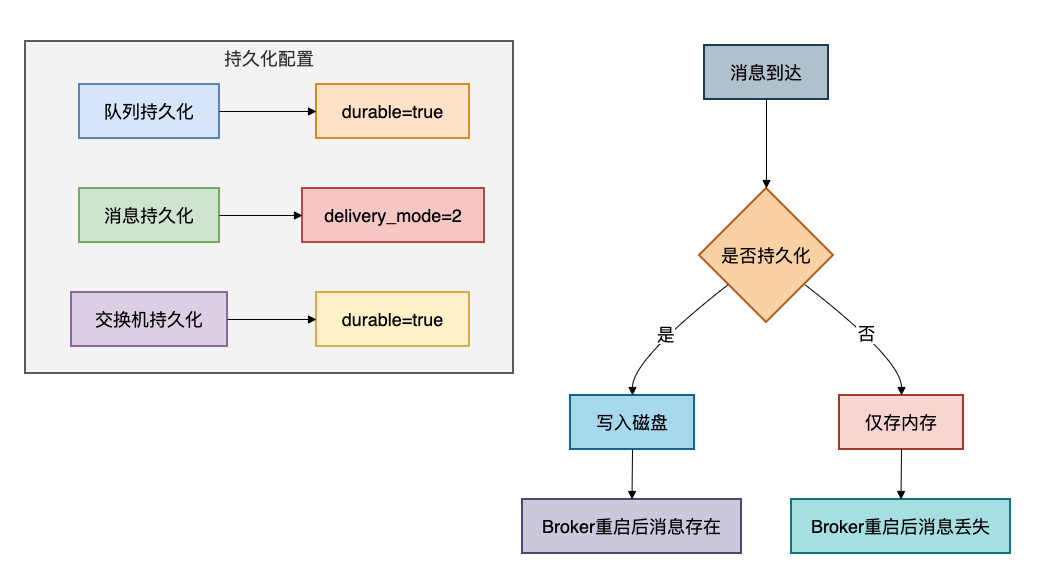
关键实现
持久化需要队列、消息、交换机三管齐下。
// 持久化队列配置
@Bean
public Queue orderQueue() {
return QueueBuilder.durable("order.queue") // 队列持久化
.deadLetterExchange("order.dlx") // 死信交换机
.build();
}
// 发送持久化消息
public void sendPersistentMessage(Object message) {
rabbitTemplate.convertAndSend("order.exchange", "order.create", message, msg -> {
msg.getMessageProperties().setDeliveryMode(MessageDeliveryMode.PERSISTENT); // 消息持久化
return msg;
});
}
// Kafka持久化配置
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.ACKS_CONFIG, "all"); // 所有副本确认
props.put(ProducerConfig.RETRIES_CONFIG, 3); // 重试次数
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); // 幂等性
return new DefaultKafkaProducerFactory<>(props);
}
优缺点
优点:
- 能有效防止因Broker重启或崩溃导致的消息丢失。
- 配置相对简单,效果立竿见影。
缺点:
- 磁盘IO操作会显著影响消息吞吐性能。
- 需要确保有足够的、可靠的磁盘空间。
四、方案三:消费者确认机制
核心原理
消费者在成功处理完一条消息的业务逻辑后,再手动向Broker发送一个确认(ACK)信号。Broker只有在收到这个确认后,才会将消息从队列中标记为已删除或移出。如果消费者处理失败或未发送确认,Broker会在一定时间后将消息重新投递给其他消费者。这是保证消息“被成功消费”的最后一道关卡。
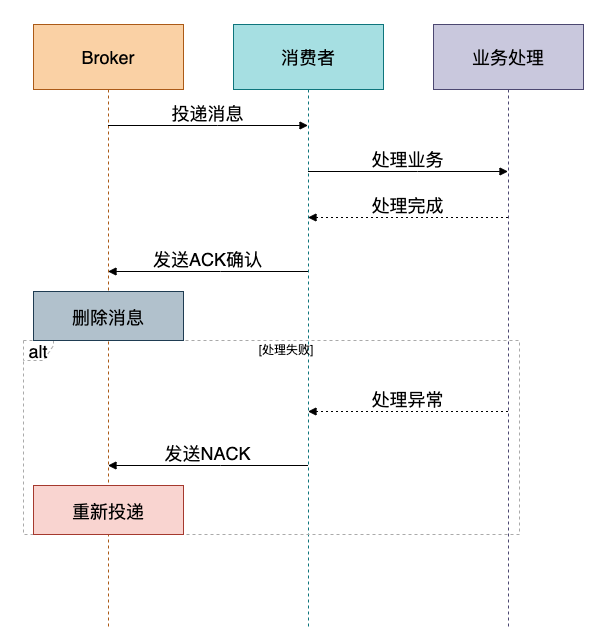
关键实现
务必关闭自动确认,改为手动确认模式。
// 手动确认消费者
@RabbitListener(queues = "order.queue")
public void handleMessage(Order order, Message message, Channel channel) {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
// 业务处理
orderService.processOrder(order);
// 手动确认
channel.basicAck(deliveryTag, false);
log.info("消息处理完成: {}", order.getOrderId());
} catch (Exception e) {
log.error("消息处理失败: {}", order.getOrderId(), e);
// 处理失败,重新入队
channel.basicNack(deliveryTag, false, true);
}
}
// 消费者容器配置
@Bean
public SimpleRabbitListenerContainerFactory containerFactory() {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setAcknowledgeMode(AcknowledgeMode.MANUAL); // 手动确认
factory.setPrefetchCount(10); // 预取数量
factory.setConcurrentConsumers(3); // 并发消费者
return factory;
}
注意事项
- 确认时机:必须在业务逻辑稳定完成(如数据库事务提交后)再发送ACK。
- 预取数量(Prefetch):合理设置,避免一次拉取过多消息导致消费者内存溢出或宕机后大量消息未确认。
- 异常处理:区分临时性异常和永久性异常,使用
basicNack并选择是否重新入队(requeue)。
五、方案四:事务消息机制
核心原理
保证本地数据库事务与消息发送这两个操作的原子性:要么两者都成功,要么两者都失败。这解决了“本地事务成功,消息发送失败”或“消息发送成功,本地事务失败”导致的数据不一致问题。这是实现最终一致性的高级模式,常涉及分布式事务思想。
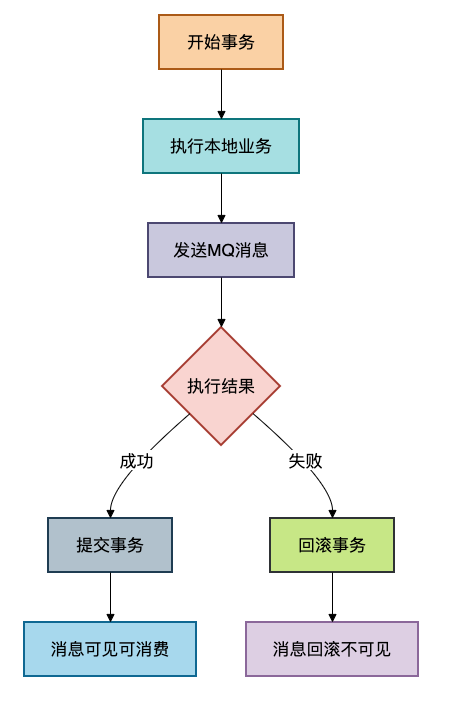
关键实现
方案1:本地消息表(经典解法)
// 本地事务表方案
@Transactional
public void createOrder(Order order) {
// 1. 保存订单到数据库
orderRepository.save(order);
// 2. 保存消息到本地消息表
LocalMessage localMessage = new LocalMessage();
localMessage.setBusinessId(order.getOrderId());
localMessage.setContent(JSON.toJSONString(order));
localMessage.setStatus(MessageStatus.PENDING);
localMessageRepository.save(localMessage);
// 3. 事务提交,本地业务和消息存储保持一致性
}
// 定时任务扫描并发送消息
@Scheduled(fixedDelay = 5000)
public void sendPendingMessages() {
List<LocalMessage> pendingMessages = localMessageRepository.findByStatus(MessageStatus.PENDING);
for (LocalMessage message : pendingMessages) {
try {
// 发送消息到MQ
rabbitTemplate.convertAndSend("order.exchange", "order.create", message.getContent());
// 更新消息状态为已发送
message.setStatus(MessageStatus.SENT);
localMessageRepository.save(message);
} catch (Exception e) {
log.error("发送消息失败: {}", message.getId(), e);
}
}
}
方案2:MQ原生事务消息(如RocketMQ)
// RocketMQ事务消息
public void sendTransactionMessage(Order order) {
TransactionMQProducer producer = new TransactionMQProducer("order_producer");
// 发送事务消息
Message msg = new Message("order_topic", "create",
JSON.toJSONBytes(order));
TransactionSendResult result = producer.sendMessageInTransaction(msg, null);
if (result.getLocalTransactionState() == LocalTransactionState.COMMIT_MESSAGE) {
log.info("事务消息提交成功");
}
}
适用场景
- 对业务数据和消息状态一致性有严格要求的场景,如:扣减库存后必须发送订单创建消息。
- 金融、电商等涉及资金和核心资产的业务。
六、方案五:消息重试与死信队列
核心原理
没有系统能保证100%一次成功。对于因网络抖动、依赖服务临时不可用等导致的可恢复的失败,引入重试机制。而对于重试多次仍失败或业务逻辑错误的不可恢复的失败,则将其转入一个特殊的队列——死信队列(DLQ),等待人工或特定程序处理。这构成了一个完善的高可用异常处理闭环。
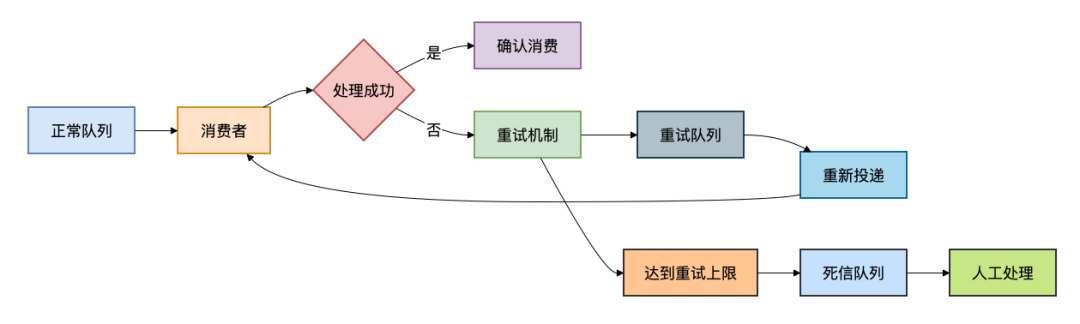
关键实现
// 重试队列配置(利用TTL和DLX实现延迟重试)
@Bean
public Queue orderQueue() {
return QueueBuilder.durable("order.queue")
.withArgument("x-dead-letter-exchange", "order.dlx") // 死信交换机
.withArgument("x-dead-letter-routing-key", "order.dead")
.withArgument("x-message-ttl", 60000) // 60秒后进入死信
.build();
}
// 死信队列配置
@Bean
public Queue orderDeadLetterQueue() {
return QueueBuilder.durable("order.dead.queue").build();
}
// 消费者重试逻辑
@RabbitListener(queues = "order.queue")
public void handleMessageWithRetry(Order order, Message message, Channel channel) {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
orderService.processOrder(order);
channel.basicAck(deliveryTag, false);
} catch (TemporaryException e) {
// 临时异常,重新入队重试
channel.basicNack(deliveryTag, false, true);
} catch (PermanentException e) {
// 永久异常,直接确认进入死信队列
channel.basicAck(deliveryTag, false);
log.error("消息进入死信队列: {}", order.getOrderId(), e);
}
}
// 死信队列消费者
@RabbitListener(queues = "order.dead.queue")
public void handleDeadLetterMessage(Order order) {
log.warn("处理死信消息: {}", order.getOrderId());
// 发送告警、记录日志、人工处理等
alertService.sendAlert("死信消息告警", order.toString());
}
重试策略建议
- 指数退避:避免密集重试加剧系统负担,例如:1s, 5s, 15s, 30s。
- 最大重试次数:通常3-5次,避免无限重试。
- 死信处理:必须有兜底措施,如告警通知、记录详细日志供人工排查。
七、方案对比与选型指南
没有一种方案是万能的,关键在于根据业务特征进行组合和取舍。下表对比了五种方案的核心特点:
| 方案 |
可靠性 |
性能影响 |
复杂度 |
适用场景 |
| 生产者确认 |
高 |
中 |
低 |
所有需要可靠发送的场景 |
| 消息持久化 |
中 |
中 |
低 |
Broker重启保护 |
| 消费者确认 |
高 |
低 |
中 |
确保消息被成功处理 |
| 事务消息 |
最高 |
高 |
高 |
强一致性要求的业务 |
| 重试+死信 |
高 |
低 |
中 |
处理临时故障和最终死信 |
选型建议
- 初创项目 / 简单业务:
- 组合:生产者确认 + 消息持久化 + 消费者确认。
- 理由:实现简单,能覆盖绝大多数风险,满足大部分业务对可靠性的要求。
- 电商 / 交易系统:
- 组合:生产者确认 + 事务消息 + 重试机制。
- 理由:在保证数据强一致性的前提下,通过重试应对瞬时故障,确保核心链路稳固。
- 大数据 / 日志处理:
- 组合:消息持久化 + 消费者确认。
- 理由:允许极少量数据丢失,优先保障高吞吐量和实时性。
- 金融 / 支付系统:
- 组合:全方案组合使用。
- 理由:对可靠性要求达到极致,不惜以性能和复杂度为代价,确保资金数据万无一失。
总结
消息丢失是消息队列应用中无法回避的挑战,但通过系统性的方案设计,我们可以将风险控制在可接受的范围内。本文梳理的五大方案,构建了一个从生产到消费的立体防护网:
- 生产者确认机制 - 守好入口,确保消息成功抵达Broker。
- 消息持久化机制 - 稳驻中间,抵御Broker自身故障风险。
- 消费者确认机制 - 把牢出口,保证消息被业务成功消化。
- 事务消息机制 - 保障一致,解决业务与消息的原子性问题。
- 重试与死信队列 - 完善善后,为异常处理提供标准路径。
你可能想问:“我的项目是否需要用到所有方案?” 答案是:按需组合,平衡取舍。对于核心业务链路,建议至少采用“生产者确认+持久化+消费者确认”的铁三角组合。对于普通通知类业务,可以适当简化。
技术方案的选型,本质上是业务需求、系统性能、开发运维复杂度之间的权衡。希望这篇文章能帮助你构建更健壮、更可靠的消息系统。如果你想了解更多关于RabbitMQ或其他中间件的深度实践,欢迎来到云栈社区与更多开发者交流探讨。
 发表于 2026-1-20 15:10:02
|
查看: 320|
回复: 0
发表于 2026-1-20 15:10:02
|
查看: 320|
回复: 0
