在做直播实时翻译或同声传译时,你是否感到传统离线翻译模型的延迟难以忍受?它们通常需要等整句话说完才能开始翻译,造成明显的滞后感。
最近在 GitHub 上发现一个名为 NoLanguageLeftWaiting 的开源项目,它巧妙地将 Meta 的 NLLB 离线翻译模型改造为实时同传模型。这个项目能够实现边听边译,无需等待完整句子,同时解决了传统模型在处理句尾标记、标点插入以及前缀一致性等方面的诸多问题。它支持高达 200 种语言的互译,并提供了 HuggingFace transformers 和 Ctranslate2 两种后端选择,内置了 600M 和 1.3B 两种模型规格以供灵活选用。
目前,该项目正在开发推测解码功能,通过部分验证机制有望进一步提升翻译速度,根据早期实验,验证过程耗时仅约 0.15 秒。如果你正在开发语音翻译、直播字幕或跨语言会议等对低延迟有严格要求的应用,那么这个项目值得深入探索。
项目简介
该项目核心是将 NoLanguageLeftBehind (NLLB) 翻译模型转换为 SimulMT(同步机器翻译)模型,专门针对实时/流式使用场景进行优化。
传统的离线模型(如 NLLB)存在句尾标记和标点符号插入时机问题、前缀处理不一致,以及随着输入长度增加导致计算开销显著增长等问题。本项目的实现旨在有效解决这些痛点。
其主要特性包括:
- LocalAgreement 策略:用于确定稳定、可输出的翻译前缀。
- 后端支持:兼容 HuggingFace transformers 及 Ctranslate2 Translator。
- 生态集成:专为 WhisperLiveKit 项目构建,便于与语音识别链路结合。
- 多语言支持:覆盖 200 种语言,完整列表可查看项目内的 supported_languages.md 文件。
- 前瞻性功能:正在实现推测/自推测解码以加速解码过程,计划使用 600M 模型作为草稿模型,1.3B 模型作为主验证模型。
安装
通过 pip 即可快速安装:
pip install nllw
默认安装不包含文本前端界面。
快速开始
- 运行演示界面:
python textual_interface.py
-
作为 Python 包使用:
import nllw
model = nllw.load_model(
src_langs=["fra_Latn"],
nllb_backend="transformers",
nllb_size="600M" # 可选: 1.3B
)
translator = nllw.OnlineTranslation(
model,
input_languages=["fra_Latn"],
output_languages=["eng_Latn"]
)
tokens = [nllw.timed_text.TimedText('Ceci est un test de traduction')]
translator.insert_tokens(tokens)
validated, buffer = translator.process()
print(f"{validated} | {buffer}")
tokens = [nllw.timed_text.TimedText('en temps réel')]
translator.insert_tokens(tokens)
validated, buffer = translator.process()
print(f"{validated} | {buffer}")
进行中的工作:部分投机解码
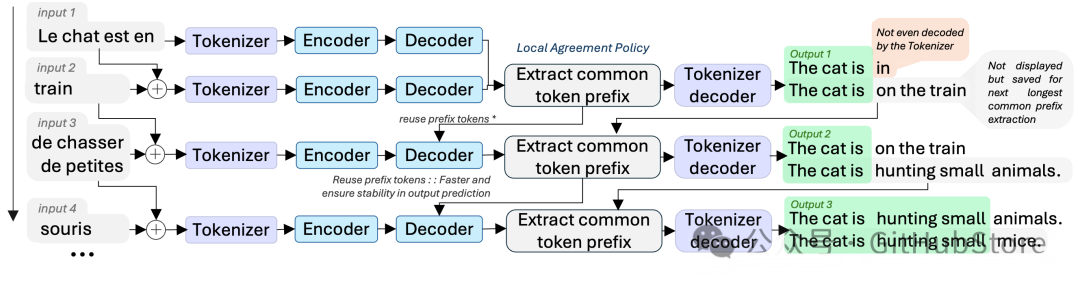
由于 Local Agreement 策略已经为已提交的翻译锁定了稳定的前缀,因此无法直接采用标准的自投机解码方案。项目正在开发的原型创新性地仅对需要由更大模型验证的新标记应用投机思想。
在 speculative_decoding_v0.py 中测试的流程如下:
- 草稿生成:首先运行 600M 草稿解码器,获得候选续接标记及其对应的缓存。
- 部分验证:然后使用 1.3B 主模型对草稿标记进行重放验证,但一旦主模型生成的标记与草稿输出标记匹配,就立即停止前向传播。保留这些已验证的标记,并仅从该匹配点继续后续的生成。
- 恢复机制:当出现不匹配时,并非丢弃整个草稿段,而是使用 1.3B 模型恢复完整解码,直到再次达到标记匹配状态。
这种“部分验证”机制减少了大模型在每次预测分歧后所需执行的工作量,同时保持了草稿模型的快速响应优势。来自 speculative_decoding_v0.py 的早期计时实验表明,验证过程(在示例中耗时约 0.15 秒)相比每次都重新计算完整解码步骤要经济得多。

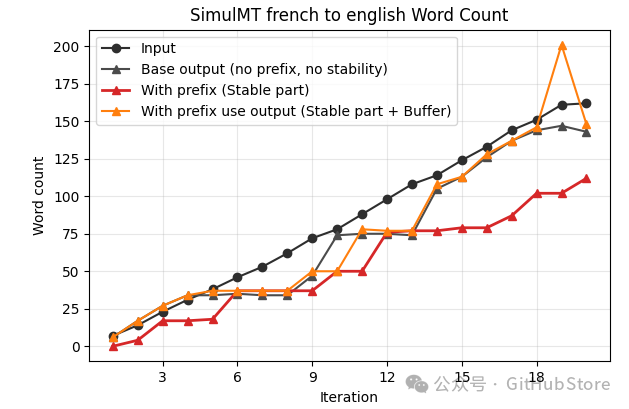
输入与输出长度
该项目成功保持了输出文本的连贯性和长度,即便稳定的输出前缀是逐渐累积生成的。
项目地址
如果你想深入了解或参与这个有趣的 开源实战 项目,可以访问其 GitHub 主页:https://github.com/QuentinFuxa/NoLanguageLeftWaiting/blob/main/README.md。
参考资料
[1] NoLanguageLeftBehind: https://arxiv.org/abs/2207.04672
[2] LocalAgreement 策略: https://www.isca-archive.org/interspeech_2020/liu20s_interspeech.pdf
[3] HuggingFace transformers: https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForSeq2SeqLM
[4] Ctranslate2 Translator: https://opennmt.net/CTranslate2/python/ctranslate2.Translator.html#ctranslate2.Translator.translate_batch
[5] WhisperLiveKit: https://github.com/QuentinFuxa/WhisperLiveKit
[6] supported_languages.md: supported_languages.md
[7] 用于更快实时翻译的自投机偏向解码: https://arxiv.org/html/2509.21740v1 |  发表于 2026-1-20 15:14:12
|
查看: 444|
回复: 0
发表于 2026-1-20 15:14:12
|
查看: 444|
回复: 0
